3D人脸重建——PRNet网络输出的理解
标签: 论文理解 tensorflow 人脸重建 人工智能 图像处理
前言
之前有款换脸软件不是叫ZAO么,分析了一下,它的实现原理绝对是3D人脸重建,而非deepfake方法,找了一篇3D重建的论文和源码看看。这里对源码中的部分函数做了自己的理解和改写。
国际惯例,参考博客:
本博客主要是对PRNet的输出进行理解。
理论简介
这篇博客比较系统的介绍了3D人脸重建的方法,就我个人浅显的理解,分为两个流派:1.通过算法估算3DMM的参数,3DMM的思想是有一个平均脸,基于这个平均脸进行变形,就能得到任意的人脸,算法就需要计算这个变形所需要的参数;2. 直接摆脱平均脸的约束,直接使用神经网络去估算人脸的3D参数。
PRNet就是属于第二种流派,输入一张图片,直接使用神经网络输出一张称为UV position map的UV位置映射图。本博客就是为了对这个输出进行充分理解。先简短说一下,他的维度是的三位矩阵,前面两个维度上输出的纹理图的维度,最后一个维度表示纹理图每个像素在3D空间中的位置信息。
任何的3D人脸重建,包括3DMM,都需要得到顶点图和纹理图,这个在图形学里面很常见,比如我们看到的游戏角色就包括骨骼信息和纹理信息。
代码理解
首先引入必要的库:
import numpy as np
import os
from skimage.transform import estimate_transform, warp
import cv2
from predictor import PosPrediction
import matplotlib.pyplot as plt
这里有个额外的predictor库,是PRNet的网络结构,直接去这里下载。
还有一个文件夹需要下载,戳这里,这里面定义了UV图的人脸关键点信息uv_kpt_ind,预定义的人脸顶点信息face_ind,三角网格信息triangles。下面会分析他俩的作用。
人脸裁剪
因为源码使用dlib检测人脸关键点,其实目的是找到人脸框,然后裁剪人脸。由于在Mac上安装dlib有点难度,而前面的换脸博客刚好玩过用opencv检测人脸关键点。检测人脸框的代码如下:
## 预检测人脸框或者关键点,目的是裁剪人脸
cas = cv2.CascadeClassifier('./Data/cv-data/haarcascade_frontalface_alt2.xml')
img = plt.imread('./images/zly.jpg')
img_gray= cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
faces = cas.detectMultiScale(img_gray,2,3,0,(30,30))
bbox = np.array([faces[0,0],faces[0,1],faces[0,0]+faces[0,2],faces[0,1]+faces[0,3]])
可视化看看:
plt.imshow(cv2.rectangle(img.copy(),(bbox[0],bbox[1]),(bbox[2],bbox[3]),(0,255,0),2))
plt.axis('off')

裁剪人脸
left = bbox[0]; top = bbox[1]; right = bbox[2]; bottom = bbox[3]
old_size = (right - left + bottom - top)/2
center = np.array([right - (right - left) / 2.0, bottom - (bottom - top) / 2.0])
size = int(old_size*1.6)
src_pts = np.array([[center[0]-size/2, center[1]-size/2],
[center[0] - size/2, center[1]+size/2],
[center[0]+size/2, center[1]-size/2]])
DST_PTS = np.array([[0,0], [0,255], [255, 0]]) #图像大小256*256
tform = estimate_transform('similarity', src_pts, DST_PTS)
img = img/255.
cropped_img = warp(img, tform.inverse, output_shape=(256, 256))
可视化看看
plt.imshow(cropped_img)
plt.axis('off')

网络推断
载入网络结构
pos_predictor = PosPrediction(256, 256)
pos_predictor.restore('./Data/net-data/256_256_resfcn256_weight')
直接把裁剪后的图片输入到网络中,推导UV位置映射图
cropped_pos = pos_predictor.predict(cropped_img) #网络推断
因为这个结果是裁剪过的图的重建,所以在重新调整一下,缩放到之前的图大小:
#将裁剪图的结果重新调整
cropped_vertices = np.reshape(cropped_pos, [-1, 3]).T
z = cropped_vertices[2,:].copy()/tform.params[0,0]
cropped_vertices[2,:] = 1
vertices = np.dot(np.linalg.inv(tform.params), cropped_vertices)
vertices = np.vstack((vertices[:2,:], z))
pos = np.reshape(vertices.T, [256, 256, 3])
这里不太好可视化,只看看这个深度信息,也就是第三个通道:
plt.imshow(pos[...,2],cmap='gray')
plt.axis('off')
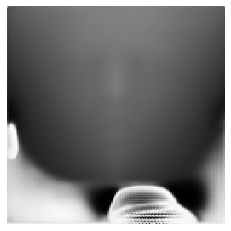
很明显,这个是能看出来脸部的不同位置,颜色深浅不同,鼻子的高度最高,所以比较白一点。
人脸关键点
需要注意的是,论文所生成的所有人脸的texture都符合uv_face.png所有器官位置,比如鼻子一定会在texutre的鼻子那里,不管你是侧脸还是正脸,uv_kpt_ind.txt这里面定义的就是texture的人脸关键点位置,是固定的。
uv_kpt_ind = np.loadtxt('./Data/uv-data/uv_kpt_ind.txt').astype(np.int32)
uv_face = plt.imread('./Data/uv-data/uv_face.png')
plt.imshow(draw_kps(uv_face,uv_kpt_ind.T))
plt.axis('off')

记住,所有的人脸texture都满足这个布局,所有器官一定出现在上图的对应位置。至于怎么获取texture,后面会介绍。
前面说了,网络输出的UV位置映射图,前面两个是texture的位置,最后一个维度上texutre在3D图上的位置。所以根据uv_kpt_ind和UV位置映射图能找到人脸图(非纹理图)上的关键点
def draw_kps(img,kps,point_size=2):
img = np.array(img*255,np.uint8)
for i in range(kps.shape[0]):
cv2.circle(img,(int(kps[i,0]),int(kps[i,1])),point_size,(0,255,0),-1)
return img
face_kps = pos[uv_kpt_ind[1,:],uv_kpt_ind[0,:],:]
可视化看看
plt.imshow(draw_kps(img.copy(),face_kps))
plt.axis('off')

人脸点云
可视化了人脸关键点,顺带将face_ind里面定义的所有顶点全可视化一下。
直接从face_ind读到所有需要的顶点信息
face_ind = np.loadtxt('./Data/uv-data/face_ind.txt').astype(np.int32)
all_vertices = np.reshape(pos, [256*256, -1])
vertices = all_vertices[face_ind, :]
根据texture上定义的位置信息,可视化原人脸图信息:
plt.figure(figsize=(8,8))
plt.imshow(draw_kps(img.copy(),vertices[:,:2],1))
plt.axis('off')

顺便也可以看看3D图
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure()
ax1 = plt.axes(projection='3d')
ax1.scatter3D(vertices[:,2],vertices[:,0],vertices[:,1], cmap='Blues') #绘制散点图
ax1.set_xlabel('X Label')
ax1.set_ylabel('Y Label')
ax1.set_zlabel('Z Label')
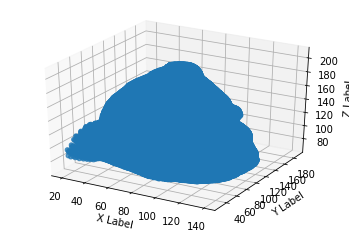
都糊一起了,但是能大概看出来人脸模型。
提取纹理图
上面说了,所有的人脸经过网络得到的texture都满足uv_face.png中的器官位置。
怎么根据UV位置映射图获取texture呢?一个函数remap:
texture = cv2.remap(img, pos[:,:,:2].astype(np.float32), None, interpolation=cv2.INTER_NEAREST, borderMode=cv2.BORDER_CONSTANT,borderValue=(0))
可视化texture和固定的uv_kpt_ind看看:
plt.imshow(draw_kps(texture,uv_kpt_ind.T))
plt.axis('off')

因为使用的图片上赵丽颖的正脸,所以侧面的texture不清晰,但是正脸的五官位置的确如所料,在固定的位置上出现。
渲染纹理图/3D人脸
能用一句话把纹理图获取到,那么我们就能根据texture和顶点位置将纹理图重建为3D图。原理就是利用triangles.txt定义的网格信息,获取每个网格的颜色,再把颜色贴到对应的3D位置。
首先从texture中找到每个顶点的肤色:
#找到每个三角形每个顶点的肤色
triangles = np.loadtxt('./Data/uv-data/triangles.txt').astype(np.int32)
all_colors = np.reshape(texture, [256*256, -1])
colors = all_colors[face_ind, :]
print(vertices.shape) # texutre每个像素对应的3D坐标
print(triangles.shape) #每个三角网格对应的像素索引
print(colors.shape) #每个三角形的颜色
'''
(43867, 3)
(86906, 3)
(43867, 3)
'''
获取每个三角网格的3D位置和贴图颜色:
#获取三角形每个顶点的depth,平均值作为三角形高度
tri_depth = (vertices[triangles[:,0],2 ] + vertices[triangles[:,1],2] + vertices[triangles[:,2],2])/3.
#获取三角形每个顶点的color,平均值作为三角形颜色
tri_tex = (colors[triangles[:,0] ,:] + colors[triangles[:,1],:] + colors[triangles[:,2],:])/3.
tri_tex = tri_tex*255
接下来对每个三角网格进行贴图,这里和源码不同,我用了opencv的画图函数来填充三角网格的颜色
img_3D = np.zeros_like(img,dtype=np.uint8)
for i in range(triangles.shape[0]):
cnt = np.array([(vertices[triangles[i,0],0],vertices[triangles[i,0],1]),
(vertices[triangles[i,1],0],vertices[triangles[i,1],1]),
(vertices[triangles[i,2],0],vertices[triangles[i,2],1])],dtype=np.int32)
img_3D = cv2.drawContours(img_3D,[cnt],0,tri_tex[i],-1)
plt.imshow(img_3D/255.0)

旋转人脸
既然我们获取的是3D人脸,当然可以对他进行旋转操作咯,可以绕x、y、z三个坐标轴分别旋转,原理就是旋转所有顶点的定义的3D信息,也就是UV位置映射的最后一个维度定义的坐标。
通过旋转角度计算旋转矩阵的方法是:
# 找到旋转矩阵,参考https://github.com/YadiraF/face3d
def angle2matrix(angles):
x, y, z = np.deg2rad(angles[0]), np.deg2rad(angles[1]), np.deg2rad(angles[2])
# x
Rx=np.array([[1, 0, 0],
[0, np.math.cos(x), -np.math.sin(x)],
[0, np.math.sin(x), np.math.cos(x)]])
# y
Ry=np.array([[ np.math.cos(y), 0, np.math.sin(y)],
[ 0, 1, 0],
[-np.math.sin(y), 0, np.math.cos(y)]])
# z
Rz=np.array([[np.math.cos(z), -np.math.sin(z), 0],
[np.math.sin(z), np.math.cos(z), 0],
[ 0, 0, 1]])
R=Rz.dot(Ry.dot(Rx))
return R.astype(np.float32)
绕垂直方向旋转30度,调用方法就是
trans_mat = angle2matrix((0,30,0))
旋转顶点位置
# 旋转坐标
rotated_vertices = vertices.dot(trans_mat.T)
因为是绕远点旋转,搞不好会旋转出去,所以要矫正一下位置
# 把图像拉到画布上
ori_x = np.min(vertices[:,0])
ori_y = np.min(vertices[:,1])
rot_x = np.min(rotated_vertices[:,0])
rot_y = np.min(rotated_vertices[:,1])
shift_x = ori_x-rot_x
shift_y = ori_y-rot_y
rotated_vertices[:,0]=rotated_vertices[:,0]+shift_x
rotated_vertices[:,1]=rotated_vertices[:,1]+shift_y
老样子把texture可视化:
img_3D = np.zeros_like(img,dtype=np.uint8)
mask = np.zeros_like(img,dtype=np.uint8)
fill_area=0
for i in range(triangles.shape[0]):
cnt = np.array([(rotated_vertices[triangles[i,0],0],rotated_vertices[triangles[i,0],1]),
(rotated_vertices[triangles[i,1],0],rotated_vertices[triangles[i,1],1]),
(rotated_vertices[triangles[i,2],0],rotated_vertices[triangles[i,2],1])],dtype=np.int32)
mask = cv2.drawContours(mask,[cnt],0,(255,255,255),-1)
if(np.sum(mask[...,0])>fill_area):
fill_area = np.sum(mask[...,0])
img_3D = cv2.drawContours(img_3D,[cnt],0,tri_tex[i],-1)
plt.imshow(img_3D)

从视觉效果上的确是旋转过了。
后记
本博客主要是验证了PRNet网络输出的各种信息代表什么意思。
后面的研究可能会分为:
- 网络结构的研究
- 换脸
当然,博客源码
链接: https://pan.baidu.com/s/18z2b6Sut6qFecOpGqNc8YA
提取码: ad77
智能推荐
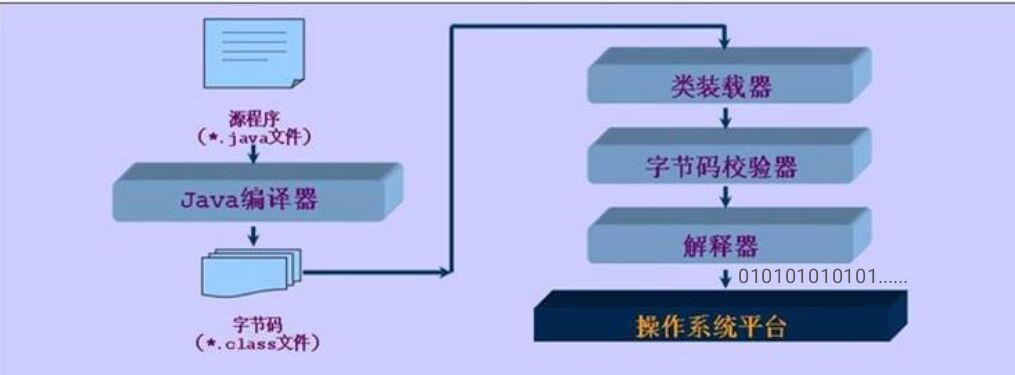
Java运行原理
1.Java运行原理 我们可通过文本编辑板生成Java源代码(.java)经过dos窗口由Java编译器(javac.exe)生成字节码文件(.class),字节码可由Java虚拟机转化为机器码供计算机读取处理。由于Java可以生成字节码可供虚拟机转译所以可跨平台运行。运行过程如下: 所以相对于C语言还需要转化为exe文件才能运行的权限,Java具有跨平台...

Python由放弃到入门,基础篇七(类)下
类的实例化 有感于现在python教程多如牛毛,且大多高不可攀,多次拜读而不得其门道,遂由入门到放弃。偶有机缘,得一不错教程,得以入门,现博客分享,想要获取完整教程,ff17328081445。 通过对比可以看到,实例化后再使用的格式,①是空着的,意思是这里不再需要@classmethod的声明,并且在第②处,把cls替换成了self。同时,实例化后再使用的格式,需要先赋值然后再调用(第③处): ...
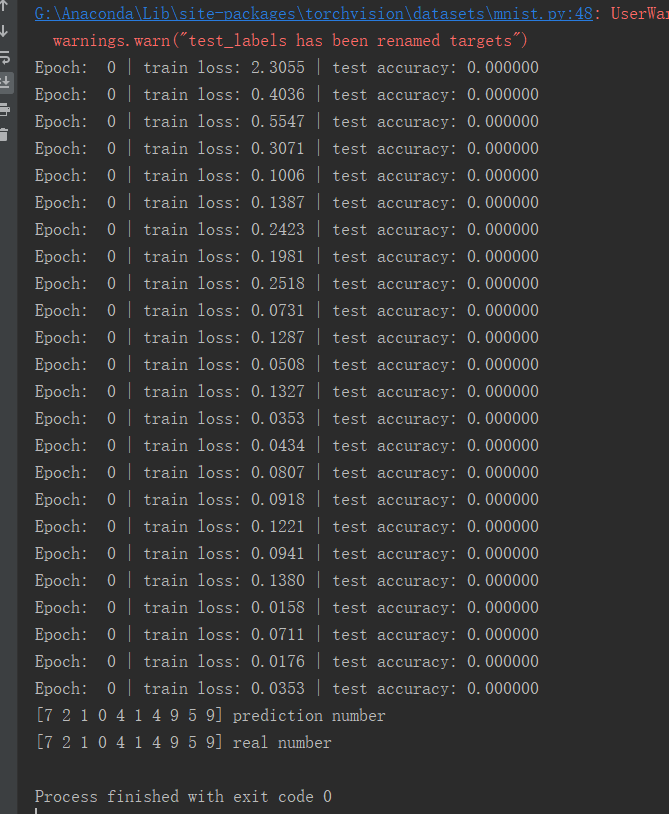
pytorch CNN手写字体识别
数据整体训练一次,对于accuracy都是0的问题,由于刚开始学,有些代码的细节我也没看懂,不过整体结果是对的,可能是由于pytorch版本的更新,导致accuracy的计算方式有所改变 内容转载自:https://www.bilibili.com/video/av15997678/?p=19...
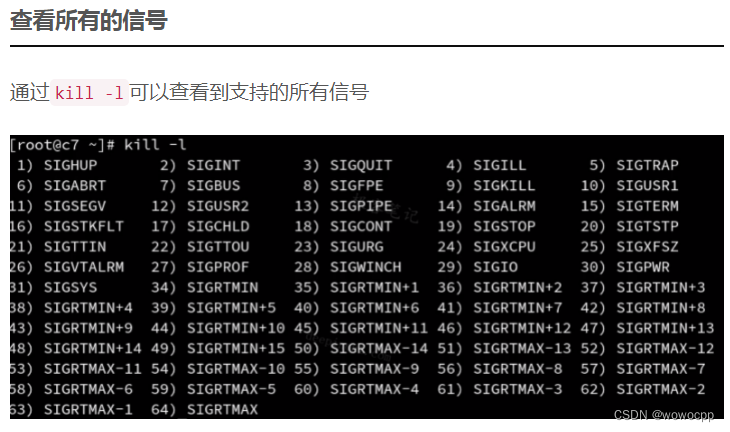
linux后台运行命令总结
linux后台运行命令总结 问题: 我们有时候需要登录远程服务器跑运行时间非常长的脚本,这个时候你要让脚本后台运行,不然占着终端窗口看着不舒服。但万一网络不好,(比如我这儿的破校园网,高峰时几秒钟断一次),终端突然和服务器之间的连接断了,那脚本就会自动停了(因为运行test.sh进程的父进程就是当前的shell终端进程,关闭当前shell终端时,父进程退出,会发送hangup信号给所有子进程,子进...
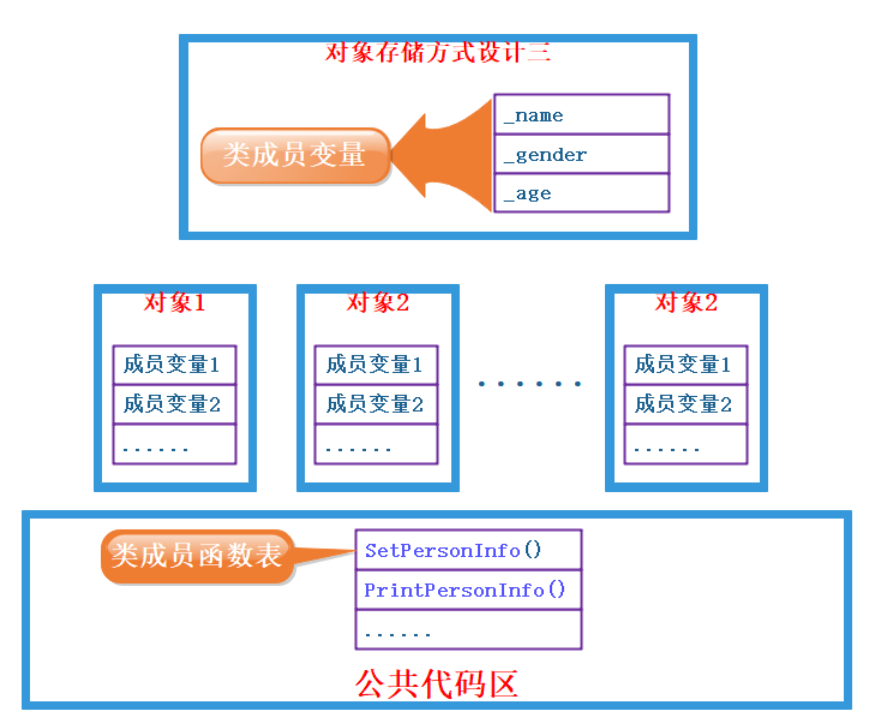
类对象模型和this指针
关于类/对象大小的计算 类只是一种类型定义,它本身是没有大小可言的。 我们这里指的类的大小,其实指的是类的对象所占的大小。因此,如果用sizeof运算符对一个类型名操作,得到的是具有该类型实体的大小。 首先,类大小的计算遵循结构体的对齐原则 类的大小与普通数据成员有关,与成员函数和静态成员无关。即普通成员函数,静态成员函数,静态数据成员,静态常量数据成员均对类的大小无影响 虚函数对类的大小有影响,...
猜你喜欢
3D人脸重建——PRNet网络输出的理解
前言 之前有款换脸软件不是叫ZAO么,分析了一下,它的实现原理绝对是3D人脸重建,而非deepfake方法,找了一篇3D重建的论文和源码看看。这里对源码中的部分函数做了自己的理解和改写。 国际惯例,参考博客: 什么是uv贴图? PRNet论文 PRNet代码 本博客主要是对PRNet的输出进行理解。 理论简介 这篇博客比较系统的介绍了3D人脸重建的方法,就我个人浅显的理解,分为两个流派:1.通过算...
javascript简单的正则表达式入门
内容来自百度前端学院javascript入门课程 基本的HTML: 样式: javascript: document.write和innerHTML有什么区别 前者是直接将内容写入文档流,如果写入之前没有调用document.open,那么回自动调用document.open(每打开一次文档流都会清除之前的所有内容包括变量)。每次写完关闭后重新调用该函数的话,会导致页面重写。 innerHTML是...
微信小程序一个你可能需要的功能
根据工作需要。需要做一个图片选中部分区域的效果。百度了很久,都没有见有。于是就自己写了个,需要的可以借鉴下,还有很多需要改善的地方 现在先看看效果 效果图 那这个有什么用呢。。需求是选中图片的某个区域然后给它添加注释。还可以有其他用处。那这个是怎么做到的呢 。。首先我说下基本的思路 ——-> 图片作为一个背景。然后上面是一层canvas 以及最上面生成的view 因为...
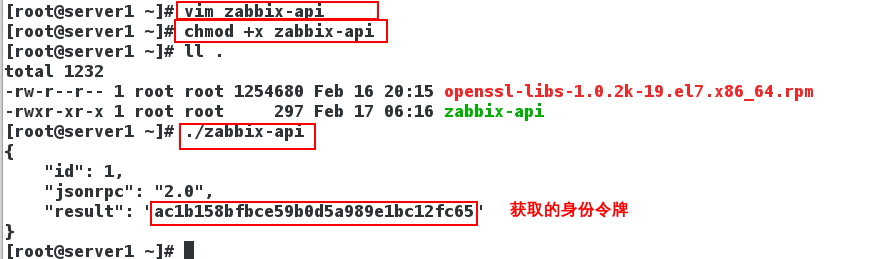
Linux Zabbix分布式监控 通过API接口远程 管理Zabbix所监控主机
一、API 1、什么是API API(Application Programming Interface,应用程序编程接口)是一些预先定义的函数,目的是提供应用程序与开发人员基于某软件或硬件得以访问一组例程的能力,而又无需访问源码,或理解内部工作机制的细节。 Zabbix API允许你以编程方式检索和修改Zabbix的配置,并提供对历史数据的访问。 它广泛用于: 创建新的应用程序以使用Zabbix...