Spark join种类(>3种)及join选择依据
标签: spark java flink kafka hadoop
浪尖维新:bigdatatip
hashjoin
join是作为业务开发绕不开的SQL话题,无论是传统的数据库join,还是大数据里的join。
做过Spark/flink流处理的应该都用过一种流表和维表的join,维表对于Spark来说可以是driver端获取后广播到每个Executor,然后在executor端执行流表task的时候join,其实大多数是个hashmap,而很多时候这个维表比较大会存储于redis/hbase。Flink进行维表join可以用的方式比较多了,比如直接open方法里从外部加载的静态hashmap,这种就无法更新,因为Flink不像Spark可以每个批次或者若干批次加载一次维表。也可以使用LRU+异步IO+外部存储来实现join,这样就实现了对外部更新的感知。甚至也可以使用Flink的广播功能实现join操作。
上面所说的就是比较常见的hashjoin的简单表达,将维表通过join的条件key构建为一个hashtable,就拿java 8的HashMap来说吧,就是一个数组+链表(链表过长会变为红黑树),数组下标就是key,数组存储的是value的指针。
join的时候主表通过join条件构建key去,hashmap里查找。
Spark BroadCastHashJoin
翻过源码之后你就会发现,Spark 1.6之前实现BroadCastHashJoin就是利用的Java的HashMap来实现的。大家感兴趣可以去Spark 1.6的源码里搜索BroadCastHashJoin,HashedRelation,探查一下源码。
具体实现就是driver端根据表的统计信息,当发现一张小表达到广播条件的时候,就会将小表collect到driver端,然后构建一个HashedRelation,然后广播。
其实,就跟我们在使用Spark Streaming的时候广播hashmap一样。
重点强调里面最大行数限制和最大bytes限制并不是我们设置的自动广播参数限制,而是内部存储结构的限制。
还有在Spark后期版本主要就是使用了TaskMemoryManager而不是HashMap进行了背书。
ShuffledHashJoin
BroadCastHashJoin适合的是大表和小表的join策略,将整个小表广播。很多时候,参与join的表本身都不适合广播,也不适合放入内存,但是按照一定分区拆开后就可以放入内存构建为HashRelation。这个就是分治思想了,将两张表按照相同的hash分区器及分区数进行,对join条件进行分区,那么需要join的key就会落入相同的分区里,然后就可以利用本地join的策略来进行join了。
也即是ShuffledHashJoin有两个重要步骤:
-
join的两张表有一张是相对小表,经过拆分后可以实现本地join。
-
相同的分区器及分区数,按照joinkey进行分区,这样约束后joinkey范围就限制在相同的分区中,不依赖其他分区完成join。
-
对小表分区构建一个HashRelation。然后就可以完成本地hashedjoin了,参考ShuffleHashJoinExec代码,这个如下图:
SortMergeJoin
上面两张情况都是小表本身适合放入内存或者中表经过分区治理后适合放入内存,来完成本地化hashedjoin,小表数据放在内存中,很奢侈的,所以经常会遇到join,就oom。小表,中表都是依据内存说的,你内存无限,那是最好。
那么,大表和大表join怎么办?这时候就可以利用SortMergeJoin来完成。
SortMergeJoin基本过程如下:
-
首先采取相同的分区器及分区数对两张表进行重分区操作,保证两张表相同的key落到相同的分区。
-
对于单个分区节点两个表的数据,分别进行按照key排序。
-
对排好序的两张分区表数据执行join操作。join操作很简单,分别遍历两个有序序列,碰到相同join key就merge输出,否则取更小一边。‘
Spark 3.1以后的spark版本对sortmergejoin又进一步优化了。
Spark SQL的join方式选择
假如用户使用Spark SQL的适合用了hints,那Spark会先采用Hints提示的join方式。
broadcastHashJoin,hints写法如下:
-- 支持 BROADCAST, BROADCASTJOIN and MAPJOIN 来表达 broadcast hintSELECT /*+ BROADCAST(r) */ * FROM records r JOIN src s ON r.key = s.key
ShuffledHashJoin,hints的sql写法如下:
-- 仅支持 SHUFFLE_HASH 来表达 ShuffledHashJoin hintSELECT /*+ SHUFFLE_HASH(r) */ * FROM records r JOIN src s ON r.key = s.key
SortMergeJoin,hints的SQL写法如下:
-- 支持 SHUFFLE_MERGE, MERGE and MERGEJOIN 来表达 SortMergeJoin hintSELECT /*+ MERGEJOIN(r) */ * FROM records r JOIN src s ON r.key = s.key
假设用户没有使用hints,默认顺序是:
1.先判断,假设join的表统计信息现实,一张表大小大于0,且小于等于用户配置的自动广播阈值则,采用广播。
plan.stats.sizeInBytes >= 0 && plan.stats.sizeInBytes <= conf.autoBroadcastJoinThreshold参数:spark.sql.autoBroadcastJoinThreshold
假设两张表都满足广播需求,选最小的。
2.不满足广播就判断是否满足ShuffledHashJoin,首先下面参数要设置为false,默认为true。
spark.sql.join.preferSortMergeJoin=true,
还有两个条件,根据统计信息,表的bytes是广播的阈值*总并行度:
plan.stats.sizeInBytes < conf.autoBroadcastJoinThreshold * conf.numShufflePartitions
并且该表bytes乘以3要小于等于另一张表的bytes:
a.stats.sizeInBytes * 3 <= b.stats.sizeInBytes
那么这张表就适合分治之后,作为每个分区构建本地hashtable的表。
3.不满足广播,也不满足ShuffledHashJoin,就判断是否满足SortMergeJoin。条件很简单,那就是key要支持可排序。
def createSortMergeJoin() = {if (RowOrdering.isOrderable(leftKeys)) { Some(Seq(joins.SortMergeJoinExec( leftKeys, rightKeys, joinType, condition, planLater(left), planLater(right)))) } else { None }}
这段代码是在SparkStrageties类,JoinSelection单例类内部。
createBroadcastHashJoin(hintToBroadcastLeft(hint), hintToBroadcastRight(hint)) .orElse { if (hintToSortMergeJoin(hint)) createSortMergeJoin() else None } .orElse(createShuffleHashJoin(hintToShuffleHashLeft(hint), hintToShuffleHashRight(hint))) .orElse { if (hintToShuffleReplicateNL(hint)) createCartesianProduct() else None } .getOrElse(createJoinWithoutHint())
当然,这三种join都是等值join,之前的版本Spark仅仅支持等值join但是不支持非等值join,常见的业务开发中确实存在非等值join的情况,spark目前支持非等值join的实现有以下两种,由于实现问题,确实很容易oom。
Broadcast nested loop joinShuffle-and-replicate nested loop join。
推荐阅读:
智能推荐
Spark common join vs map join
Spark common join vs map join common join demo ui 普通join会产生shuffle map join Spark 使用广播变量小表进行广播 ui map join 没有产生shuffle...

Spark SQL是如何选择join策略的?
前言 我们都知道,Spark SQL主要有三种实现join的策略,分别是Broadcast hash join、Shuffle hash join、Sort merge join,在之前写的这篇文章里已经做过了简要的介绍。不过笔者还没说过Catalyst是依据什么样的规则来选择join策略的,本文来简单补个漏。 Catalyst在由优化的逻辑计划生成物理计划的过程中,会根据org.apache.s...
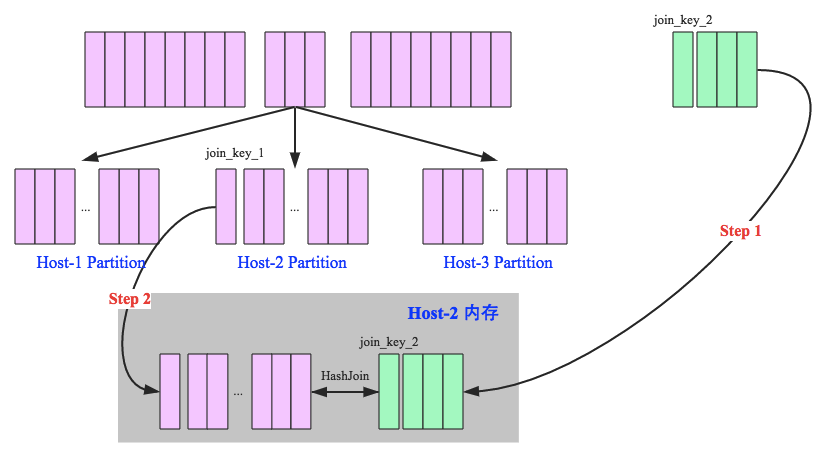
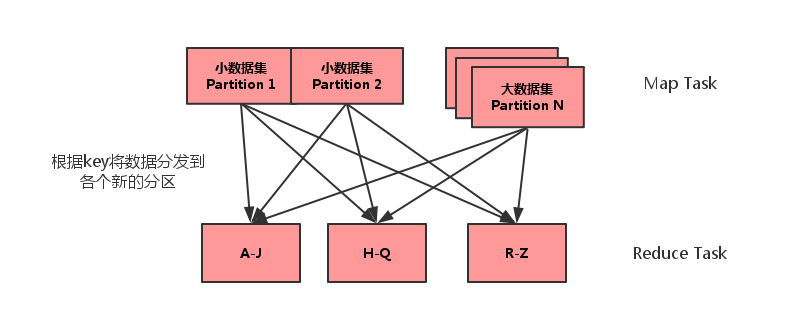
Spark map-side-join 关联优化
将多份数据进行关联是数据处理过程中非常普遍的用法,不过在分布式计算系统中,这个问题往往会变的非常麻烦,因为框架提供的 join 操作一般会将所有数据根据 key 发送到所有的 reduce 分区中去,也就是 shuffle 的过程。造成大量的网络以及磁盘IO消耗,运行效率极其低下,这个过程一般被称为 reduce-side-join。 如果其中有张表较小的话,我们则可以自己实现在 map 端实现数...

Spark Core - 提高 RDD join 的性能
Spark 作为分布式的计算框架,最为影响其执行效率的地方就是频繁的网络传输。所以一般的,在不存在数据倾斜的情况下,想要提高 Spark job 的执行效率,就尽量减少 job 的 shuffle 过程(减少 job 的 stage),或者退而减小 shuffle 带来的影响,join 操作也不例外。 所以,针对 spark RDD 的 join 操作的使用,提供一下几条建议: 尽量减少参与 jo...
猜你喜欢

CV笔记03:自监督GAN(ss-gan)
无需标注数据,利用辅助性旋转损失的自监督GANs,-- 对抗+自监督的无监督方式 《通过辅助旋转损失进行的自监督GAN》CVPR 2019 论文速看 0.摘要 目前自然图像合成主要是条件GAN,但是其缺点是需要标注数据。 我们利用两种流行的无监督学习技术,对抗训练和自我监督,并朝着缩小有条件GAN和无条件GAN之间的差距迈出了一步。 我们允许网络在代表学习的任务上进行协作,同时相对于经典GAN博弈...

Retrofit(三)上传文件
想了想,觉得还是把自定义的东西放到最后再讲,所以讲下用Retrofit上传文件,就拿上传图片来说,因为上传图片我是想写一个专题的,包括以下: 1.上传图片操作 2.展示图片操作 3.选择图片操作 上传图片这篇讲,用Retrofit,之后我还想写一篇是用httpurlconnection的,因为用它会有个拼接的操作,只有经历过拼接才会更深刻的了解使用Http上传文件的过程。展示图片我其实已经写完了,...
Linux安装SQL2019
官方文档 导入公共存储库 GPG **: 为 SQL Server 2019 注册 Microsoft SQL Server Ubuntu 存储库: 使用以下命令进行安装 SQL2019: 包安装完成后,运行 mssql-conf setup,按照提示设置 SA 密码并选择版本,并执行以下命令: 完成配置后,验证服务是否正在运行:...
vue-cli使用vscode编辑器如何自动eslint检测
VSCode 保存时自动ESlint格式化 Eslint 自动格式化 首先安装ESLint插件 2.安装完成后,每次修改完代码都需要执行 "npm run lint"之后才能格式化 打开设置选项 编辑代码settings.json 新建.eslintrc.js文件 根据eslint官网规则(eslint官网),编写eslintrc.js文件 保存之后,今后在保存时就能自动ESL...