PYTHON数据可视化(四)seaborn
线性关系可视化
许多数据集都有着众多连续变量。数据分析的目的经常就是衡量变量之间的关系,我们之前介绍了可以绘制双变量分布的函数。然而,使用统计模型来估计两个噪声观测组之间的简单关系可能是非常有帮助的。我们在这一章中讨论的函数功能将在线性回归的框架实现。
请注意,seaborn并不是一个统计分析库,这里所做的回归仅仅是粗略的。其目的是在探索性数据分析时,提供快捷的可视化工具,便于人们了解变量间可能存在的关系。(statsmodels)
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(color_codes=True)
np.random.seed(sum(map(ord, "regression")))
tips = sns.load_dataset("tips")
绘制线性回归模型
regplot()和lmplot()都可以绘制线性回归曲线。这两个函数非常相似,甚至共有一些核心功能。我将着力讲解二者的区别,这会帮助你选用恰当的工具。
在最简单的调用中,两个函数都会画出双变量的散点图,然后以y~x拟合回归方程和预测值95%置信区间并将其画出。
sns.regplot(x="total_bill", y="tip", data=tips);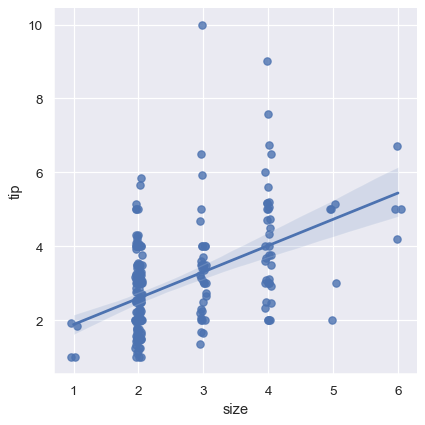
sns.lmplot(x="total_bill", y="tip", data=tips);
你应该已经注意到两幅图只有尺寸上的区别。我们在这里只进行简短的解释。目前为止两者间主要的区别是,regplot接受各种格式的x y,包括numpy arrays ,pandas series 或者pandas Dataframe对象。相比之下,lmplot()只接受字符串对象。这种数据格式被称为’long-form’或者’tidy’。除了输入数据的便利性外,regplot()可以看做拥有lmplot()特征的一个子集,所以接来下我们将用lmplot()进行演示。
实际上官方手册这里解释的并不直观。两者区别在于sns.regplot(x=tips[‘total_bill’], y=tips[‘tip’])可以运行,data=~这个参数不必要。但是sns.lmplot(x=tips[‘total_bill’], y=tips[‘tip’], data=tips)就必须传入data=~参数
当一个数据为离散值时,也可以生成一个回归曲线,但是这种散点图往往不是最优的。
sns.lmplot(x="size", y="tip", data=tips);
我们可以通过给离散变量添加随机噪声(“jitter”)的方式使得这些值的分布更加清晰。注意!这些噪声只是改变了散点图,并不影响回归曲线。
sns.lmplot(x="size", y="tip", data=tips, x_jitter=.05);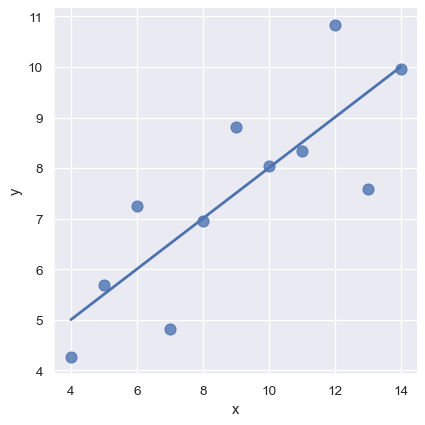
我们也可以使用每组数据的集中趋势和置信区间来代替离散点。
sns.lmplot(x="size", y="tip", data=tips, x_estimator=np.mean);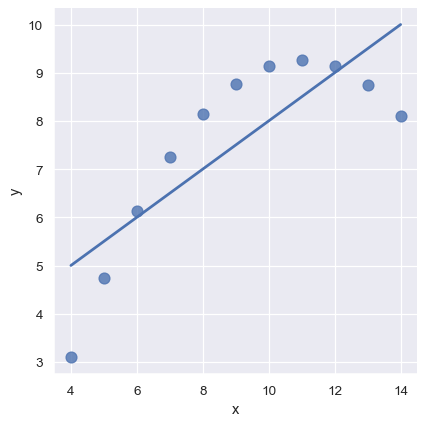
拟合不同模型
上文使用的回归模型非常简单。不过其并不使用于某些数据集。 Anscombe’s quartet数据集便提供了一些例子。在这些例子中简单线性模型结果之差,一看便知。
anscombe = sns.load_dataset("anscombe")
sns.lmplot(x="x", y="y", data=anscombe.query("dataset == 'I'"),
ci=None, scatter_kws={"s": 80});

在第二个数据集中,回归曲线相同,效果极差。
sns.lmplot(x="x", y="y", data=anscombe.query("dataset == 'II'"),
ci=None, scatter_kws={"s": 80});
当数据具有高阶关系时,lmplot()与regplot可以用多项式回归来来简单探索数据间的非线性关系:
sns.lmplot(x="x", y="y", data=anscombe.query("dataset == 'II'"),
order=2, ci=None, scatter_kws={"s": 80});
另一个问题便是异常值。
sns.lmplot(x="x", y="y", data=anscombe.query("dataset == 'III'"),
ci=None, scatter_kws={"s": 80});
可以采用robust回归解决这一问题。
sns.lmplot(x="x", y="y", data=anscombe.query("dataset == 'III'"),
robust=True, ci=None, scatter_kws={"s": 80});
当因变量(y)为分类变量时,线性回归将给出十分玄学的结果。
tips["big_tip"] = (tips.tip / tips.total_bill) > .15
sns.lmplot(x="total_bill", y="big_tip", data=tips,
y_jitter=.03);
这种情况下下应该采用logistic回归。
sns.lmplot(x="total_bill", y="big_tip", data=tips,
logistic=True, y_jitter=.03)
请注意 logistic回归和robust回归相较于简单线性回归需要更大的计算量,其置信区间的产生也依赖于bootstrap采样,你可以关掉置信区间估计来提高速度。(ci=None)
一个完全不同的方法是使用一个lowess smoother拟合非参数回归。 这种方法具有最少的假设,尽管它是计算密集型的,因此目前根本不计算置信区间。
sns.lmplot(x="total_bill", y="tip", data=tips,
lowess=True);
residplot()可以用来绘制残差分布。
sns.residplot(x="x", y="y", data=anscombe.query("dataset == 'I'"),
scatter_kws={"s": 80});
下面这个就显然有问题了。
sns.residplot(x="x", y="y", data=anscombe.query("dataset == 'II'"),
scatter_kws={"s": 80});
考虑到其他变量时
上面的图表展示了许多探索一对变量之间关系的方法。很多时候,我们更关心两个变量变化是如何影响第三个变量的。这也是lmplot()与regplot()的区别之一。regplot()只能显示一对变量之间的关系,而lmplot()结合了regplot()与FacetGrid,提供了一个简单的接口,允许你探索最多其他三个分类变量的影响。
在同一子图中画出不同属性的数据,并用颜色加以区分是就好的方式。
sns.lmplot(x="total_bill", y="tip", hue="smoker", data=tips);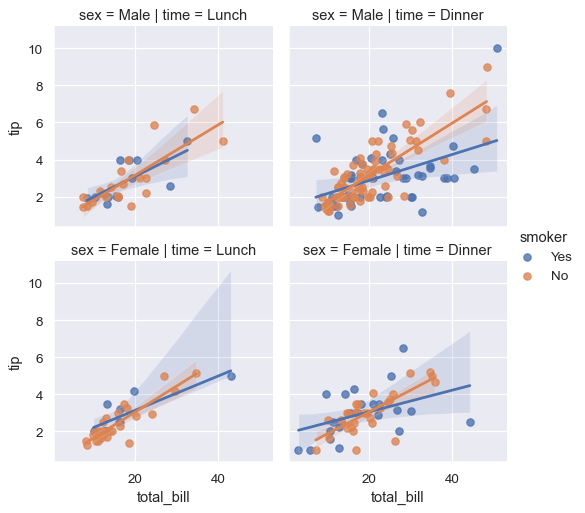
除了颜色之外,还可以使用不同的散点图标记来使黑色和白色的图像更好地绘制。 您还可以完全控制所用的颜色
sns.lmplot(x="total_bill", y="tip", hue="smoker", data=tips,
markers=["o", "x"], palette="Set1");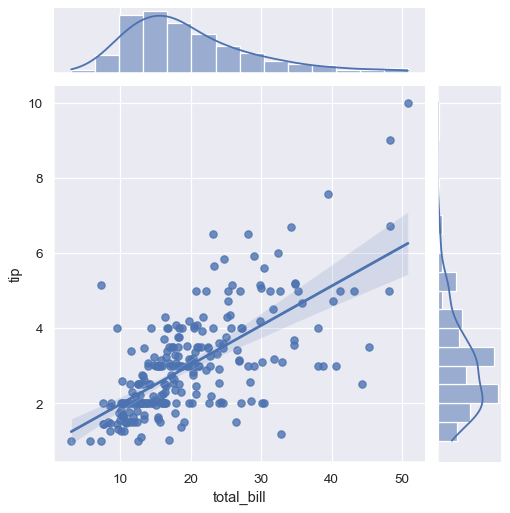
你可以通过绘制多个“facets”来添加更多的分类变量(col控制列区分属性 row控制行区分属性)
sns.lmplot(x="total_bill", y="tip", hue="smoker", col="time", data=tips)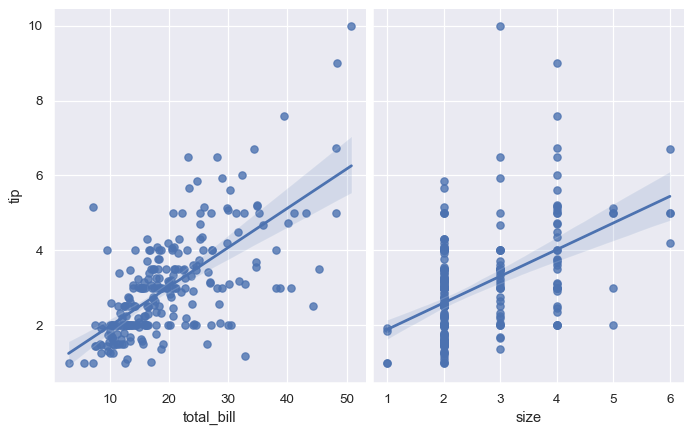
sns.lmplot(x="total_bill", y="tip", hue="smoker",
col="time", row="sex", data=tips);
控制图像的形状与大小
之前我们提到过lmplot()与regplot()默认条件下图形大小的区别。这是因为regplot()是一个“子图等级(axes-level)”函数。
axes 与axis不是一个东西!!!!讲解
它将图像绘制进一个特定的子图, 这意味着您可以自己制作多面板图形,并精确控制回归图的位置。如果没有提供特定的子图对象,它会将图像绘进最近调用的子图中,这意味着图像将遵循matplotlib默认的尺寸大小。要控制大小,您需要自己创建一个图形对象。
f, ax = plt.subplots(figsize=(5, 6))
sns.regplot(x="total_bill", y="tip", data=tips, ax=ax);
相比之下,lmplot()创建的图像大小由FacetGrid接口控制。你可通过调整size 和aspect这两个参数进行控制,这种调节只作用于当前图像,并不改变全局设置。
sns.lmplot(x="total_bill", y="tip", col="day", data=tips,
col_wrap=2,size=3);
sns.lmplot(x="total_bill", y="tip", col="day", data=tips,
aspect=.5);
在其他背景下绘制回归线
一些seaborn函数可以在更复杂的图像中调用regplot()。首当其中便是jointplot()函数,我们在这里介绍过, 除了前面讨论的绘图样式之外,jointplot()可以使用regplot()通过传递kind =”reg”来显示关键子图的线性回归拟合。
sns.jointplot(x="total_bill", y="tip", data=tips, kind="reg");
向pairplot函数中传入 king=“reg”也可以画出回归线。这结合了regplot()与FacetGrid,!!!不同之处!!!看下图你能看到,pairplot花的是两个自变量对一个因变量;而lmplot()画的是一对自变量 因变量在“不同第三者”条件下的图。 观察x轴就懂了
sns.pairplot(tips, x_vars=["total_bill", "size"], y_vars=["tip"],
size=5, aspect=.8, kind="reg");
类似lmplot(),但不同于jointplot(),使用hue参数在pairplot()中内置了一个附加分类变量的条件:
sns.pairplot(tips, x_vars=["total_bill", "size"], y_vars=["tip"],
hue="smoker", size=5, aspect=.8, kind="reg");
智能推荐

Python Seaborn综合指南,成为数据可视化专家
作者 | SHUBHAM SINGH 编译 | VK 来源 | Analytics Vidhya 概述 Seaborn是Python流行的数据可视化库 Seaborn结合了美学和技术,这是数据科学项目中的两个关键要素 了解其Seaborn作原理以及使用它生成的不同的图表 介绍 一个精心设计的可视化程序有一些特别之...
python科学计算——数据可视化(2) Seaborn
写在前面 在前面的文章介绍了Matplotlib的可视化基本功能,seaborn是基于Matplotlib的基础上进行了封装,能够快速的绘制精美的图表,使用起来比matplotlib更为方便简洁,本文是参考seaborn的官方文档进行的总结。 seaborn的样式控制 先看一下利用Matplotlib的绘制图像: 上面是用Matplotlib默认样式来进行绘图的,要变成seaborn的默认样式,简...
Python数据可视化 | Visualization tricks using Seaborn (2)
Visualization tricks using Seaborn (2) In the process of making visual charts, we often need to deal with the relationship between numeric variables(N) and category variables. Somethings we need to de...
Python数据可视化 | Visualization tricks using Seaborn (1)
Visualization tricks using Seaborn (1) In the process of making visual charts, we often need to deal with the relationship between numeric variables(N) and category variables. Somethings we need to de...

Python小白数据可视化教程: Seaborn 精讲
点击“简说Python”,选择“置顶/星标公众号” 福利干货,第一时间送达! 本文授权转载自王的机器 禁二次转载 作者:王圣元 阅读文本大概需要 24 分钟 老表建议先收藏,慢慢学 或者有需时可以查看 0 引言 本文是 Python 小白教程系列: 今天,我们讲讲数据可视化工具 Seaborn。 Seaborn 是基于 matplotlib...
猜你喜欢
python数据可视化——seaborn库介绍与使用
一、seaborn库介绍 seaborn是基于Matplotlib的Python数据可视化库。它提供了一个高级界面,用于绘制引人入胜且内容丰富的统计图形 只是在Matplotlib上进行了更高级的API封装,从而使作图更加容易 seaborn是针对统计绘图的,能满足数据分析90%的绘图需求,需要复杂的自定义图形还需要使用到Matplotlib seaborn 网站:http://seaborn.p...
Docker-Compose部署nginx 和lnmp
Docker-Compose tomcat lnmp tomcat 使用Docker-Compose部署Nginx代理Tomcat集群,实现负载均衡 在这个目录下创建多个目录 切换到nginx目录修改nginx的主配置文件: [root@host1 compose]# cd nginx/ [root@host1 nginx]# vim default.conf 在末尾添加: 修改: 切换到tmca...

19-20年月度行业分析
Table of Contents 1 对各一级行业分析 2 对女装行业进行分析 对各一级行业分析 platform cid industry category themonth 销售额 访客 客群指数 行业简称 月 年 年月 0 天猫 50010368 ZIPPO/瑞士军刀/眼镜 太阳眼镜 2020-01-01 62484514.13 6663217 ...

Python数据分析入门
博客原文:https://ouduidui.cn/blog/detail?blogId=5fcddf5c61ae700fd80190db 基础知识 数据的分类 数值型数据 表示大小或多少的数据 例子:年龄、年购买量 数值型数据分析方法 最小值和最大值:查看这两个值的目的是为了能够确定一组数据的上界和下界。 **平均值:**平均值可以反映一组数据的综合水平。 **中位数:**中位数和平均数一样都是用...
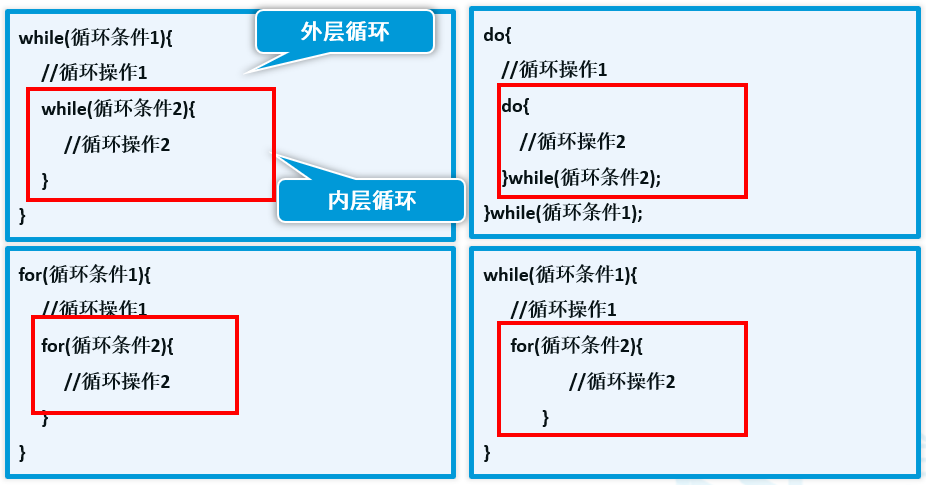
1.Java基础入门 -(10)流程控制-循环嵌套结构
什么是循环嵌套? 循环嵌套就是在循环体内,包含一个完成的循环结构。(我们在if嵌套里讲过) 示例1:使用双重循环输出九九乘法表。 运行结果: 示例2:请打印直角三角形。 (这里用 . 代替 空格 方便演示) 运行结果: 示例3:请打印等腰三角形。 运行结果: 示例4:请输出1-100之间的素数。 质数又称为素数,是一个大于1的自然数,除了1和它自身外,不能被其他自然数整除的数叫做质数;否则称为合数...