opencv画坐标系(便于与世界坐标转化)、检测色块(目标物体)
标签: Python学习
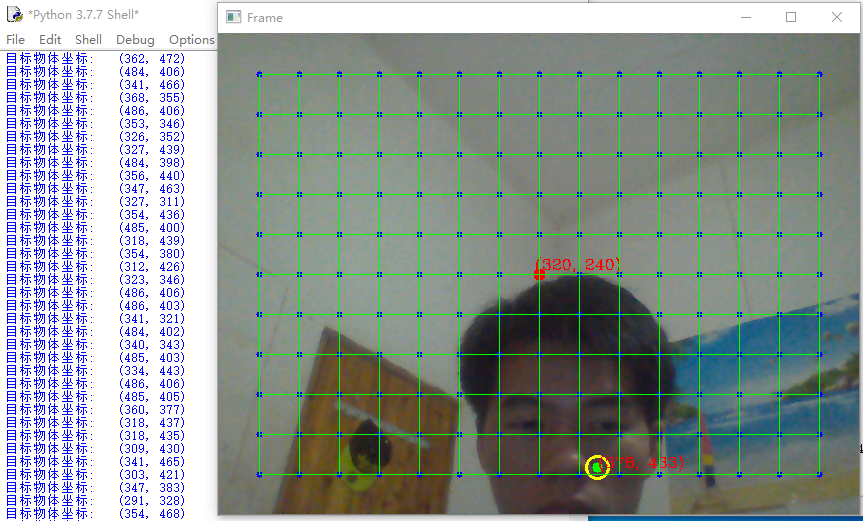
① 根据图像尺寸遍历出所有节点;
② 根据行列个数得出边界节点;
③ 画点、两点连线;
④ 将视野中心点特殊标记;
⑤ 实现当色块位于网格节点或者视野中心点时,显示坐标值在图像上;
⑥ 可调整网格间距,10、20或者40等可以被尺寸值整除的数
from collections import deque
import numpy as np
import cv2
import time
class Painter(object):
def __init__(self,img,start_point=(20,20)):
self.horizons_center = (0,0)
self.point_list = []
self.line_list = []
self.get_point_line(img,start_point)
def add_text(self,img,text,point,size=0.5,color=(0,0,255)):
cv2.putText(img,text,point,cv2.FONT_HERSHEY_COMPLEX,size,color,1)
return img
def draw_a_circle(self,img,point,radius=3,color=(255,0,0),thickness=2):
img = self.draw_a_point(img,point,radius,color,thickness)
return img
def draw_a_point(self,img,point,radius=3,color=(255,0,0),thickness=-4):
cv2.circle(img, point, radius, color, thickness)
return img
def draw_all_point(self,img):
for point in self.point_list:
if point == self.horizons_center:
img = self.draw_a_point(img,self.horizons_center,6,(0,0,255))
lable_point = (self.horizons_center[0]-5,self.horizons_center[1]-5)
img = self.add_text(img,str(self.horizons_center),lable_point)
else:
img = self.draw_a_point(img,point)
return img
def draw_a_line(self,img,start_point,end_point,color=(0,255,0),thickness=1,lineType=4):
cv2.line(img, start_point, end_point, color, thickness, lineType)
return img
def draw_all_line(self,img):
for point in self.line_list:
img = self.draw_a_line(img, point[0], point[1])
return img
def get_point_line(self,img,start_point):
start_value = start_point[0]
space = start_value
img_x,img_y = img.shape[1],img.shape[0]
self.horizons_center = (int(img_x/2),int(img_y/2))
for x_point in range(start_value,img_x,space):
for y_point in range(start_value,img_y,space):
self.point_list.append((x_point,y_point))
num_row = int((img_y-start_value)/space)
num_column = int((img_x-start_value)/space)
for j in range(1,num_column+1):
self.line_list.append(((j*space,start_value),(j*space,(img_y-space))))
for i in range(1,num_row+1):
self.line_list.append(((start_value,i*space),((img_x-space),i*space)))
class FindTarget(object):
def __init__(self):
self.redLower = np.array([156, 43, 46]) #设定红色阈值,HSV空间
self.redUpper = np.array([180, 255, 255])
self.target_position = (0,0)
self.target_radius = 0
cv2.namedWindow("camera",1)
self.camera = cv2.VideoCapture(0)
def get_one_flame(self):
ret,img = self.camera.read()
return ret,img
def start_find(self,img):
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV) #转到HSV空间
mask_red = cv2.inRange(hsv, self.redLower, self.redUpper) #根据阈值构建掩膜
mask_red = cv2.erode(mask_red, None, iterations=2) #腐蚀操作
mask_red = cv2.dilate(mask_red, None, iterations=2) #膨胀操作,其实先腐蚀再膨胀的效果是开运算,去除噪点
cnts_red = cv2.findContours(mask_red.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[-2] #轮廓检测
if len(cnts_red) > 0:
c = max(cnts_red, key=cv2.contourArea) #找到面积最大的轮廓
(red_x,red_y), self.target_radius = cv2.minEnclosingCircle(c)
self.target_position = (int(red_x),int(red_y))
return True,img
return False,img
def is_horizons_center(self,center):
x_low,x_high = center[0]-5,center[0]+5
y_low,y_high = center[1]-5,center[1]+5
x_target,y_target = self.target_position[0],self.target_position[1]
if x_low<x_target<x_high and y_low<y_target<y_high:
return True
return False
def is_target_on_node(self,point_list):
x_target,y_target = self.target_position[0],self.target_position[1]
for point in point_list:
if (point[0]-3)<x_target<(point[0]+3) and (point[1]-3)<y_target<(point[1]+3):
return True
return False
def show_result(self,img):
cv2.imshow('Frame', img)
def is_exit(self):
k = cv2.waitKey(5)&0xFF
if k == 27:
return True
return False
def close(self):
self.camera.release() #摄像头释放
cv2.destroyAllWindows()#销毁所有窗口
if __name__ == '__main__':
toFind = FindTarget()
ret,flame = toFind.get_one_flame()
if ret:
painter = Painter(flame,(40,40))
while True:
_,flame = toFind.get_one_flame()
result,flame = toFind.start_find(flame)
if result:
flame = painter.draw_a_circle(flame,toFind.target_position,int(toFind.target_radius),(0,255,255))
flame = painter.draw_a_point(flame,toFind.target_position,5,(0,255,0))
flame = painter.add_text(flame,str(toFind.target_position),toFind.target_position)
if toFind.is_horizons_center(painter.horizons_center):
flame = painter.add_text(flame,'arrive center point!',(30,30),1,(0,0,255))
if toFind.is_target_on_node(painter.point_list):
flame = painter.add_text(flame,'YES!',(550,30),1,(0,0,255))
print('目标物体坐标: ',toFind.target_position)
flame = painter.draw_all_point(flame)
flame = painter.draw_all_line(flame)
toFind.show_result(flame)
if toFind.is_exit():
break
else:
print ('No Camera')
toFind.close()
智能推荐

Python由放弃到入门,基础篇七(类)下
类的实例化 有感于现在python教程多如牛毛,且大多高不可攀,多次拜读而不得其门道,遂由入门到放弃。偶有机缘,得一不错教程,得以入门,现博客分享,想要获取完整教程,ff17328081445。 通过对比可以看到,实例化后再使用的格式,①是空着的,意思是这里不再需要@classmethod的声明,并且在第②处,把cls替换成了self。同时,实例化后再使用的格式,需要先赋值然后再调用(第③处): ...
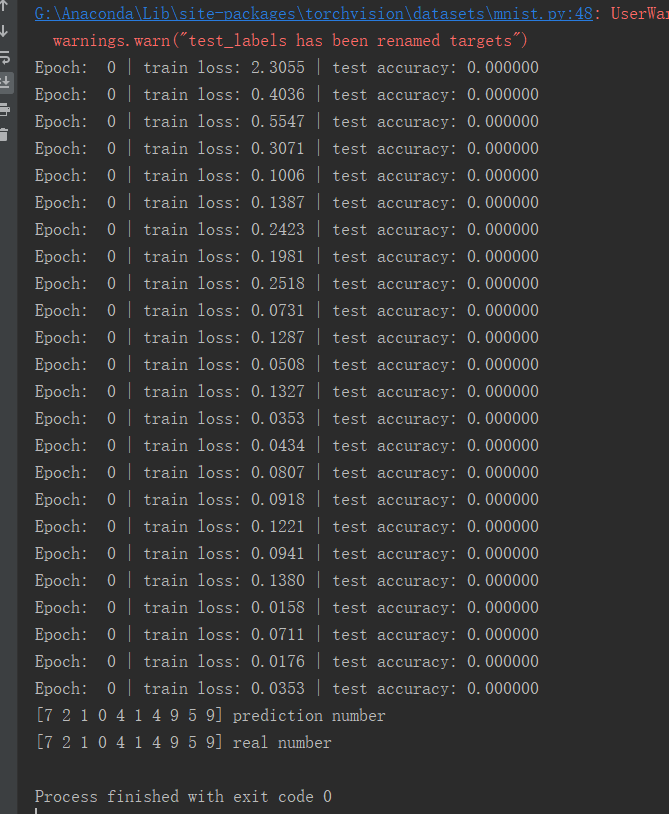
pytorch CNN手写字体识别
数据整体训练一次,对于accuracy都是0的问题,由于刚开始学,有些代码的细节我也没看懂,不过整体结果是对的,可能是由于pytorch版本的更新,导致accuracy的计算方式有所改变 内容转载自:https://www.bilibili.com/video/av15997678/?p=19...
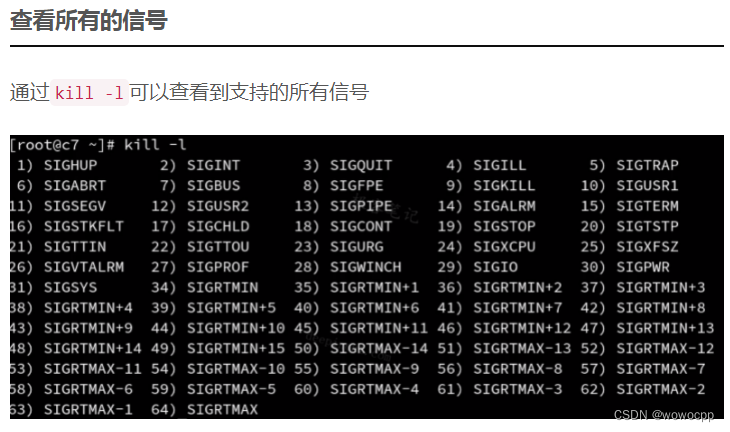
linux后台运行命令总结
linux后台运行命令总结 问题: 我们有时候需要登录远程服务器跑运行时间非常长的脚本,这个时候你要让脚本后台运行,不然占着终端窗口看着不舒服。但万一网络不好,(比如我这儿的破校园网,高峰时几秒钟断一次),终端突然和服务器之间的连接断了,那脚本就会自动停了(因为运行test.sh进程的父进程就是当前的shell终端进程,关闭当前shell终端时,父进程退出,会发送hangup信号给所有子进程,子进...
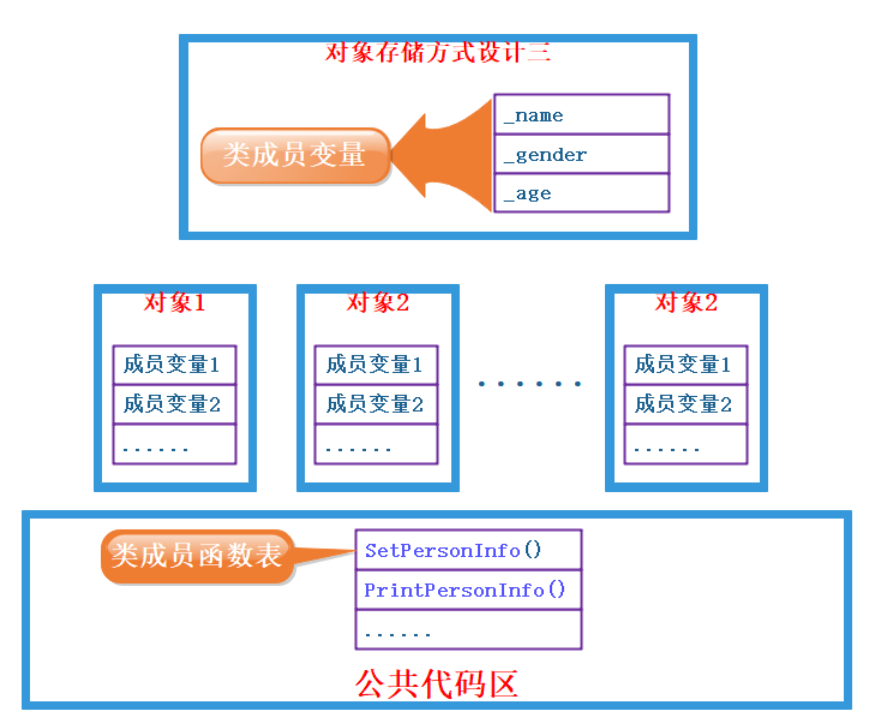
类对象模型和this指针
关于类/对象大小的计算 类只是一种类型定义,它本身是没有大小可言的。 我们这里指的类的大小,其实指的是类的对象所占的大小。因此,如果用sizeof运算符对一个类型名操作,得到的是具有该类型实体的大小。 首先,类大小的计算遵循结构体的对齐原则 类的大小与普通数据成员有关,与成员函数和静态成员无关。即普通成员函数,静态成员函数,静态数据成员,静态常量数据成员均对类的大小无影响 虚函数对类的大小有影响,...
猜你喜欢

3D人脸重建——PRNet网络输出的理解
前言 之前有款换脸软件不是叫ZAO么,分析了一下,它的实现原理绝对是3D人脸重建,而非deepfake方法,找了一篇3D重建的论文和源码看看。这里对源码中的部分函数做了自己的理解和改写。 国际惯例,参考博客: 什么是uv贴图? PRNet论文 PRNet代码 本博客主要是对PRNet的输出进行理解。 理论简介 这篇博客比较系统的介绍了3D人脸重建的方法,就我个人浅显的理解,分为两个流派:1.通过算...
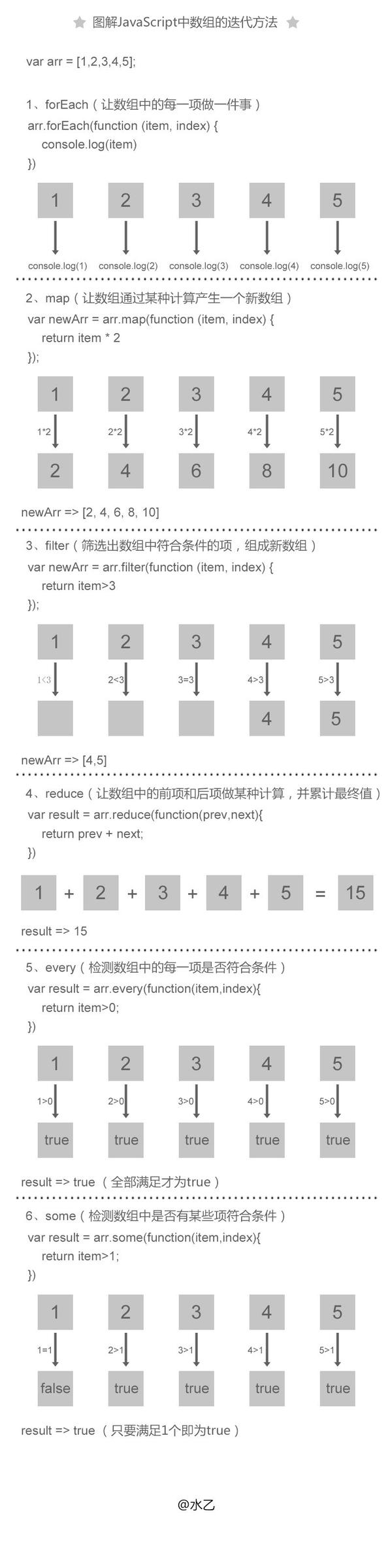
javascript简单的正则表达式入门
内容来自百度前端学院javascript入门课程 基本的HTML: 样式: javascript: document.write和innerHTML有什么区别 前者是直接将内容写入文档流,如果写入之前没有调用document.open,那么回自动调用document.open(每打开一次文档流都会清除之前的所有内容包括变量)。每次写完关闭后重新调用该函数的话,会导致页面重写。 innerHTML是...
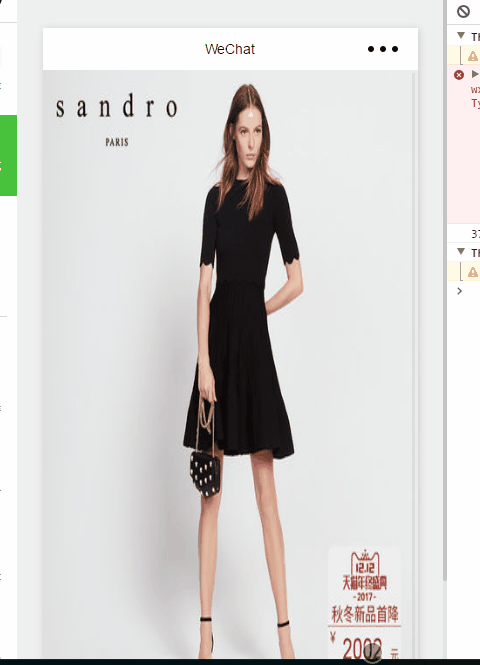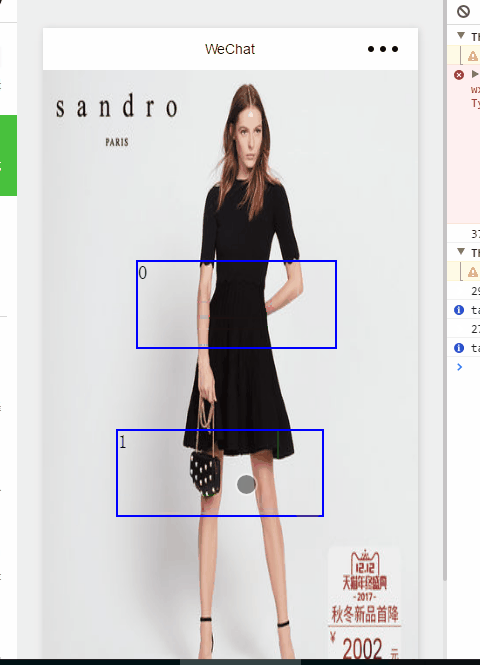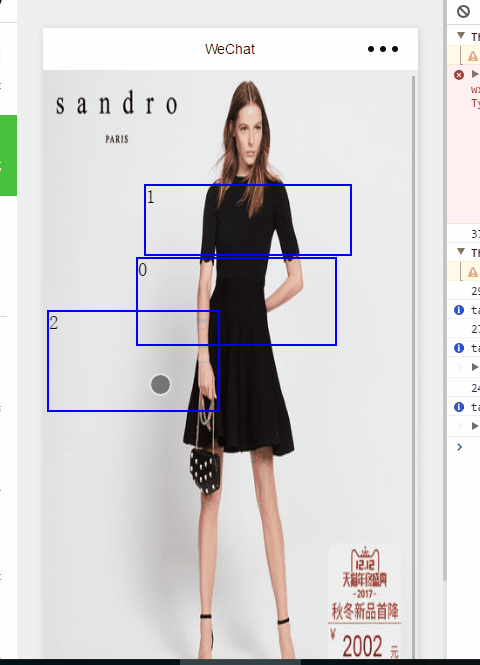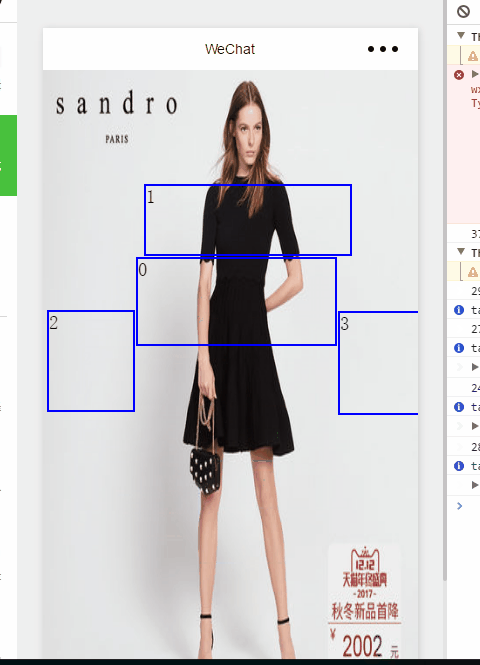
微信小程序一个你可能需要的功能
根据工作需要。需要做一个图片选中部分区域的效果。百度了很久,都没有见有。于是就自己写了个,需要的可以借鉴下,还有很多需要改善的地方 现在先看看效果 效果图 那这个有什么用呢。。需求是选中图片的某个区域然后给它添加注释。还可以有其他用处。那这个是怎么做到的呢 。。首先我说下基本的思路 ——-> 图片作为一个背景。然后上面是一层canvas 以及最上面生成的view 因为...
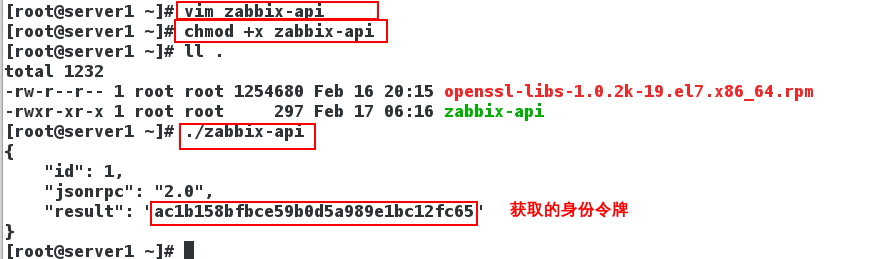
Linux Zabbix分布式监控 通过API接口远程 管理Zabbix所监控主机
一、API 1、什么是API API(Application Programming Interface,应用程序编程接口)是一些预先定义的函数,目的是提供应用程序与开发人员基于某软件或硬件得以访问一组例程的能力,而又无需访问源码,或理解内部工作机制的细节。 Zabbix API允许你以编程方式检索和修改Zabbix的配置,并提供对历史数据的访问。 它广泛用于: 创建新的应用程序以使用Zabbix...
java 调用博思得条码打印机
效果: 打印文字、二维码、图片 准备工作: 1)、JNative(JNative.jar、JNativeCpp.dll) 2)、博思得dll文件(CDFPSK.dll)和API文档 ...