python可视化之seaborn
数据可视化的文章我很久之前就打算写了,因为最近用Python做项目比较多,于是就花时间读了seaborn的文档,写下了这篇。
数据可视化在数据挖掘中是一个很重要的部分,将数据用图表形式展示可以很直观地看到数据集的特点(比如正态分布,长尾分布,聚集等),方便下一步怎么对数据进行处理。
这里我用的是Python来进行可视化,因为Python的框架相对较多而且使用的也较广泛。我们在这里用的是seaborn框架,它是一个广受欢迎的可视化框架,提到seaborn不得不提到的还有matplotlib,matplotlib是一个强大的科学绘图包,里面集成了大量可视化图表,但是参数比较多,使用起来比较繁琐,而seaborn对这方面做了优化,不过seaborn不是matplotlib的一个替代,而是一个补充。它们的官网分别如下:
至于seaborn可以画哪些图,在seaborn的官网上有一个gallery,专门展示它的图表示例。
这篇是手把手教程,所谓手把手教程,就是你可以跟着这篇文章,一步步进行操作,同时也建议你在看的时候,打开jupyter notebook一起写一下,这样印象更深刻。
话不多说,现在开始。
准备工作
阅读这篇文章之前你需要知道:
- Python的语法,熟悉程度大概是把菜鸟教程里面的基础教程跟着敲一遍就行。
- jupyter notebook的基本操作,比如新建notebook。
环境:Windows 10,Python 3.6.5,anaconda 4.3.30(anaconda已经集成了 jupyter notebook以及相关的数据可视化包) matplotlib 2.2.2, seaborn 0.9.0
(如果你的seaborn没有折线图,可能是版本太低了,更新到0.9.0就可以了)
如果需要安装Python,直接到官网下载安装即可,教程有很多。如果需要安装anaconda,这里有一篇较好的教程。
数据集:seaborn很贴心的准备了一些数据集,自带的,我们只需要使用sns.load_dataset()方法就可以获取了,想要知道seaborn有什么数据集,可以看这里,或者使用sns.get_dataset_names()方法
首先,打开我们的jupyter notebook,新建一个notebook,名字叫data_visualization,导入相应的包
%matplotlib inline
import seaborn as sns
import matplotlib.pyplot as plt如果在jupyter notebook中显示matplotlib图像,那么就要加上这一句 ‘%matplotlib inline’,否则只能输出一个对象的描述信息。
基础绘图
seaborn一共有5个大类21种图,分别是:
- Relational plots 关系类图表
- relplot() 关系类图表的接口,其实是下面两种图的集成,通过指定kind参数可以画出下面的两种图
- scatterplot() 散点图
- lineplot() 折线图
- Categorical plots 分类图表
- catplot() 分类图表的接口,其实是下面八种图表的集成,,通过指定kind参数可以画出下面的八种图
- stripplot() 分类散点图
- swarmplot() 能够显示分布密度的分类散点图
- boxplot() 箱图
- violinplot() 小提琴图
- boxenplot() 增强箱图
- pointplot() 点图
- barplot() 条形图
- countplot() 计数图
- Distribution plot 分布图
- jointplot() 双变量关系图
- pairplot() 变量关系组图
- distplot() 直方图,质量估计图
- kdeplot() 核函数密度估计图
- rugplot() 将数组中的数据点绘制为轴上的数据
- Regression plots 回归图
- lmplot() 回归模型图
- regplot() 线性回归图
- residplot() 线性回归残差图
- Matrix plots 矩阵图
- heatmap() 热力图
- clustermap() 聚集图
同一大类下的图使用方法都类似,下面我们每个大类都画一张图来熟悉下。
关系类图表之 scatterplot() 散点图
我们使用diamonds数据集,这是一个钻石信息的数据,先来通过散点图来看看钻石的重量(carat)和价格之间的关系
sns.scatterplot(x='carat',y='price',data=sns.load_dataset('diamonds'));
data=sns.load_dataset(‘diamonds’)加载自带的数据集,通过x=’carat’和y=’price’指定data数据集中名为’carat’和’price’的列作为横轴和纵轴的变量进行绘图,这是最简单的形式。
这里有一个小技巧,如果在代码的最后一句加上一个分号,输出的图片就不会显示图片对象的描述信息。
散点图是指在回归分析中,数据点在直角坐标系平面上的分布图,散点图表示y变量随x变量而变化的大致趋势,如果点的分布形成一条’/’状的斜线,说明x与y之间有正相关关系,如果是’\’状则有负相关关系,如果都不是则两个变量不相关。
分类图表之 violinplot() 小提琴图
我们仍然使用diamonds数据集,看一看在不同的切割水平下价格的分布
sns.violinplot(x='cut',y='price',data=sns.load_dataset('diamonds'));
仍然只需要指定x,y,data三个参数就可以画出一幅基本的小提琴图。关于小提琴图的解释,这里有篇博客就写的很好:
小提琴图其实是箱线图与核密度图的结合,箱线图展示了分位数的位置,小提琴图则展示了任意位置的密度,通过小提琴图可以知道哪些位置的密度较高。在图中,白点是中位数,黑色盒型的范围是下四分位点到上四分位点,细黑线表示须。外部形状即为核密度估计(在概率论中用来估计未知的密度函数,属于非参数检验方法之一)。
分布图之 kdeplot() 核函数密度估计图
这回我们使用anscombe数据集
dataset=sns.load_dataset('anscombe')
sns.kdeplot(data=dataset.x,data2=dataset.y,shade=True);
这个函数的使用方式稍微有点不一样,data和data2分别传入一维的矩阵,在这里我们获取anscombe数据集之后,分别传入它的x列和y列,shade指定是否对等高线进行填充。
回归图之lmplot() 回归模型图
我们使用car_crashes这个数据集,看一看司机的酒精度(alcohol)跟not_distracted之间的关系
sns.lmplot(x='alcohol',y='not_distracted',data=sns.load_dataset('car_crashes'));
除了将数据点画在图上之外还会进行回归计算,划出一条拟合曲线,回归的方法除了线性回归之外还有多项式回归,局部加权线性回归等。
矩阵图之 heatmap()热力图
热力图一般用来展示协方差矩阵,可以直观地看到各个变量之间的相关系数,这里我们使用diamonds数据集,来看看他们的协方差矩阵热力图
sns.heatmap(data=sns.load_dataset('diamonds').corr());
使用时直接传入一个二维矩阵,如果dataset是一个dataframe格式的数据集,使用dataset.corr()方法可以得到一个协方差矩阵
参数进阶
经过上面几个小demo,你会发现画图基本上一句代码就可以搞定,但这只是最基本的用法,当你有了更多需求之后,还要用到其他的参数。这里列举几个常用的来解释一下。
hue 分组画图
hue是设置分组画图,所谓分组画图,就是对数据集根据某个属性进行分组,然后每个分组单独画图。举个例子,如果我们要画手环用户一个月里每天的步数变化图,那么将上班族和肥宅分别画图会有明显的区别。
用法是传入dataframe的一个列名,seaborn就会根据这一列里面每个值都分别画图
我们用Titanic数据集来看看,我们想知道不同社会等级(pclass)中船费(fare)的平均值是多少,这其中幸存的人和不幸的人又有多少
sns.barplot(x='pclass',y='fare',hue='survived',data=sns.load_dataset('titanic'));
我们可以看出,社会等级越高,船费就越贵,能活下来的比例也多一些
再来一张图,这个就更加明显了
sns.lineplot(x='time',y='firing_rate',hue='align',data=sns.load_dataset('dots'));
col/row 分列/分行画图
这个参数跟hue一样,都是设置分组画图的,不同之处是hue的分组仍然在同一张图中,col参数会将每个分组画在一行的多个列中,row参数会将每个分组画在一列的多个行中。
sns.relplot(x='subject',y='score',data=sns.load_dataset('attention'),col='solutions');
estimator 估计函数
如果一个x变量对应多个y值,在画统计类图表(条形图,折线图等)的时候就要考虑怎么将多个y值变成一个值了,使用estimator参数可以指定计算的方式,通常是一个可调用的函数(callable),可以是numpy.max,numpy.min,numpy.median,mean,sum,max,min等
f=plt.figure(figsize=(8,15))
sns.lineplot(x='subject',y='score',data=dataset_line,estimator=max,ax=plt.subplot(3,1,1));
sns.lineplot(x='subject',y='score',data=dataset_line,estimator=min,ax=plt.subplot(3,1,2));
sns.lineplot(x='subject',y='score',data=dataset_line,estimator=sum,ax=plt.subplot(3,1,3));
plt.show()
order,hue_order,style_order,col_order,row_order 指定顺序
order和带有_order的,都是用来指定顺序的,order指定显示在x轴的变量的顺序,传入一个list,里面是x轴的所有值,一般作用于x值为离散值的图表
color_order=['D','E','F','G','H','I','J']
sns.countplot(x='color',order=color_order,data=sns.load_dataset('diamonds'));
markers,style,size,sizes 样式
markers和style都是对图表样式的设置,对于不同分组的数据,可以用不同的形式来加以区分。size是设置数据点的大小,多用于散点图,sizes指定了大小的范围。
style传入的是dataframe的一个列名,则会根据这一列的每个值进行分组,然后每个组使用不同的样式绘图。
markers使用时传入一个列表,里面是点样式的表示,有如’x’,’o’,’^’等等,也可以传入一个字典,指定style参数里面的每个值对应什么marker。
size传入dataframe的一个列名,根据这一列的每个值分组排序,每个值对应一个大小。
sizes指定size的范围,传入一个元组(a,b),分别代表最小的size和最大的size。
sns.scatterplot(x='total_bill',y='tip',data=sns.load_dataset('tips'),style='smoker');
sns.scatterplot(x='total_bill',y='tip',data=sns.load_dataset('tips'),style='smoker',markers={'Yes':'^','No':'o'});
sns.scatterplot(x='total_bill',y='tip',data=sns.load_dataset('tips'),size='size',sizes=(10,100));
kind 指定画图函数
仅对relplot()和catplot()有用,因为这两种图分别集成了关系类图表和分类图表的其他所有图,通过kind来指定使用具体哪种图,很方便。
关系类图表包括
- scatterplot() 散点图,当指定kind=’scatter’的时候(默认)
- lineplot() 折线图,当指定kind=’line’的时候
分类图表包括:
- 分类散点图
- stripplot() 散点图 (kind=’strip’)(默认)
- swarmplot() 散点图(能够显示密度分布,看着像小提琴图)(kind=’swarm’)
- 分类分布图
- boxplot() 箱图 (kind=’box’)
- violinplot() 小提琴图 (kind=’violin’)
- boxenplot() 增强型箱图 (kind=’boxen’)
- 分类估计图
- pointplot() 点图 (kind=’point’)
- barplot() 条形图 (kind=’bar’)
- countplot() 计数图(kind=’count’)
sns.catplot(x='total_bill',y='day',kind='violin',hue='smoker',split=True,palette='pastel',data=sns.load_dataset('tips'));
sns.catplot(x='total_bill',y='day',kind='swarm',hue='smoker',palette='pastel',data=sns.load_dataset('tips'));
ax 指定画图区域
ax是axe的简称,这个要涉及到matplotlib的绘图区域的概念,在matplotlib中,首先是有一张纸(figure),然后将纸分成一块一块区域(axes),图就是画在区域上的。
ax接受的参数是matplotlib Axes对象,可以通过plt.subplots()来获得ax句柄
f,axes=plt.subplots(nrows=1,ncols=2,figsize=(12,5))
sns.kdeplot(data=sns.load_dataset('tips').total_bill,data2=sns.load_dataset('tips').tip,shade=True,ax=axes[0])
sns.lineplot(x='total_bill',y='tip',hue='time',estimator=sum,data=sns.load_dataset('tips'),ax=axes[1]);
图像美化
通过上面两节的内容,你可以画出一个符合需求的图片,但是如果想要美观一点,就需要多费点心思了
主题
使用set()和set_style()函数来设置主题,也就是背景
import seaborn as sns
sns.set() 恢复默认主题,默认的主题就挺好看的
还有其他几个主题,包括:
sns.set_style(“whitegrid”) # 白色网格背景
sns.set_style(“darkgrid”) # 灰色网格背景
sns.set_style(“dark”) # 灰色背景
sns.set_style(“white”) # 白色背景
sns.set_style(“ticks”) # 四周加边框和刻度
什么也不设置

sns.set() 默认主题

sns.set_style(“whitegrid”)

sns.set_style(“darkgrid”)

sns.set_style(“dark”)

sns.set_style(“white”)

sns.set_style(“ticks”)
配色 palette
通常配色的设置可以由两个方法:全局设置 sns.set_palette()与函数参数 palette
全局配色设置有如下:
sns.set_palette(“muted”) # 常用
sns.set_palette(“RdBu”)
sns.set_palette(“Blues_d”)
sns.set_palette(“Set1”)
sns.set_palette(“RdBu”)
sns.set()
sns.set_palette('muted')
sns.countplot(x='color',data=sns.load_dataset('diamonds'));
sns.set()
sns.set_palette('RdBu')
sns.countplot(x='color',data=sns.load_dataset('diamonds'));
sns.set()
sns.set_palette('Blues_d')
sns.countplot(x='color',data=sns.load_dataset('diamonds'));
sns.set()
sns.set_palette('Set1')
sns.countplot(x='color',data=sns.load_dataset('diamonds'));
sns.set()
sns.set_palette('husl')
sns.countplot(x='color',data=sns.load_dataset('diamonds'));
布局控制
图片大小使用figsize来控制
f=plt.figure(figsize=(8,4))
sns.countplot(x='color',data=sns.load_dataset('diamonds'));
前面说过,matplotlib画图的机制是先确定一张纸(figure),再确定绘图区域(axe),上面的代码确定了一张长为8,宽为4的纸张,没有显式指明画图区域,则画图区域就是整张纸,所以画出来的图就是长为8,宽为4的图像,注意,这里没有指定图要画在哪张纸上,这是因为matplotlib生成一张纸之后,也就指定了当前绘图将绘在这张纸上,会覆盖之前的figure
用plt.subplot(nrows,ncols)来创建绘图区域ax
你可以生成好几个ax然后用下标去访问每个ax:
f,axes=plt.subplots(nrows=1,ncols=2,figsize=(12,5))
sns.kdeplot(data=sns.load_dataset('tips').total_bill,data2=sns.load_dataset('tips').tip,shade=True,ax=axes[0])
sns.lineplot(x='total_bill',y='tip',hue='time',estimator=sum,data=sns.load_dataset('tips'),ax=axes[1]);
当生成的绘图区域是一个nrows>1,ncols>1的矩阵时,访问就可以变成ax[i][j]
你也可以在使用的时候再指定:
subplot(nrows,ncols,index),这里index就是指定第index个绘图区域
dataset_line=sns.load_dataset('attention')
f=plt.figure(figsize=(8,15))
sns.lineplot(x='subject',y='score',data=dataset_line,estimator=max,ax=plt.subplot(3,1,1));
sns.lineplot(x='subject',y='score',data=dataset_line,estimator=min,ax=plt.subplot(3,1,2));
sns.lineplot(x='subject',y='score',data=dataset_line,estimator=sum,ax=plt.subplot(3,1,3));
plt.show()
添加标题
只画一张图,使用plt.title()
sns.countplot(x='color',data=sns.load_dataset('diamonds'))
plt.title('diamonds');
画多张图,使用ax[i].set_title():
f,axes=plt.subplots(nrows=1,ncols=2,figsize=(12,5))
sns.kdeplot(data=sns.load_dataset('tips').total_bill,data2=sns.load_dataset('tips').tip,shade=True,ax=axes[0])
sns.lineplot(x='total_bill',y='tip',hue='time',estimator=sum,data=sns.load_dataset('tips'),ax=axes[1])
axes[0].set_title('tips_kdeplot')
axes[1].set_title('tips_lineplot');
这篇文章前前后后写了好几天,中间因为结构安排不合理重写了两次,同时也是为了大家能看得懂的同时学到更多的知识。其实写博客的好处是逼着你仔细的学,认真的总结,毕竟没有懂点内容写起博客也是十分空洞的,其实这也是提升自己技术的一个好方法。
如果大家有什么不懂之处或者发现错误之处,欢迎大家私信交流。
智能推荐

PYTHON数据可视化(四)seaborn
线性关系可视化 许多数据集都有着众多连续变量。数据分析的目的经常就是衡量变量之间的关系,我们之前介绍了可以绘制双变量分布的函数。然而,使用统计模型来估计两个噪声观测组之间的简单关系可能是非常有帮助的。我们在这一章中讨论的函数功能将在线性回归的框架实现。 请注意,seaborn并不是一个统计分析库,这里所做的回归仅仅是粗略的。其目的是在探索性数据分析时,提供快捷的可视化工具,便于人们了解变量间可能存...
Python数据可视化——Seaborn笔记
写在前面:只记录本人在Kaggle数据可视化课程学习过程中,Seaborn模块的常用方法及部分效果图笔记,数据类型不作介绍和处理 课程链接Kaggle数据可视化课程 文章目录 导入模块 数据可视化 1. 曲线图lineplot 2. 条形图(barplot) 3.热图(heatmap) 4.散点图(scatterplot) 4.1 普通散点图 4.2 回归线散点图 4.3 多变量特征散点图 4.4...
Python数据可视化--seaborn实例
seaborn 是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,在大多数情况下使用seaborn就能做出很具有吸引力的图。(也就是说plt和sns中会有很多方法是可以混用的)本博文中的数据集采用Kaggle中的compete:House Prices: Advanced Regression Techniques中train.csv。如果需要数据集在Kaggle中就...
Docker-Compose部署nginx 和lnmp
Docker-Compose tomcat lnmp tomcat 使用Docker-Compose部署Nginx代理Tomcat集群,实现负载均衡 在这个目录下创建多个目录 切换到nginx目录修改nginx的主配置文件: [root@host1 compose]# cd nginx/ [root@host1 nginx]# vim default.conf 在末尾添加: 修改: 切换到tmca...
猜你喜欢

19-20年月度行业分析
Table of Contents 1 对各一级行业分析 2 对女装行业进行分析 对各一级行业分析 platform cid industry category themonth 销售额 访客 客群指数 行业简称 月 年 年月 0 天猫 50010368 ZIPPO/瑞士军刀/眼镜 太阳眼镜 2020-01-01 62484514.13 6663217 ...

Python数据分析入门
博客原文:https://ouduidui.cn/blog/detail?blogId=5fcddf5c61ae700fd80190db 基础知识 数据的分类 数值型数据 表示大小或多少的数据 例子:年龄、年购买量 数值型数据分析方法 最小值和最大值:查看这两个值的目的是为了能够确定一组数据的上界和下界。 **平均值:**平均值可以反映一组数据的综合水平。 **中位数:**中位数和平均数一样都是用...
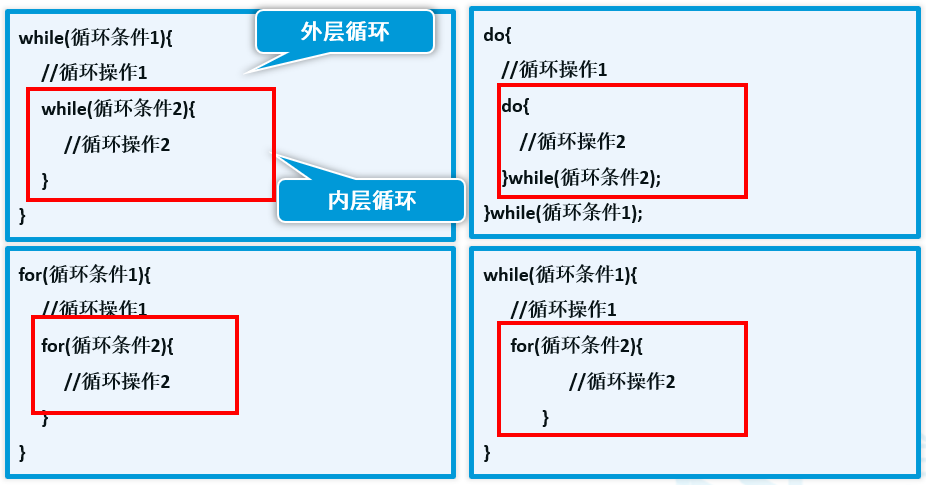
1.Java基础入门 -(10)流程控制-循环嵌套结构
什么是循环嵌套? 循环嵌套就是在循环体内,包含一个完成的循环结构。(我们在if嵌套里讲过) 示例1:使用双重循环输出九九乘法表。 运行结果: 示例2:请打印直角三角形。 (这里用 . 代替 空格 方便演示) 运行结果: 示例3:请打印等腰三角形。 运行结果: 示例4:请输出1-100之间的素数。 质数又称为素数,是一个大于1的自然数,除了1和它自身外,不能被其他自然数整除的数叫做质数;否则称为合数...

AlertDialogDemo自定义使用方法
效果图如下: Dialog左边的按钮忘记支付密码写错了 已修复 图就不改了 功能需求点击重试 再次打开输入支付密码页面 点击忘记支付密码跳转密码设置页面 此Demo只为演示AlertDialog的使用方法以及资源属性设置 需要其他功能请留言说明 这是一个支付密码输入失败的弹框 自定义了基本属性 XMl布局dialog_common 圆角框的属性commen_dialog_bg Styledialo...

2020网鼎杯---Java文件上传wp
前言 一篇文章读懂Java代码审计之XXE看过我这篇博客应该不难,没看过建议在看看。 题解 下载了所有的class发现需要上传xlsx poi 开头必须是execl 新建execl -1.xlsx文件,修改后缀名execl -1.xlsx.zip解压。 修改[Content-Types].xml 重新打包成excel-1.xlsx,文件名一定不能错。 在服务器上新建一个evil.etd文件。 然后...