pytorch --tensorboardX可视化的使用
标签: pytorch tensorboard 神经网络
直接上中点
当然了,我们想要在pytorch中使用tensorboardX你需要先安装这些依赖
我在安装的过程中也遇到了一些小问题,基本上都是一些安装依赖版本的问题。
pip install tensorflow==1.13.2
因为tensorboardX是tensorflow下的一个依赖,所以安装这个需要先安装tensorflow,在安装tensorflow会一起安装上tensorboard,一起安装tensorboard的版本应该也是1.13.几的版本吧,我也记得不是很清楚,
然后安装tensorboardX
pip install tensorboardX
然后所需要的依赖就安装完成了,接下来的就是重头戏了
tensorboardX的基本可视化是非常简单的,只需要在你训练脚本中添加几行代码就可以实现,
#-------------------------------------#
# 对数据集进行训练
#-------------------------------------#
import os
import numpy as np
import time
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torch.backends.cudnn as cudnn
from utils.config import Config
from nets.yolo_training import YOLOLoss,Generator
from nets.yolo3 import YoloBody
from matplotlib import pyplot as plt
from tensorboardX import SummaryWriter
import torchvision.models.densenet
def get_lr(optimizer):
for param_group in optimizer.param_groups:
return param_group['lr']
def plot_curve(data):
#fig = plt.figure()
plt.plot(range(len(data)), data, color='blue')
plt.legend(['value'], loc='upper right')
plt.xlabel('step')
plt.ylabel('value')
plt.show()
def fit_ont_epoch(net,yolo_losses,epoch,epoch_size,epoch_size_val,gen,genval,Epoch):
total_loss = 0
val_loss = 0
for iteration in range(epoch_size):
start_time = time.time()
images, targets = next(gen)#这里对原始的图片和框子进行了预处理
with torch.no_grad():
images = Variable(torch.from_numpy(images).cuda().type(torch.FloatTensor))
targets = [Variable(torch.from_numpy(ann).type(torch.FloatTensor)) for ann in targets]
optimizer.zero_grad()
outputs = net(images)
losses = []
for i in range(3):#这里是计算三层yolo的损失
loss_item = yolo_losses[i](outputs[i], targets)
losses.append(loss_item[0])
loss = sum(losses)
loss.backward()
optimizer.step()
# 将loss写入tensorboard,每一步都写
writer.add_scalar('Train_loss', loss, (epoch * epoch_size + iteration))
total_loss += loss
waste_time = time.time() - start_time
print('\nEpoch:'+ str(epoch+1) + '/' + str(Epoch))
print('iter:' + str(iteration) + '/' + str(epoch_size) + ' || Total Loss: %.4f || %.4fs/step' % (total_loss/(iteration+1),waste_time))
print('Start Validation')
for iteration in range(epoch_size_val):
images_val, targets_val = next(gen_val)
with torch.no_grad():
images_val = Variable(torch.from_numpy(images_val).cuda().type(torch.FloatTensor))
targets_val = [Variable(torch.from_numpy(ann).type(torch.FloatTensor)) for ann in targets_val]
optimizer.zero_grad()
outputs = net(images_val)
losses = []
for i in range(3):
loss_item = yolo_losses[i](outputs[i], targets_val)
losses.append(loss_item[0])
loss = sum(losses)
val_loss += loss
print('Finish Validation')
print('\nEpoch:'+ str(epoch+1) + '/' + str(Epoch))
print('Total Loss: %.4f || Val Loss: %.4f ' % (total_loss/(epoch_size+1),val_loss/(epoch_size_val+1)))
print('Saving state, iter:', str(epoch+1))
torch.save(model.state_dict(), 'logs/Epoch%d-Total_Loss%.4f-Val_Loss%.4f.pth'%((epoch+1),total_loss/(epoch_size+1),val_loss/(epoch_size_val+1)))
if __name__ == "__main__":
# 参数初始化
annotation_path = '2007_train.txt'
model = YoloBody(Config)#传入的是config,里边有框子和类别和输入网络的图片大小
#model输出的是构建好的所有层,包括最后18通道的卷积
# print(model)
print('Loading weights into state dict...')
model_dict = model.state_dict()
pretrained_dict = torch.load("model_data/mobilenet_v2-b0353104.pth")
pretrained_dict1 = {}
for k, v in list(pretrained_dict.items())[:-8]:
#print(k)
if np.shape(model_dict["backbone."+ k]) == np.shape(v):
pretrained_dict1["backbone."+ k] = v
#print("it ok")
# pretrained_dict = {k: v for k, v in pretrained_dict.items() if np.shape(model_dict[k]) == np.shape(v)}
model_dict.update(pretrained_dict1)
model.load_state_dict(model_dict)
print('Finished!')
# pretrained_dict = {k: v for k, v in pretrained_dict.items() if np.shape(model_dict[k]) == np.shape(v)}
# model_dict.update(pretrained_dict)
# model.load_state_dict(model_dict)
net = model
#设置gpu运行的各种参数
net = torch.nn.DataParallel(model)#加载gpu训练,括号中还有其他参数,比如指定cuda1
cudnn.benchmark = True
net = net.cuda()
# 建立loss函数一共三个,猜测因为有三个yolo层,所以要有三个损失计算
yolo_losses = []
for i in range(3):
yolo_losses.append(YOLOLoss(np.reshape(Config["yolo"]["anchors"],[-1,2]),
Config["yolo"]["classes"], (Config["img_w"], Config["img_h"])))
# 0.1用于验证,0.9用于训练
val_split = 0.1
with open(annotation_path) as f:
lines = f.readlines()
np.random.seed(10101)
np.random.shuffle(lines)
np.random.seed(None)
num_val = int(len(lines)*val_split)
num_train = len(lines) - num_val
writer = SummaryWriter(log_dir='logs', flush_secs=60)
Cuda = True
if Cuda:
graph_inputs = torch.from_numpy(np.random.rand(1, 3, Config["img_w"], Config["img_h"])).type(
torch.FloatTensor).cuda()
else:
graph_inputs = torch.from_numpy(np.random.rand(1, 3, Config["img_w"], Config["img_h"])).type(torch.FloatTensor)
writer.add_graph(model, (graph_inputs,))
if True:
lr = 1e-3
Batch_size = 8
Init_Epoch = 0
Freeze_Epoch = 14
optimizer = optim.Adam(net.parameters(),lr)
lr_scheduler = optim.lr_scheduler.StepLR(optimizer,step_size=1,gamma=0.95)
#创建一个对象,将类中的参数初始化,这个貌似属于函数的多态
gen = Generator(Batch_size, lines[:num_train],
(Config["img_h"], Config["img_w"])).generate()
gen_val = Generator(Batch_size, lines[num_train:],
(Config["img_h"], Config["img_w"])).generate()
epoch_size = num_train//Batch_size#一共的数据/每次训练的数据=一共需要训练多少次
epoch_size_val = num_val//Batch_size#测试的次数
#------------------------------------#
# 冻结一定部分训练
#------------------------------------#
# for i in model.backbone.features:
# print(i)
for param in model.backbone.features.parameters():
param.requires_grad = False
#print("11")
for epoch in range(Init_Epoch,Freeze_Epoch):
fit_ont_epoch(net,yolo_losses,epoch,epoch_size,epoch_size_val,gen,gen_val,Freeze_Epoch)
lr_scheduler.step()
这个是我自己代码的训练脚本,主要改动的地方我标注一下,你们可以从代码中找到,复制到你们的train.py中就妥了,

从代码中找到这一块代码,这一部分是初始化部分,将它放到你初始化代码区,就是没有进入for循环的代码段,首先
writer = SummaryWriter(log_dir='logs', flush_secs=60)
是初始化writer对象,参数中log_dir='logs’指的是你将tensorboardx产生的文件存放的位置,flush_secs=60是60S保存一次,
Cuda = True
if Cuda:
graph_inputs = torch.from_numpy(np.random.rand(1, 3, Config["img_w"], Config["img_h"])).type(
torch.FloatTensor).cuda()
else:
graph_inputs = torch.from_numpy(np.random.rand(1, 3, Config["img_w"], Config["img_h"])).type(torch.FloatTensor)
writer.add_graph(model, (graph_inputs,))
这段是给writer对象指定一个输入,graph_inputs 是产生一个按照pytorch要求给出的一个四维输入,然后按照add_graph方法将模型和输入进行写入文件。是不是很nice
writer.add_scalar('Train_loss', loss, (epoch * epoch_size + iteration))
然后是找到这段代码,这段代码在fit_ont_epoch函数中,你可以找一下,fit_ont_epoch这个函数是我脚本进行for循环的函数,所以可想而知,上面这行代码是放在循环迭代中的,这三个参数中Train_loss是生成图表的标题,loss就是数值,手边一堆是图表横坐标的值,这就完事了,然后你就可以开始训练你的模型了,
开始训练之后,在你的项目指定存储文件中就会产生一个

类似于这样的文件,这个文件就是在当时你指定存储位置中

就是这个代码指定的,dir不是路径的意思么,都懂。
运行了网络之后,你需要打开命令行来得到网址来查看你的训练参数,因为这个服务是在网站上进行的
打开你的命令行之后输入
>tensorboard --logdir=D:\桌面\毕业论文相
关资料\yolo3-mobilenetv3-pytorch-master\logs
当然,tensorboard --logdir=这个是固定写法,但是后边 D:\桌面\毕业论文相
关资料\yolo3-mobilenetv3-pytorch-master\logs是你存放
的路径,我存放的路径就是那个,但是你需要改成你的,然后回车之后就会出现

出现这个说明已经成功了,将我箭头指向的网站复制到浏览器中打开就是这个东东了
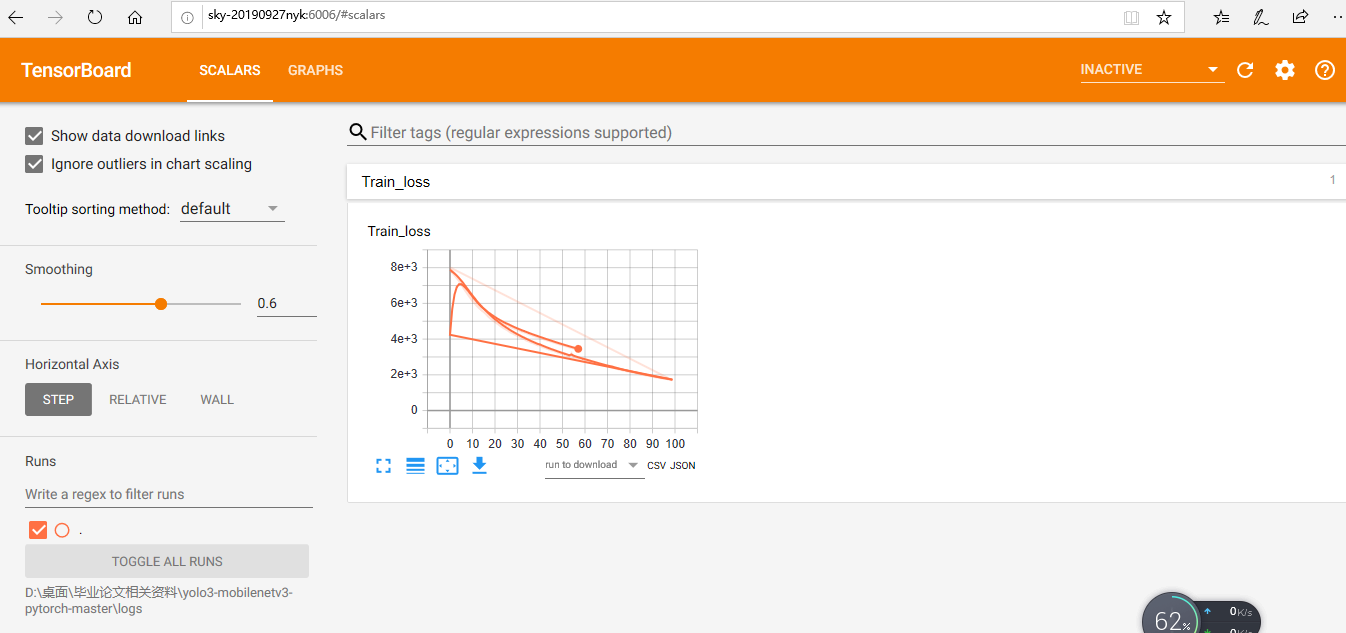
这个是实时监控的,随着时间推移,loss就会不断变化,但是也不是所有浏览器都能打开这个网页,我的qq浏览器就打不来,用电脑自带的ie打开的,如果打不开你可以多试几个。
运行报错
在我装了那些依赖之后第一次使用是会报错的,基本上错误的原因都是包的版本对不上号,这个你可以将问题复制到网站上查一下,都是可以解决的,可能tensorboard的版本太低,让你换一个高版本的,可会遇到past错误,这个错误是需要安装一个包future
pip install future
然后你装上了基本上就ok了
我写这篇文章的时间是2020.09.12
智能推荐
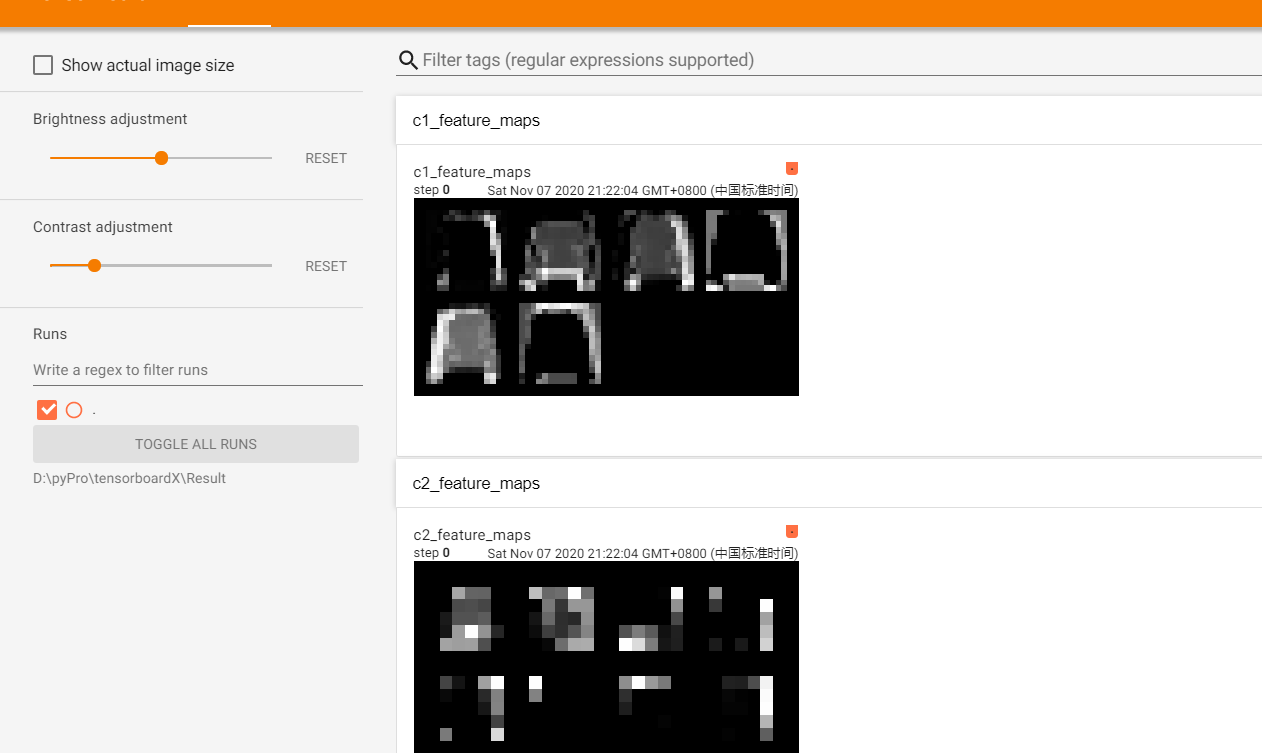
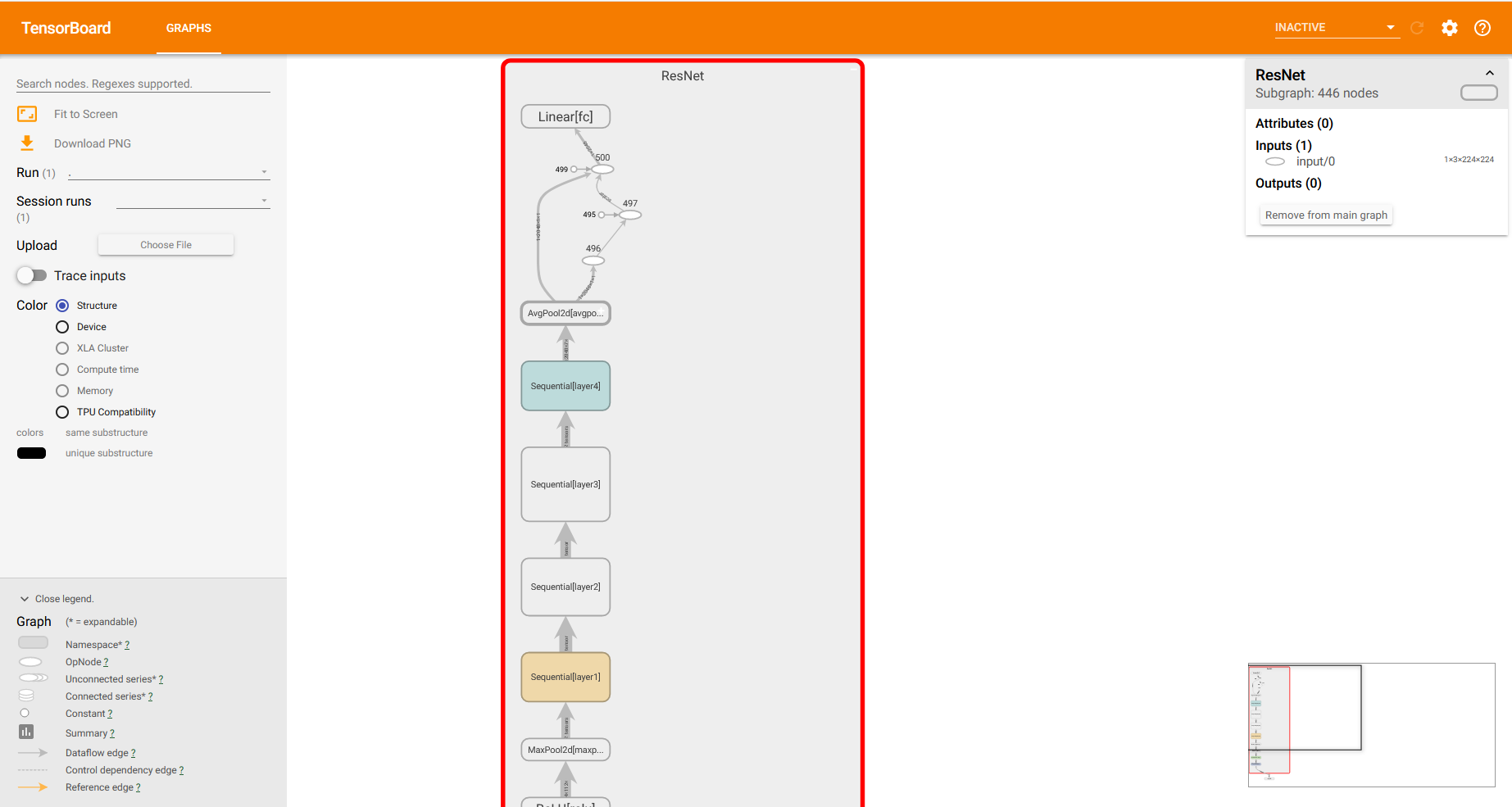
pytorch 使用tensorboardX可视化网络结构图
pytorch 使用tensorboardX可视化网络结构图 前提条件 使用方法 代码 使用 结果展示: 前提条件 安装tensorflow,tensorboardX,pytorch 使用方法 代码 使用 运行程序后: 生成类似下图中的文件夹,文件夹内有相应文件: 进到该文件夹所在目录: 执行下列命令: 这里需要注意下,有的博客里写的是–logdir=,是有问题的,之前的版本这样写没问...
Linux内核之进程调度3:进程调度
1. 吞吐率和响应 吞吐:单位时间内做的有用功; 响应:低延迟。 吞吐追求的整个系统CPU做有用功,响应追求的是某个特定任务的延迟低; 1GHZ的CPU切换线程保存恢复现场约几个微妙级别,看似消耗不了太多时间,但是由于系统的局部性原理,会保存当前线程数据的缓存,切换线程会打乱局部性引起cache miss,而CPU访问cache速度远大于内存访问,这样综合看来上下文切换花销还是很大的。无用功占用较...
restful+ci框架 实践
restful架构: 是就是目前最流行的一种互联网软件架构。它结构清晰、符合标准、易于理解、扩展方便,所以正得到越来越多网站的采用。具体理论请看我上一篇写的restful理论。本篇主要记录下关于restful的实践。 restful实践: 工具: 这次在ci框架+restful 主要文件: 在控制器中添加控制器类:Restful.php。 在头部包含REST_Controller.php文件并继承...
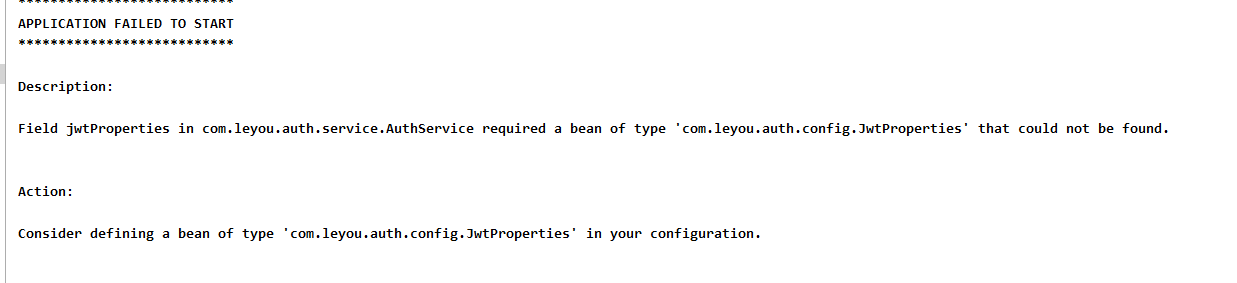
Configuration, ConfigurationProperties和EnableConfigurationProperties用法
最近刚刚解决了个错误,突然又发现这个类在spring容器中找不到, 于是我就加一个 @Component的注解,哈哈直接启动成功,那我如果吧这个注解去掉,加上一个@Configuration的注解呢,哈哈还是可以的,毕竟里面已经有这个@Component的注解了。所以我就整理下Configuration,ConfigurationProperties,EnableConfigurationProp...
猜你喜欢
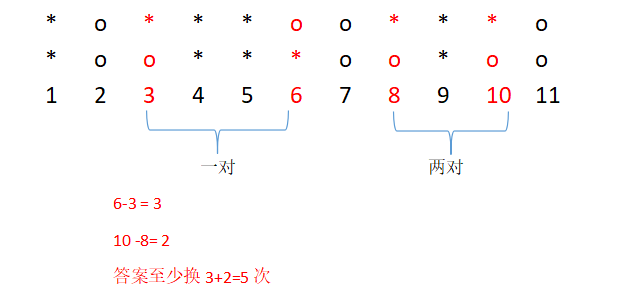
备战蓝桥杯--贪心算法刷题整理5
翻硬币(贪心算法) 看了一下网上的题解,感觉挺强,网友的做题思想值得借鉴,这里分享一下网友的链接,同时再分享一下自己的解题方案 链接:https://blog.csdn.net/qq_34594236/article/details/60326782 题目描述: 小明正在玩一个“翻硬币”的游戏。 桌上放着排成一排的若干硬币。我们用 * 表示正面,用 o 表示反面(是小写字母...
部署高可用RabbitMQ
安装 准备工作 这里我们使用三个RabbitMQ节点: 开通端口(具体见官方文档): 安装ErLang和RabbitMQ Server 安装文档见:https://www.rabbitmq.com/install-rpm.html。 采用RPM包而不是Repo的安装命令如下(以下的版本号可根据实际情况修改): 安装管理插件 安装文档见:https://www.rabbitmq.com/manage...

Opencv常用代码总结
文章目录 读取显示图像 保存图片 查看图片信息 读取视频 截取部分图像数据 颜色通道提取、融合与保留 边界填充 数值计算 图像融合 图像阈值 图像平滑(降噪) 形态学-腐蚀操作 形态学-膨胀操作 开运算与闭运算 梯度运算 礼帽与黑帽 图像梯度 Sobel算子 Scharr算子 laplacian算子 Canny边缘检测 图像金字塔 高斯金字塔:向下采样(缩小) 高斯金字塔:向上采样(放大) 拉普拉...
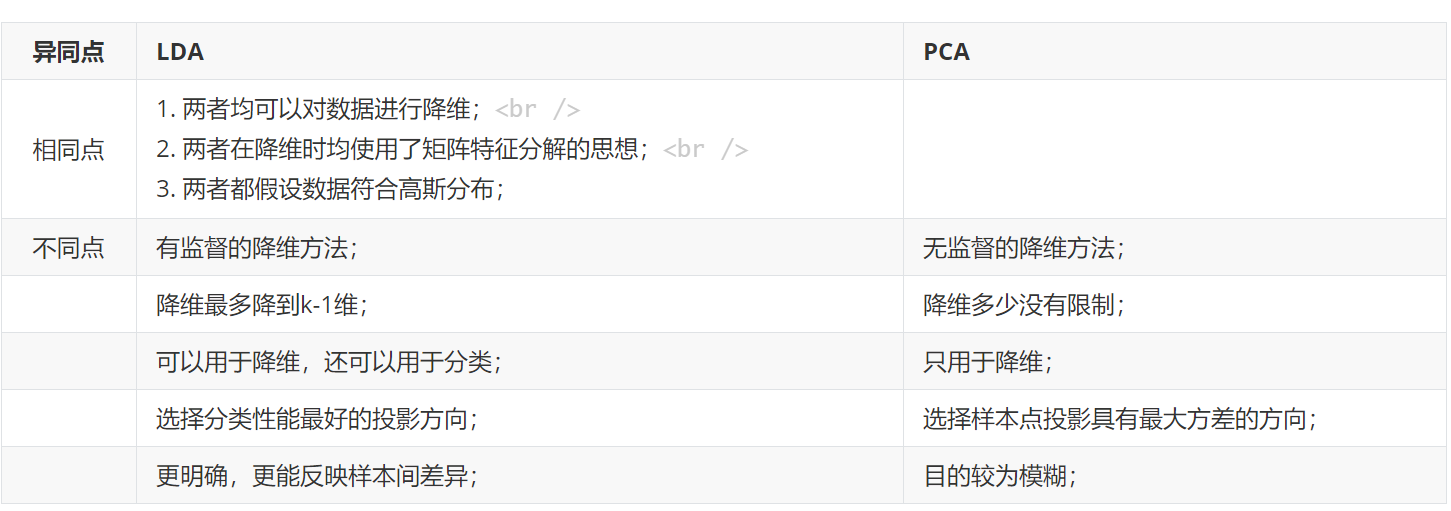
Numpy实现LDA
LDA与PCA的区别如下表: LDA的原理如下: 代码实现如下,这里使用的a,b是Nx2的二维点集合,经过LDA后,二维的点变为一维。更高维度的也是可以做到的。函数里的dim是原始数据的维度,d是想要降到的维度。 初始的数据如下图,红色点和蓝色点代表不同的分类。 经过LDA后,投影的一维数值如下图所示。 可见LDA实现了降维,而且两种分类的间距较大,类内的散度较小。...
Java反射机制
相关类型: java.lang.Class java.lang.reflect.Constructor java.lang.reflect.Field java.lang.reflect.Method java.lang.reflect.Modifier 作用: 1、反编译 .class –> .java&n...