Structured Streaming 之状态存储解析

福利部分: 《大数据成神之路》大纲
《几百TJava和大数据资源下载》
本文内容适用范围:
* 2018.11.02 update, Spark 2.4 全系列 √ (已发布:2.4.0)
* 2018.02.28 update, Spark 2.3 全系列 √ (已发布:2.3.0 ~ 2.3.2)
* 2017.07.11 update, Spark 2.2 全系列 √ (已发布:2.2.0 ~ 2.2.3)阅读本文前,请一定先阅读 Structured Streaming 实现思路与实现概述 一文,其中概述了 Structured Streaming 的实现思路(包括 StreamExecution, StateStore 等在 Structured Streaming 里的作用),有了全局概念后再看本文的细节解释。
引言
我们知道,持续查询的驱动引擎 StreamExecution 会持续不断地驱动每个批次的执行。
对于不需要跨批次的持续查询,如 map(), filter() 等,每个批次之间的执行相互独立,不需要状态支持。而比如类似 count() 的聚合式持续查询,则需要跨批次的状态支持,这样本批次的执行只需依赖上一个批次的结果,而不需要依赖之前所有批次的结果。这也即增量式持续查询,能够将每个批次的执行时间稳定下来,避免越后面的批次执行时间越长的情形。
这个增量式持续查询的思路和实现,我们在 [Structured Streaming 实现思路与实现概述](1.1 Structured Streaming 实现思路与实现概述.md) 解析过:
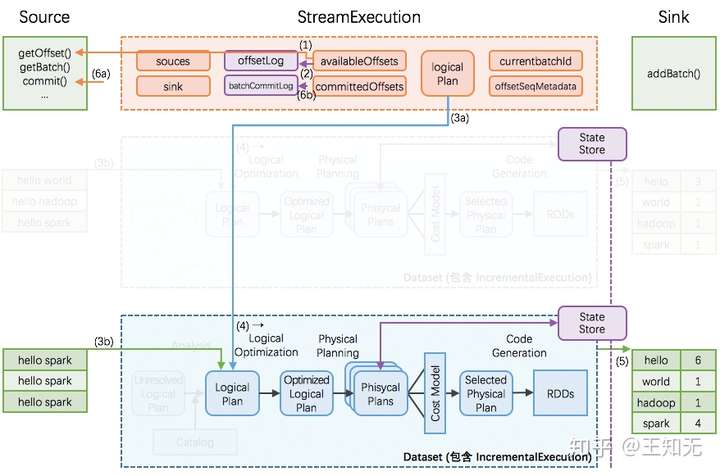
而在这里面的 StateStore,即是 Structured Streaming 用于保存跨批次状态结果的模块组件。本文解析 StateStore 模块。
StateStore 模块的总体思路
StateStore 模块的总体思路:
- 分布式实现
- 跑在现有 Spark 的 driver-executors 架构上
- driver 端是轻量级的 coordinator,只做协调工作
- executor 端负责状态的实际分片的读写
- 状态分片
- 因为一个应用里可能会包含多个需要状态的 operator,而且 operator 本身也是分 partition 执行的,所以状态存储的分片以
operatorId+partitionId为切分依据 - 以分片为基本单位进行状态的读入和写出
- 每个分片里是一个 key-value 的 store,key 和 value 的类型都是
UnsafeRow(可以理解为 SparkSQL 里的 Object 通用类型),可以按 key 查询、或更新
- 因为一个应用里可能会包含多个需要状态的 operator,而且 operator 本身也是分 partition 执行的,所以状态存储的分片以
- 状态分版本
- 因为 StreamExection 会持续不断地执行批次,因而同一个 operator 同一个 partition 的状态也是随着时间不断更新、产生新版本的数据
- 状态的版本是与 StreamExecution 的进展一致,比如 StreamExection 的批次 id = 7 完成时,那么所有 version = 7 的状态即已经持久化
- 批量读入和写出分片
- 对于每个分片,读入时
- 根据 operator + partition + version, 从 HDFS 读入数据,并缓存在内存里
- 对于每个分片,读入时
-
- 对于每个分片,写出时
- 累计当前版本(即 StreamExecution 的当前批次)的多行的状态修改,一次性写出到 HDFS 一个修改的流水 log,流水 log 写完即标志本批次的状态修改完成
- 同时应用修改到内存中的状态缓存
- 对于每个分片,写出时
关于 StateStore 的 operator, partiton, version 有一个图片可帮助理解:
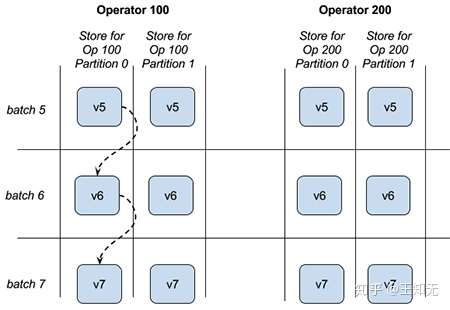
StateStore:(a)迁移、(b)更新和查询、(c)维护、(d)故障恢复
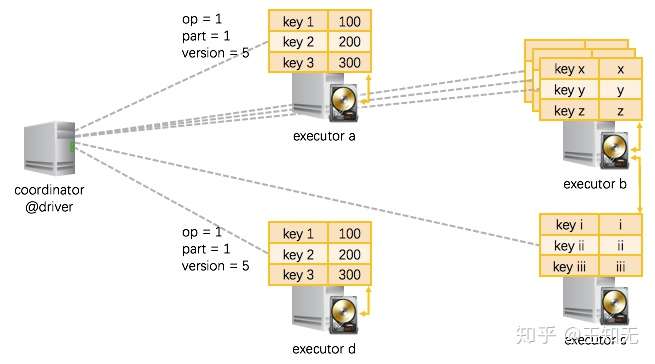
(a) StateStore 在不同的节点之间如何迁移
在 StreamExecution 执行过程中,随时在 operator 实际执行的 executor 节点上唤起一个状态存储分片、并读入前一个版本的数据即可(如果 executor 上已经存在一个分片,那么就直接重用,不用唤起分片、也不用读入数据了)。
我们上节讲过,持久化的状态是在 HDFS 上的。那么如上图所示:
executor a, 唤起了operator = 1, partition = 1的状态存储分片,从 HDFS 里位于本机的数据副本 load 进来version = 5的数据;- 一个 executor 节点可以执行多个 operator,那么也就可以在一个 executor 上唤起多个状态存储分片(分别对应不同的 operator + partition),如图示
executor b; - 在一些情况下,需要从其他节点的 HDFS 数据副本上 load 状态数据,如图中
executor c需要从executor b的硬盘上 load 数据; - 另外还有的情况是,同一份数据被同时 load 到不同的 executor 上,如
executor d和executor a即是读入了同一份数据 —— 推测执行时就容易产生这种情况 —— 这时也不会产生问题,因为 load 进来的是同一份数据,然后在两个节点上各自修改,最终只会有一个节点能够成功提交对状态的修改。
(b) StateStore 的更新和查询
我们前面也讲过,在一个状态存储分片里,是 key-value 的 store。这个 key-value 的 store 支持如下操作:
/* == CRUD 增删改查 =============================== */
// 查询一条 key-value
def get(key: UnsafeRow): Option[UnsafeRow]
// 新增、或修改一条 key-value
def put(key: UnsafeRow, value: UnsafeRow): Unit
// 删除一条符合条件的 key-value
def remove(condition: UnsafeRow => Boolean): Unit
// 根据 key 删除 key-value
def remove(key: UnsafeRow): Unit
/* == 批量操作相关 =============================== */
// 提交当前执行批次的所有修改,将刷出到 HDFS,成功后版本将自增
def commit(): Long
// 放弃当前执行批次的所有修改
def abort(): Unit
// 当前状态分片、当前版本的所有 key-value 状态
def iterator(): Iterator[(UnsafeRow, UnsafeRow)]
// 当前状态分片、当前版本比上一个版本的所有增量更新
def updates(): Iterator[StoreUpdate]使用 StateStore 的代码可以这样写(现在都是 Structured Streaming 内部实现在使用 StateStore,上层用户无需面对这些细节):
// 在最开始,获取正确的状态分片(按需重用已有分片或读入新的分片)
val store = StateStore.get(StateStoreId(checkpointLocation, operatorId, partitionId), ..., version, ...)
// 开始进行一些更改
store.put(...)
store.remove(...)
// 更改完成,批量提交缓存在内存里的更改到 HDFS
store.commit()
// 查看当前状态分片的所有 key-value / 刚刚更新了的 key-value
store.iterator()
store.updates()(c) StateStore 的维护
我们看到,前面 StateStore 在写出状态的更新时,是写出的修改流水 log。
StateStore 本身也带了 maintainess 即维护模块,会周期性的在后台将过去的状态和最近若干版本的流水 log 进行合并,并把合并后的结果重新写回到 HDFS:old_snapshot + delta_a + delta_b + … => lastest_snapshot。
这个过程跟 HBase 的 major/minor compact 差不多,但还没有区别到 major/minor 的粒度。
(d) StateStore 的故障恢复
StateStore 的所有状态以 HDFS 为准。如果某个状态分片在更新过程中失败了,那么还没有写出的更新会不可见。
恢复时也是从 HDFS 读入最近可见的状态,并配合 StreamExecution 的执行批次重做。从另一个角度说,就是大家 —— 输入数据、及状态存储 —— 先统一往后会退到本执行批次刚开始时的状态,然后重新计算。当然这里重新计算的粒度是 Spark 的单个 task,即一个 partition 的输入数据 + 一个 partition 的状态存储。
从 HDFS 读入最近可见的状态时,如果有最新的 snapshot,也就用最新的 snapshot,如果没有,就读入稍旧一点的 snapshot 和新的 deltas,先做一下最新状态的合并。
总结
在 Structured Streaming 里,StateStore 模块提供了 分片的、分版本的、可迁移的、高可用 key-value store。
基于这个 StateStore 模块,StreamExecution 实现了 增量的 持续查询、和很好的故障恢复以维护 end-to-end exactly-once guarantees。
扩展阅读
- Github: org/apache/spark/sql/execution/streaming/state/StateStore.scala
- Github: org/apache/spark/sql/execution/streaming/state/HDFSBackedStateStoreProvider.scala
福利部分:
《大数据成神之路》大纲
《几百TJava和大数据资源下载》
智能推荐
Structured Streaming 快速入门系列(二)Structured Streaming 实战之 Souce
文章目录 Source 从 HDFS 中读取数据 案例结构 产生小文件并推送到 HDFS 流式计算统计 HDFS 上的小文件 从 Kafka 中读取数据 Kafka 的场景和结构 Kafka 和 Structured Streaming 整合的结构 需求介绍 使用 Spark 流计算连接 Kafka 数据源 JSON 解析和数据统计 Source 目标和过程 目标 流式计算一般就是通过数据源读取数...
Spark Streaming 转向 Structured Streaming
导读 Spark 团队对 Spark Streaming 的维护将会越来越少,Spark 2.4 版本的 Release Note 里面甚至一个 Spark Streaming 相关的 ticket 都没有。相比之下,Structured Streaming 有将近十个 ticket 说明。所以,是时候舍弃 Spark Streaming 转向 Structured Streaming 了,当然理...

Structured Streaming初试
本篇博客记录一下自己初次尝试使用Structured Streaming。 首先写 一个程序来监昕网络端口发来的内容,然后进行 WordCount 。 为了方便就直接在IDE上运行,使用IDEA运行时,需要设置一下运行参数 run -->Edit Configurations... 接下来运行该程序,在 Linux 命令窗口运行 nc-lk 9999 开启 9999 端口。 在IDEA控制台...
Spark Structured Streaming
Spark Structured Streaming 结构化流 Structured Streaming是一个构建在Spark SQL基础上可靠具备容错处理的流处理引擎。Structured Streaming提供快速,可扩展,容错,端到端的精确一次流处理,而无需用户推理流式传输。 流数据处理的三种语义: 最少一次(at least once): 流数据中的记录最少会被处理一次(1-n) 最多一次...
Spark Structured Streaming
Spark Structured Streaming 一、概述 http://spark.apache.org/docs/latest/structured-streaming-programming-guide.html 简单来说Spark Structured Streaming提供了流数据的快速、可靠、容错、端对端的精确一次处理语义,它是建立在SparkSQL基础之上的一个流数据处理引擎; ...
猜你喜欢

Structured Streaming基础入门
Structured Streaming 1. 回顾和展望 1.1. Spark 编程模型的进化过程 RDD 针对自定义数据对象进行处理, 可以处理任意类型的对象, 比较符合面向对象 RDD 无法感知到数据的结构, 无法针对数据结构进行编程 DataFrame DataFrame 保留有数据的元信息, API 针对数据的结构进行处理, 例如说可以根据数据的某一列进行排序或者分组 DataFrame...

Spark Structured Streaming
Spark Structured Streaming 概述 http://spark.apache.org/docs/latest/structured-streaming-programming-guide.html Structured Streaming构建在Spark SQL基础之上的一个可靠且容错的流数据处理引擎。 简短来说,Structured Streaming提供快速、可靠、容错、...

CV笔记03:自监督GAN(ss-gan)
无需标注数据,利用辅助性旋转损失的自监督GANs,-- 对抗+自监督的无监督方式 《通过辅助旋转损失进行的自监督GAN》CVPR 2019 论文速看 0.摘要 目前自然图像合成主要是条件GAN,但是其缺点是需要标注数据。 我们利用两种流行的无监督学习技术,对抗训练和自我监督,并朝着缩小有条件GAN和无条件GAN之间的差距迈出了一步。 我们允许网络在代表学习的任务上进行协作,同时相对于经典GAN博弈...

Retrofit(三)上传文件
想了想,觉得还是把自定义的东西放到最后再讲,所以讲下用Retrofit上传文件,就拿上传图片来说,因为上传图片我是想写一个专题的,包括以下: 1.上传图片操作 2.展示图片操作 3.选择图片操作 上传图片这篇讲,用Retrofit,之后我还想写一篇是用httpurlconnection的,因为用它会有个拼接的操作,只有经历过拼接才会更深刻的了解使用Http上传文件的过程。展示图片我其实已经写完了,...