Python数据可视化——Seaborn笔记
写在前面:只记录本人在Kaggle数据可视化课程学习过程中,Seaborn模块的常用方法及部分效果图笔记,数据类型不作介绍和处理
课程链接Kaggle数据可视化课程
文章目录
导入模块
import pandas as pd
pd.plotting.register_matplotlib_converters()
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
数据可视化
1. 曲线图lineplot
# Set the width and height of the figure
plt.figure(figsize=(16,6))
# 曲线图(此处示例数据为日期索引)
sns.lineplot(data=fifa_data)
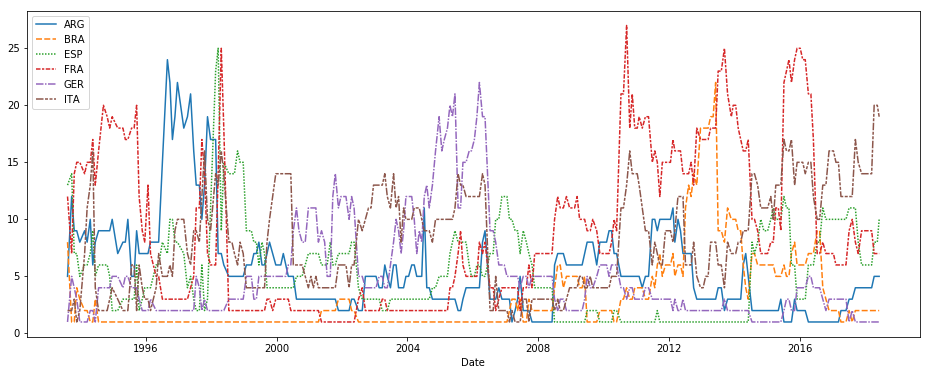
也可以单独选取列数据作图
sns.lineplot(data=spotify_data['Shape of You'], label="Shape of You")
sns.lineplot(data=spotify_data['Despacito'], label="Despacito")
plt.xlabel("Date")
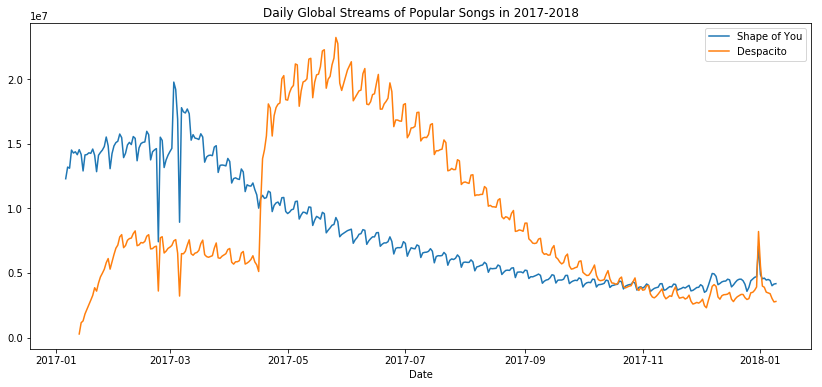
2. 条形图(barplot)
# Bar chart showing average score for racing games by platform
plt.figure(figsize=(8, 6))
sns.barplot(x=ign_data['Racing'], y=ign_data.index) # Your code here
# Add label for horizontal axis
plt.xlabel("Average Score")
# Add label for vertical axis
plt.title("Average Score for Racing Games, by Platform")
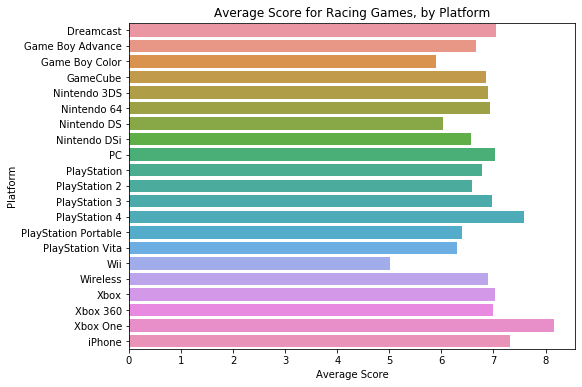
3.热图(heatmap)
# Heatmap showing average game score by platform and genre
plt.figure(figsize=(10,10))
sns.heatmap(ign_data, annot=True)
#
# Add label for horizontal axis
plt.xlabel("Genre")
# Add label for vertical axis
plt.title("Average Game Score, by Platform and Genre")
annot=True- 加载数据集时,确保每个单元格的值都显示在图表上(忽略此操作将删除每个单元格中的数值)
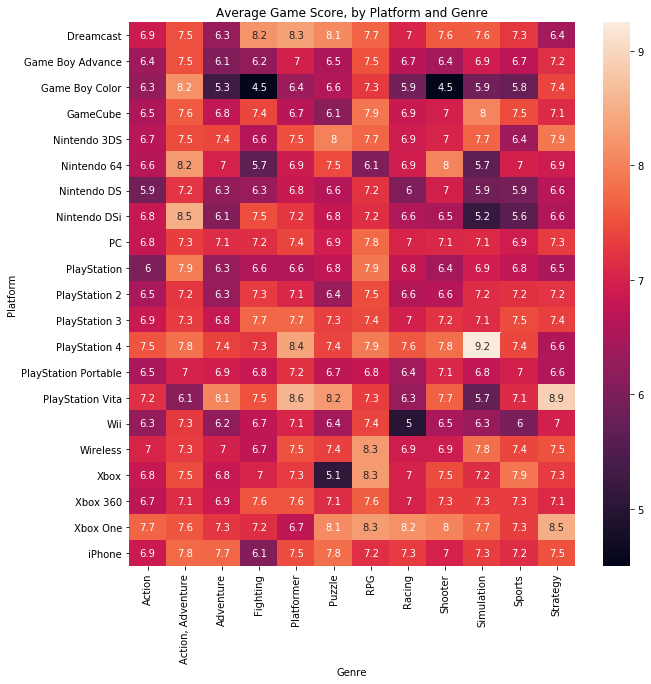
4.散点图(scatterplot)
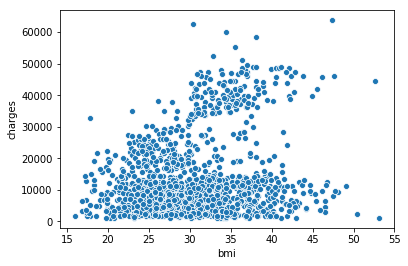
4.1 普通散点图
sns.scatterplot(x=insurance_data['bmi'], y=insurance_data['charges'])
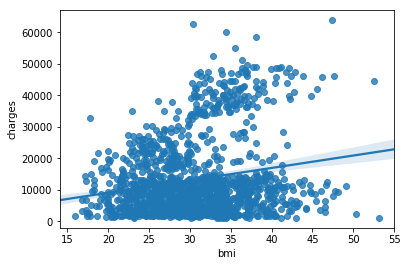
4.2 回归线散点图
sns.regplot(x=insurance_data['bmi'], y=insurance_data['charges'])
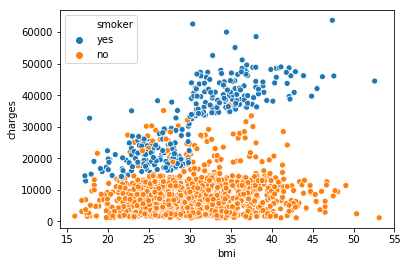
4.3 多变量特征散点图
sns.scatterplot(x=insurance_data['bmi'], y=insurance_data['charges'], hue=insurance_data['smoker'])
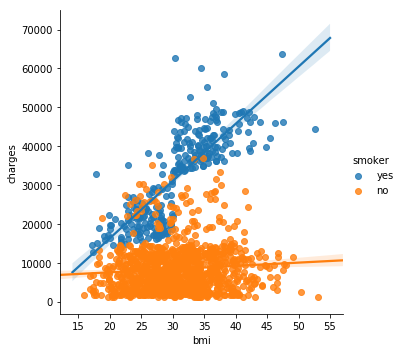
4.4 多变量特征回归线散点图(注意此处坐标轴设置方式)
sns.lmplot(x="bmi", y="charges", hue="smoker", data=insurance_data)
4.5 不同特征变量对比散点图(方便对比关键特征变量)
sns.swarmplot(x=insurance_data['smoker'],
y=insurance_data['charges'])

5. 直方图
iris数据
5.1 普通直方图
# Histogram
sns.distplot(a=iris_data['Petal Length (cm)'], kde=False)
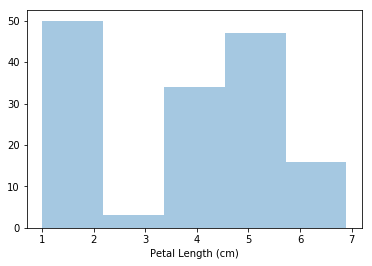
kde=False必须提供该参数,否则直方图会出错。
5.2 彩色直方图
使用不同颜色标识不同标签数据的直方图
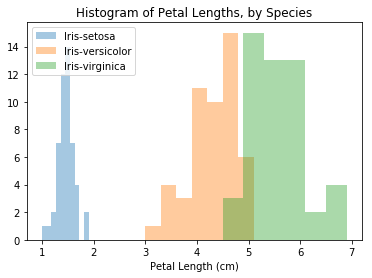
# Histograms for each species
sns.distplot(a=iris_set_data['Petal Length (cm)'], label="Iris-setosa", kde=False)
sns.distplot(a=iris_ver_data['Petal Length (cm)'], label="Iris-versicolor", kde=False)
sns.distplot(a=iris_vir_data['Petal Length (cm)'], label="Iris-virginica", kde=False)
# Add title
plt.title("Histogram of Petal Lengths, by Species")
# Force legend to appear
plt.legend()
6. 核密度估计图(kernel density estimate,KDE)
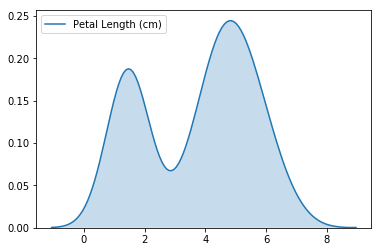
6.1 KDE
# KDE plot
sns.kdeplot(data=iris_data['Petal Length (cm)'], shade=True)
# shade=True 表示将曲线下方区域用颜色标记
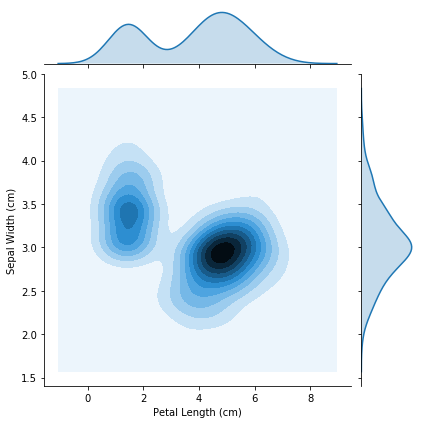
6.2 2D KDE
# 2D KDE plot
sns.jointplot(x=iris_data['Petal Length (cm)'], y=iris_data['Sepal Width (cm)'], kind="kde")
6.3 彩色KDE
使用不同颜色标识不同标签数据
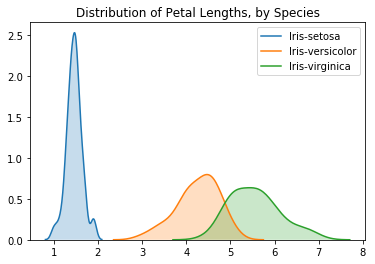
# KDE plots for each species
sns.kdeplot(data=iris_set_data['Petal Length (cm)'], label="Iris-setosa", shade=True)
sns.kdeplot(data=iris_ver_data['Petal Length (cm)'], label="Iris-versicolor", shade=True)
sns.kdeplot(data=iris_vir_data['Petal Length (cm)'], label="Iris-virginica", shade=True)
# Add title
plt.title("Distribution of Petal Lengths, by Species")
持续更新中~(2020-5-8)
智能推荐
Python数据可视化库-----Seaborn(唐宇迪机器学习笔记)
简介 什么是Seaborn Seaborn是基于matplotlib的图形可视化python包。它提供了一种高度交互式界面,便于用户能够做出各种有吸引力的统计图表。 Seaborn是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,在大多数情况下使用seaborn能做出很具有吸引力的图,而使用matplotlib就能制作具有更多特色的图。应该把Seaborn视为matp...
Python数据分析-可视化“大佬”之Seaborn
——如果有想关注Java开发相关的内容,可以转Java修炼之道 详细观看—— Seaborn 既然有了matplotlib,那为啥还需要seaborn呢?其实seaborn是在matplotlib基础上进行封装,Seaborn就是让困难的东西更加简单。用Matplotlib最大的困难是其默认的各种参数,而Seaborn则完全避免了这一问题。seabo...

Python数据分析可视化Seaborn实例讲解
Seaborn是一种基于matplotlib的图形可视化python libraty。它提供了一种高度交互式界面,便于用户能够做出各种有吸引力的统计图表。 Seaborn其实是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,在大多数情况下使用seaborn就能做出很具有吸引力的图,而使用matplotlib就能制作具有更多特色的图。应该把Seaborn视为matplo...

python数据可视化之Seaborn(四)
写在开头:今天分享的是关于数据相关性的绘图方法,参考文献会附在文章最后的链接。 前文回顾: 第一节分享了Seaborn绘图的整体颜色与风格比例调控,可点击链接查看。 python数据可视化之Seaborn(一) 第二节分享了连续、分类、离散数据的绘图颜色的方法,可点击链接查看。 python数据可视化之Seaborn(二) 第三节分享了对于数据分布的绘图方法,可点击链接查看。 python数据可视...
Python数据可视化-matplotlib and seaborn
鸢尾花iris.csv文件 numpy, matplotlib, seaborn, pandas 1 画线,set_style( ) set( ) 2 distplot( )直方图加强版,kdeplot( )密度曲线图 3 箱线图 boxplot( ) 4 热图 heatmap( ) 5 散点图 scatter( ) 6 矩阵散点图 pairplot( ) 7 柱状图 bar() 8 饼图 pie...
猜你喜欢

Python Seaborn综合指南,成为数据可视化专家
作者 | SHUBHAM SINGH 编译 | VK 来源 | Analytics Vidhya 概述 Seaborn是Python流行的数据可视化库 Seaborn结合了美学和技术,这是数据科学项目中的两个关键要素 了解其Seaborn作原理以及使用它生成的不同的图表 介绍 一个精心设计的可视化程序有一些特别之...
Docker-Compose部署nginx 和lnmp
Docker-Compose tomcat lnmp tomcat 使用Docker-Compose部署Nginx代理Tomcat集群,实现负载均衡 在这个目录下创建多个目录 切换到nginx目录修改nginx的主配置文件: [root@host1 compose]# cd nginx/ [root@host1 nginx]# vim default.conf 在末尾添加: 修改: 切换到tmca...

19-20年月度行业分析
Table of Contents 1 对各一级行业分析 2 对女装行业进行分析 对各一级行业分析 platform cid industry category themonth 销售额 访客 客群指数 行业简称 月 年 年月 0 天猫 50010368 ZIPPO/瑞士军刀/眼镜 太阳眼镜 2020-01-01 62484514.13 6663217 ...

Python数据分析入门
博客原文:https://ouduidui.cn/blog/detail?blogId=5fcddf5c61ae700fd80190db 基础知识 数据的分类 数值型数据 表示大小或多少的数据 例子:年龄、年购买量 数值型数据分析方法 最小值和最大值:查看这两个值的目的是为了能够确定一组数据的上界和下界。 **平均值:**平均值可以反映一组数据的综合水平。 **中位数:**中位数和平均数一样都是用...
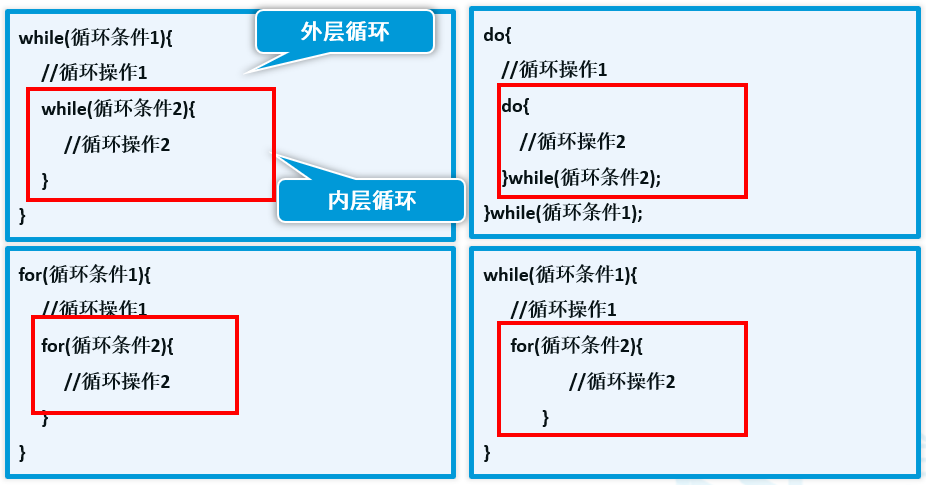
1.Java基础入门 -(10)流程控制-循环嵌套结构
什么是循环嵌套? 循环嵌套就是在循环体内,包含一个完成的循环结构。(我们在if嵌套里讲过) 示例1:使用双重循环输出九九乘法表。 运行结果: 示例2:请打印直角三角形。 (这里用 . 代替 空格 方便演示) 运行结果: 示例3:请打印等腰三角形。 运行结果: 示例4:请输出1-100之间的素数。 质数又称为素数,是一个大于1的自然数,除了1和它自身外,不能被其他自然数整除的数叫做质数;否则称为合数...