Python药店销售数据分析
标签: python
分析目标:根据药店销售数据,分析药品销售关键指标,以及药品销售趋势
1. 导入并清理数据
import pandas as pd
# 以object形式输入数据可保持数据原始形状,之后可用astype()转换数据格式
sale_data=pd.read_excel('药店2018年销售数据.xlsx',0,dtype='object')
# 1. 列名重置:更改购药时间为销售时间
dfrename = {"购药时间":"销售时间"}
sale_data.rename(columns=dfrename,inplace=True)
# 2. 处理缺失值
# 查找缺失值
sale_data.isnull().sum()
# 删除缺失值
sale_df=sale_data.dropna(subset=['销售时间','社保卡号'],how='any',axis=0)
sale_df.shape
# 删除缺失值后需重设索引,加drop=True可将原索引删除,否则原索引将保存为列名为index的一列
sale_df=sale_df.reset_index(drop=True)
# 3. 提取数据并转换数据格式
# 将销售数量,应收金额,实收金额转换成浮点型
sale_df['销售数量']=sale_df['销售数量'].astype('float')
sale_df['应收金额']=sale_df['应收金额'].astype('float')
sale_df['实收金额']=sale_df['实收金额'].astype('float')
sale_df.dtypes
# 4. 处理日期数据
# 提取销售时间
date = pd.DataFrame(sale_df['销售时间'].apply(lambda s: s.split(" ")).values.tolist(),columns=['日期','星期'])
# 将日期的object类型转换成日期类型
# 加errors='coerce',如果原始数据不符合日期的格式,转换后的值为空值NaT
date['日期']=pd.to_datetime(date['日期'],format='%Y-%m-%d',errors='coerce')
sale_df1 = sale_df
sale_df1['销售日期']=date['日期']
sale_df1['销售星期']=date['星期']
# 转换日期格式时,不符合日期格式的会转换成空值,删除空值行
sale_df1 = sale_df1.dropna(subset=['销售日期'],how='any')
# 重置index
sale_df1=sale_df1.reset_index(drop=True)
# 5. 按日期排序
sale_df1=sale_df1.sort_values(by='销售日期',ascending=True)
# 重置index
sale_df1=sale_df1.reset_index(drop=True)
# 6.异常值处理
# 查看有无异常值
sale_df1.describe()
# “销售数量“,”金额“ 最小值不能低于0
print("删除异常值前:",sale_df1.shape)
querySer = sale_df1.loc[:,'销售数量']>0
sale_df2 = sale_df1.loc[querySer,:]
print("删除异常值后:",sale_df2.shape)2. 分析数据
a. 计算关键指标:每月平均消费次数,每月平均消费金额,客单价
'''
业务指标1:月均消费次数=每月消费次数平均值
条件:同一人同一天发生的所有消费视作一次
方法:”销售日期“和”社保卡号“若同时相同,则只保留一项计数
'''
kpi1 = sale_df2.drop_duplicates(subset=['销售日期','社保卡号'])
# 按时间顺序排序
kpi1 = kpi1.sort_values(by='销售日期',ascending=True)
# 重置索引
kpi1=kpi1.reset_index(drop=True)
kpi1.shape
kpi1['消费次数']=1
kpi = kpi1
kpi.index=kpi['销售日期']
# 用groupby统计每月消费数据
gb=kpi.groupby(kpi.index.month)
MonSales=gb.sum()
# 月均消费次数 kpi_1
kpi_1 = MonSales['消费次数'].loc[:6].mean()
# 月均销售金额 kpi_2
kpi_2 = MonSales['实收金额'].loc[:6].mean()
# 客单价 kpi_3
kpi_3 = MonSales['实收金额'].sum()/MonSales['消费次数'].sum()
b. 比较各时段消费情况:
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei']
# 每月消费情况对比
f,ax1 = plt.subplots()
MonSales.plot(x=MonSales.index,y=['消费次数'],ax=ax1)
MonSales.plot(x=MonSales.index,y=['实收金额'],ax=ax1,secondary_y=True)
# 星期数据处理
kpi2 = kpi1
gb2 = kpi2.groupby(by='销售星期')
WeekSales=gb2.sum()
WeekSales.index=[1,3,2,5,6,4,7]
WeekSales.sort_index(inplace = True)
# 星期消费情况对比
f,ax2 = plt.subplots()
WeekSales.plot(x=WeekSales.index,y='消费次数',ax=ax2)
WeekSales.plot(x=WeekSales.index,y='实收金额',ax=ax2,secondary_y=True)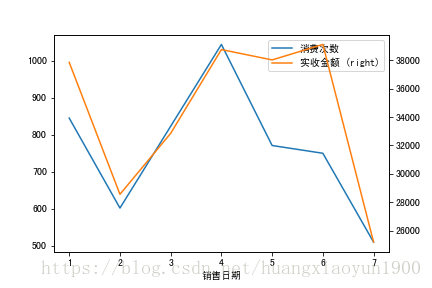
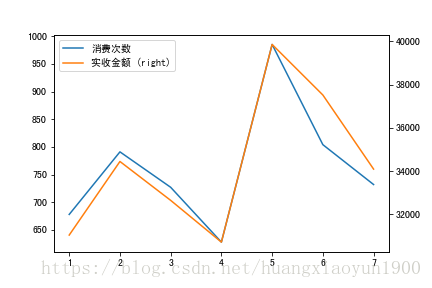
由上图可知:
1. 在月份销售对比中,2月药店销售金额较其他月有明显的下降(7月数据只到7月19日,故不做整体比较),4,5,6月药店销售金额均在38000以上。
2. 在月份销售对比中,4月消费次数最多,但实收金额并不是最高,说明客单次消费相比6月较低。
3. 在星期销售对比中,消费次数和消费金额总体趋势一致,周五为全星期消费次数和消费金额之最,周六次之。周四则消费最少。
c. 销售药品统计
帕累托图
# 根据销售商品名称groupby,排序销售数量,选出Top10
gb3 = pd.DataFrame(sale_df2.groupby(['商品名称']).sum()['销售数量'])
SaleQuantity=gb3.sort_values(by='销售数量',ascending=False)
TotalSales=SaleQuantity['销售数量'].sum()
# 计算百分比
SaleQuantity['Percentage']=SaleQuantity['销售数量']/TotalSales
SaleQuantity['AcmPerc'] = -1
# 计算累计百分比
for i in range(len(SaleQuantity.index)):
if i == 0:
SaleQuantity['AcmPerc'].iloc[0]=SaleQuantity['Percentage'].iloc[0]
else:
SaleQuantity['AcmPerc'].iloc[i]=SaleQuantity['Percentage'].iloc[i]+SaleQuantity['AcmPerc'].iloc[i-1]
Top_Sales=SaleQuantity[:10]
f,ax3=plt.subplots()
Top_Sales.plot(x=Top_Sales.index,y='销售数量',ax=ax3,kind='bar',title='销售前十',grid=True,rot=70)
ax4 = ax3.twinx()
Top_Sales.plot(x=Top_Sales.index,y='AcmPerc',kind='line',ax=ax4,secondary_y=True,marker='o',rot=70)
for a,b in zip(range(10),Top_Sales['AcmPerc']):
plt.text(a,b,'%.2f%%'%(b*100),ha='center',va='bottom')
ax3.legend(loc='upper center')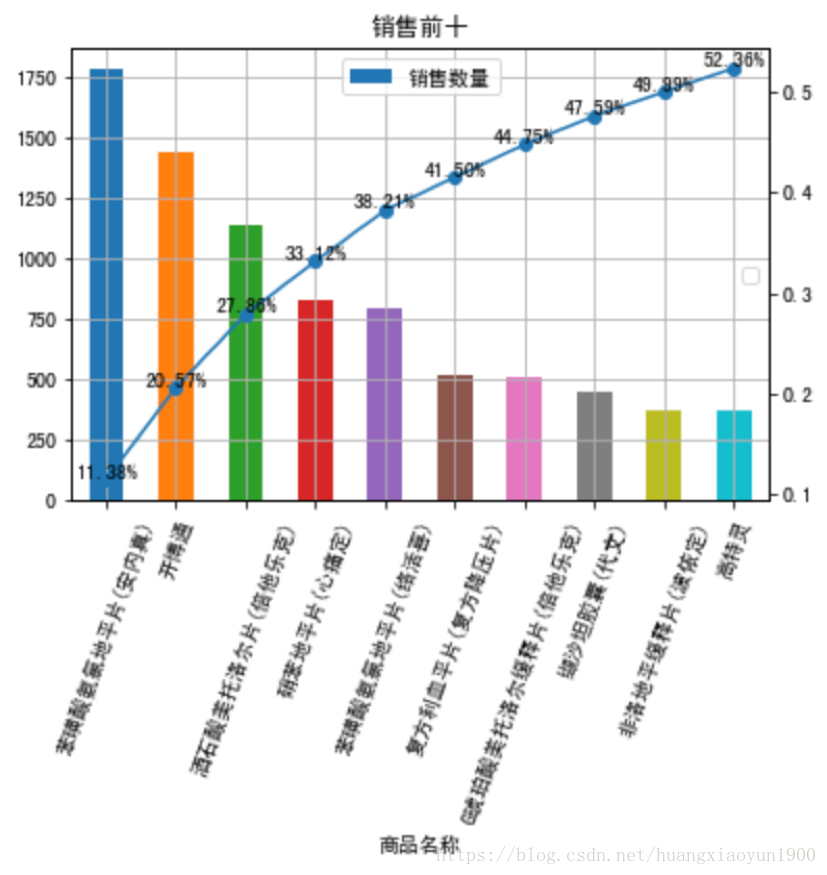
销售前十的药品如上图所示,且销售前十的药品销售数量占总销售数量的52%。
针对以上数据,还有很多可分析的内容,例如,是否有某药品集中在某一时期被购买的情况,哪些药品通常会被大规模购买,哪些药品在近一年内销售非常少可以适当减少采购量,需根据具体需求具体分析,在此就不再赘述。
智能推荐
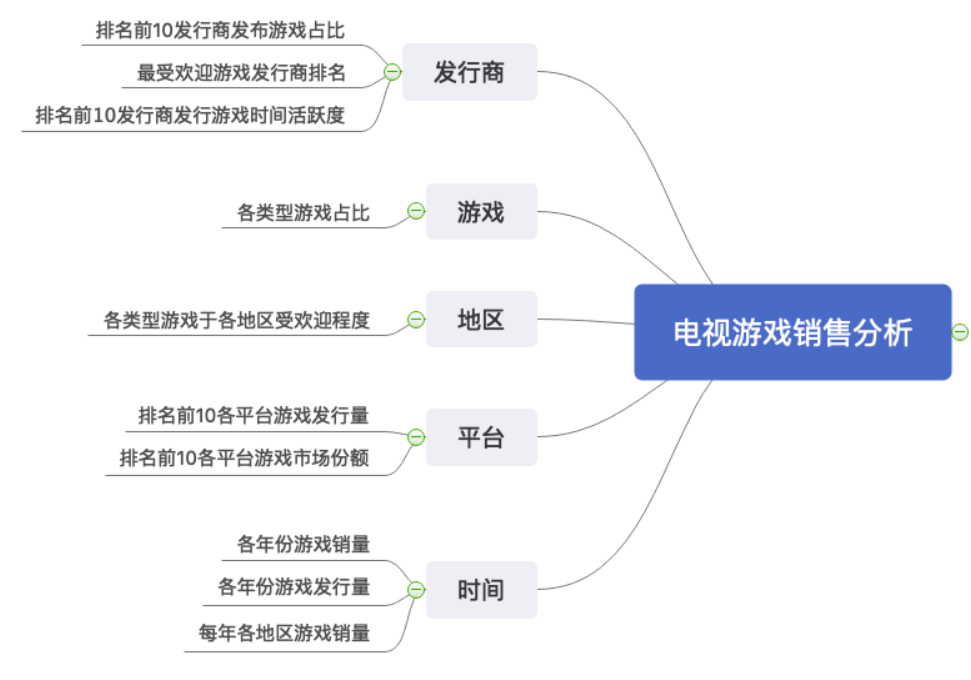
主机游戏销售数据分析练习
主机游戏销售数据分析练习 数据读取与预处理 发行商角度 排名前10各发行商发布游戏占比 最受欢迎游戏发行商排名 排名前10发行商发行游戏时间活跃度 游戏角度 各类型游戏占比 地区角度 各类型游戏于各地区受欢迎程度 平台角度 排名前10各平台游戏发行量 & 销售额(市场份额) 时间角度 各年份游戏销量 & 各年份游戏发行量 每年各地区游戏销量 这份数据集是一张包含销量超过10万份的电...

Python天猫双十一美妆销售数据分析
本文来源 KathyZhu - 天猫双十一美妆销售数据分析 - kesci.com 点击以上链接,不用配置环境,直接在线运行 本文数据集链接:Tmall_makeup - 采集了2016年双十一化妆品的销量信息 一、读取数据 out[]:(27598, 7) 二、数据清洗 2.1 重复数据处理 out:(27512, 7) 2.2 缺失值处理 有两列数据存在缺失值:sale_count, comm...


电子游戏销售数据分析(基于Python+Tableau)
1 项目简介 1.1 数据描述 (1)数据来源 本次分析所采用的数据来源于kaggle上的Video Game Sales数据集 ,该数据集通过爬虫从vgchartzwangz网站上获取,主要描述了全球市场上电子游戏的一个销售情况。电子游戏(Video Games,少部分学者使用Electronic Games)又称电玩游戏(简称电玩),是指所有依托于电子设备平台而运行的交互游戏。根据媒介的不同多...
安卓:通过BaseAdapter适配器对ListView组件的简单应用案例
项目结果演示: 案例实现流程: 在布局文件中新建一个ListView组件 ↓ 在另一个布局文件中新建一个用于展示的布局文件 ↓ 在java文件中新建实体类Student ↓ 在java文件中新建StudentApdater继承BaseAdapter并覆写相关方法(重点:覆写getView方法) ↓ 通过LinkedList插入数据 ↓ 调用自己定义...
猜你喜欢
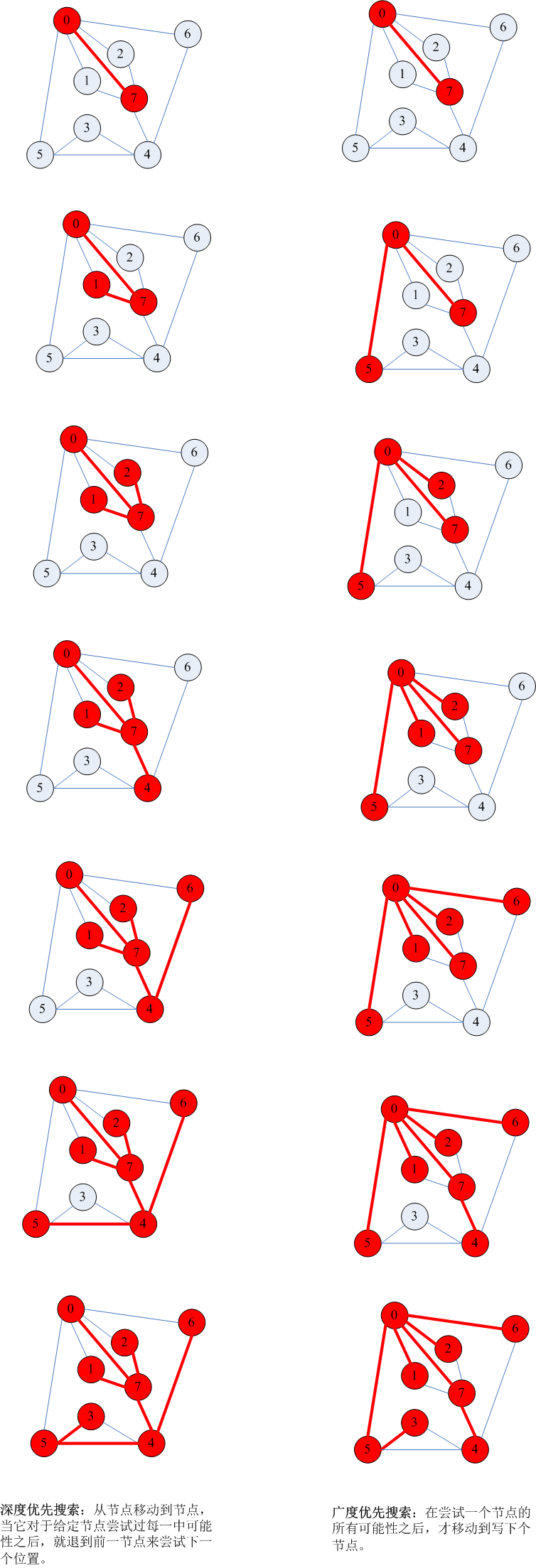
递归与树(三)
图的遍历: 深度优先搜索 从任意节点开始, 访问v。 (递归的)访问每一个依附于v的(未访问过的)节点。 如果图是连通的,我们最终可以到达所有的节点。 深度优先搜索递归实现: 要访问图中与节点k相连的所有节点,我们将它标记为访问过的,然后递归的访问k的邻接表中所有未访问过的节点。 void traverse(link k,void (*visit)(int)) { li...
博客运用Hexo-Next主题美化(上)
–此篇文章有转载,转载url放在最后方 1、前言 上篇文章已经在Windows上将个人博客个搭建好了(如果还不知道怎么搭建的,可以戳这里,可是大家有没有发现,搭建的Hexo博客使用的是默认主题,而且不咋好看,跟那些大神们的个人博客相比,还差了很多,不过不要紧,看完这篇文章,你也可以拥有那些炫酷吊炸天的效果。废话少说,那就直接开始吧。 2、设置主题 Hexo给我们提供了很多的主题供我...
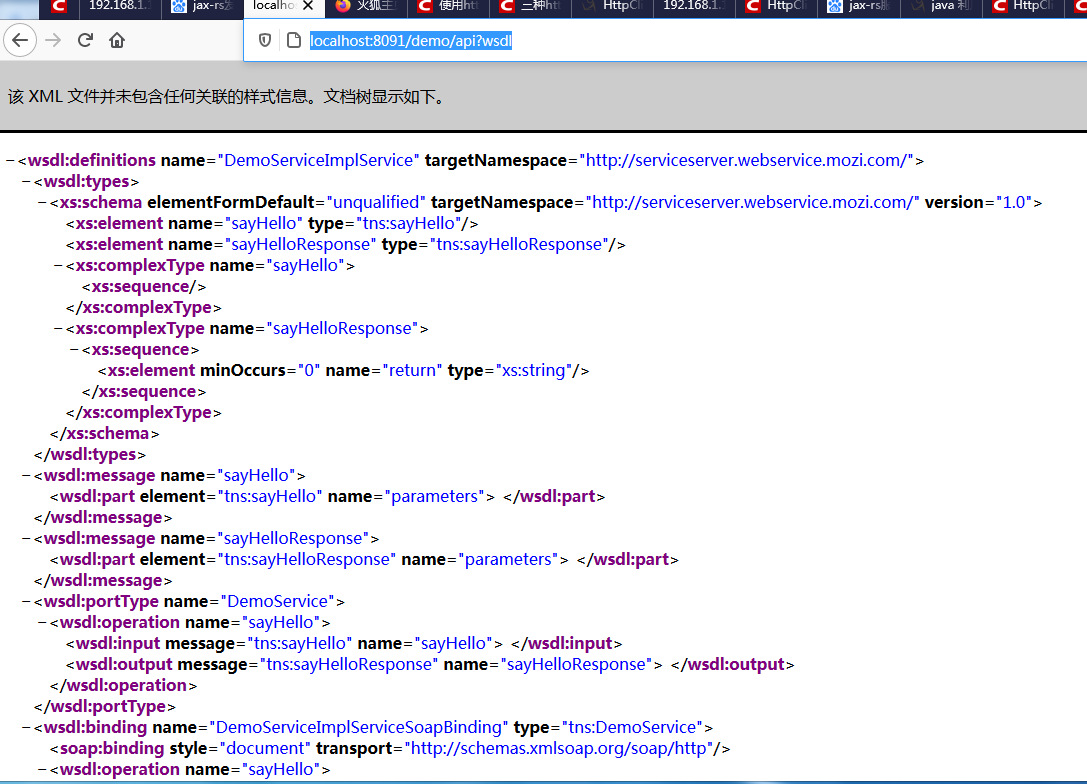
spring-boot整合jax-ws发布服务
第一步:导入依赖 第二步:创建接口 第三步:创建实现类 第四部:创建配置类 第五部:启动项目,访问http://localhost:8091/demo/api?wsdl 显示效果如下,则发布成功...
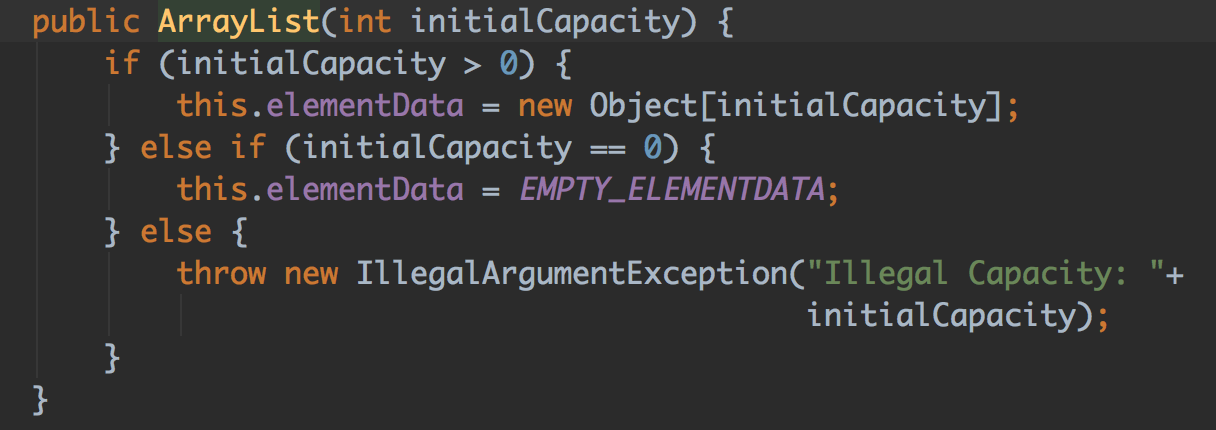
ArrayList中的迷惑行为
当我准备利用ArrayList的add(index,element)方法时遇到一个郁闷的结果。 废话不多说,show time 我现在需要满足一个需求,就是希望利用arrayList可以将本来的无序的元素添加到对应的index下 执行后: java.lang.IndexOutOfBoundsException: Index: 3, Size: 0 ArrayList初始化源码 因为初始化的 arr...
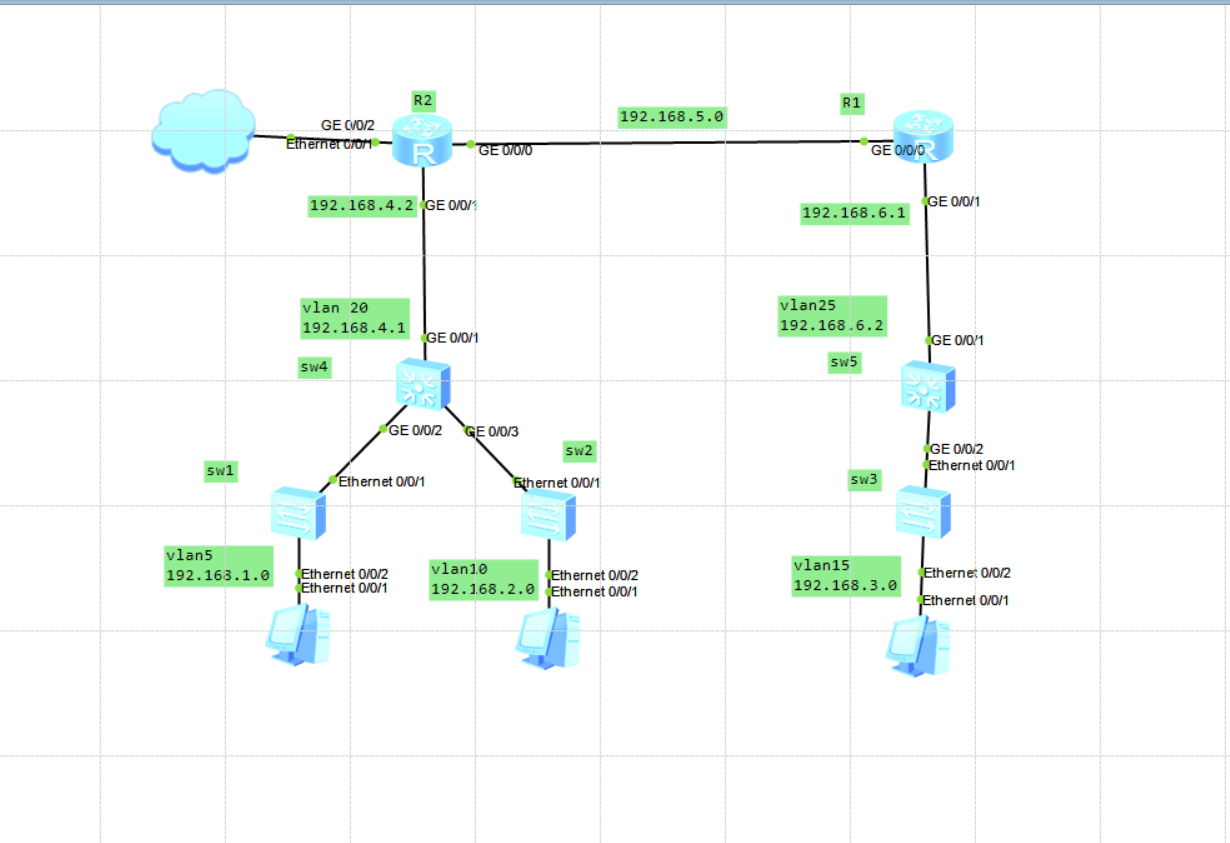
1+x云计算中级,第二天串讲,拓扑图
1+x云计算中级,串讲第二天的内容为利用ensp模拟华为设备 拓扑图如下 需要达到的效果:网络互通,各个vlan之间能正常通信,三个PC机能通过dhcp获得地址,能够通过cloud连接到外网,ping通8.8.8.8 需要用的技术有,vlan划分,OSPF,静态路由,路由的重发布,nat,基于端口的dhcp技术,cloud的使用 配置步骤 cloud的设置,连接物理机的网卡,请选择vm netwo...