pytorch使用tensorboardX可视化训练情况的方式
tensorboardX是为解决pytorch框架可视化训练问题的,不过据说目前pytorch已经支持使用tensorboard进行可视化了。
TensorboardX可以提供中很多的可视化方式,本文主要介绍scalar 和 graph,这在深度网络调试时主要使用的,一个用于显示训练情况,一个用于显示网络结构。
使用TensorboardX
首先,需要创建一个 SummaryWriter 的示例:
from tensorboardX import SummaryWriter
# Creates writer1 object.
# The log will be saved in 'runs/exp'
writer1 = SummaryWriter('runs/exp')
# Creates writer2 object with auto generated file name
# The log directory will be something like 'runs/Aug20-17-20-33'
writer2 = SummaryWriter()
# Creates writer3 object with auto generated file name, the comment will be appended to the filename.
# The log directory will be something like 'runs/Aug20-17-20-33-resnet'
writer3 = SummaryWriter(comment='resnet')以上展示了三种初始化 SummaryWriter 的方法:
1)提供一个路径,将使用该路径来保存日志
2)无参数,默认将使用 runs/日期时间 路径来保存日志
3)提供一个 comment 参数,将使用 runs/日期时间-comment 路径来保存日志
一般来讲,我们对于每次实验新建一个路径不同的 SummaryWriter,也叫一个 run,如 runs/exp1、runs/exp2。
接下来,我们就可以调用 SummaryWriter 实例的各种 add_something 方法向日志中写入不同类型的数据了。想要在浏览器中查看可视化这些数据,只要在命令行中开启 tensorboard 即可:
tensorboard --logdir=<your_log_dir>
其中的 <your_log_dir> 既可以是单个 run 的路径,如上面 writer1 生成的 runs/exp;也可以是多个 run 的父目录,如 runs/ 下面可能会有很多的子文件夹,每个文件夹都代表了一次实验,我们令 --logdir=runs/ 就可以在 tensorboard 可视化界面中方便地横向比较 runs/ 下不同次实验所得数据的差异。
添加数据
1)标量(scalar)
使用 add_scalar 方法来记录数字常量。
add_scalar(tag, scalar_value, global_step=None, walltime=None)
参数
- tag (string)::数据名称,不同名称的数据使用不同曲线展示
- scalar_value (float): 数字常量值
- global_step (int, optional): 训练的 step
- walltime (float, optional): 记录发生的时间,默认为 time.time()
需要注意,这里的 scalar_value 一定是 float 类型,如果是 PyTorch scalar tensor,则需要调用 .item() 方法获取其数值。我们一般会使用 add_scalar 方法来记录训练过程的 loss、accuracy、learning rate 等数值的变化,直观地监控训练过程。
Example
from tensorboardX import SummaryWriter
writer = SummaryWriter('runs/scalar_example')
for i in range(10):
writer.add_scalar('quadratic', i**2, global_step=i)
writer.add_scalar('exponential', 2**i, global_step=i)这里,我们在一个路径为 runs/scalar_example 的 run 中分别写入了二次函数数据 quadratic 和指数函数数据 exponential,在浏览器可视化界面中效果如下:
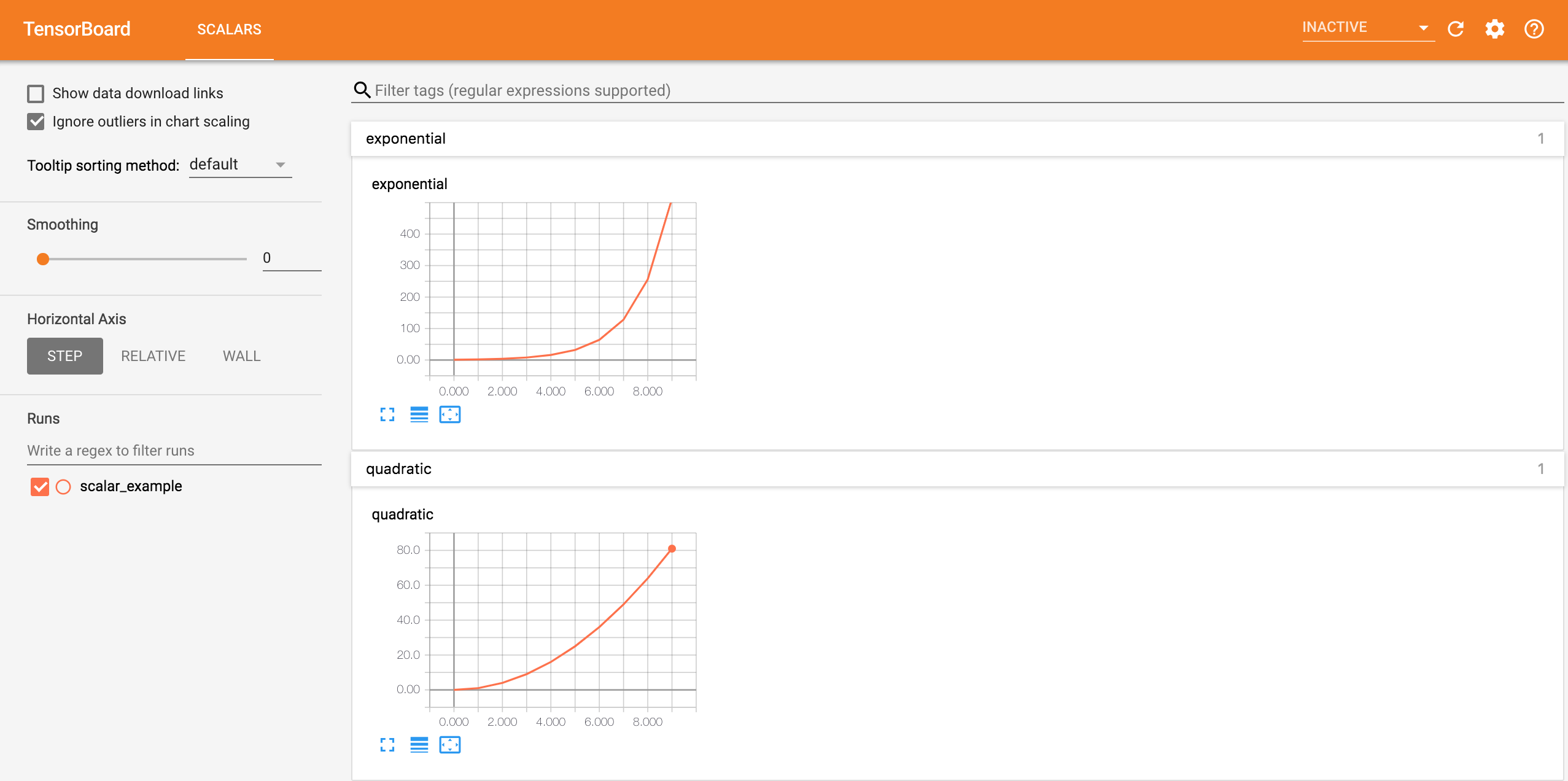
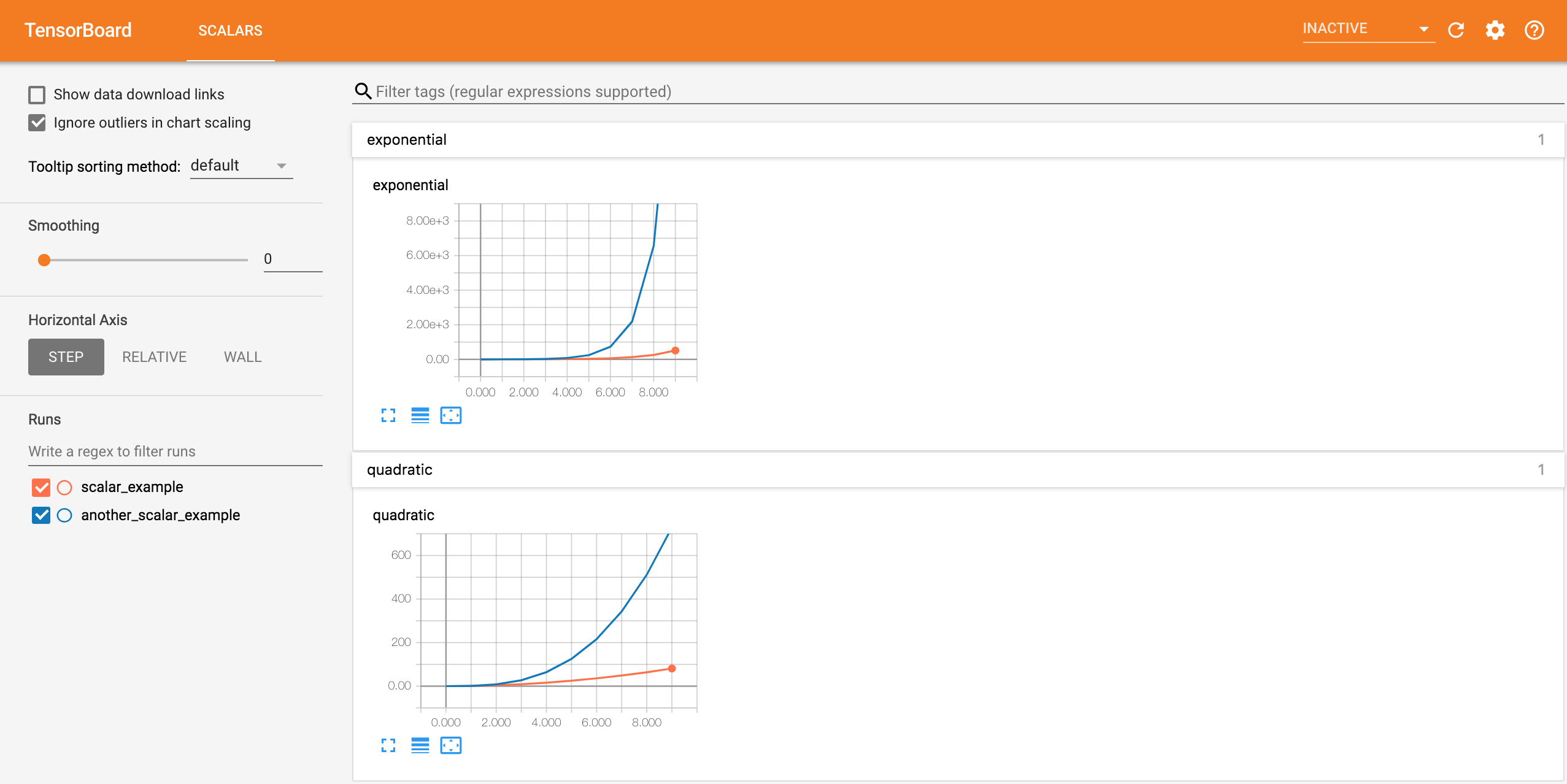
writer = SummaryWriter('runs/another_scalar_example')
for i in range(10):
writer.add_scalar('quadratic', i**3, global_step=i)
writer.add_scalar('exponential', 3**i, global_step=i)接下来我们在另一个路径为 runs/another_scalar_example 的 run 中写入名称相同但参数不同的二次函数和指数函数数据,可视化效果如下。我们发现相同名称的量值被放在了同一张图表中展示,方便进行对比观察。同时,我们还可以在屏幕左侧的 runs 栏选择要查看哪些 run 的数据。如下图所示:
2)运行图 (graph)
使用 add_graph 方法来可视化一个神经网络:
add_graph(model, input_to_model=None, verbose=False, **kwargs)参数
- model (torch.nn.Module): 待可视化的网络模型
- input_to_model (torch.Tensor or list of torch.Tensor, optional): 待输入神经网络的变量或一组变量(即神经网络的输入)
该方法可以可视化神经网络模型,TensorboardX 给出了一个官方样例大家可以尝试。样例运行效果如下:
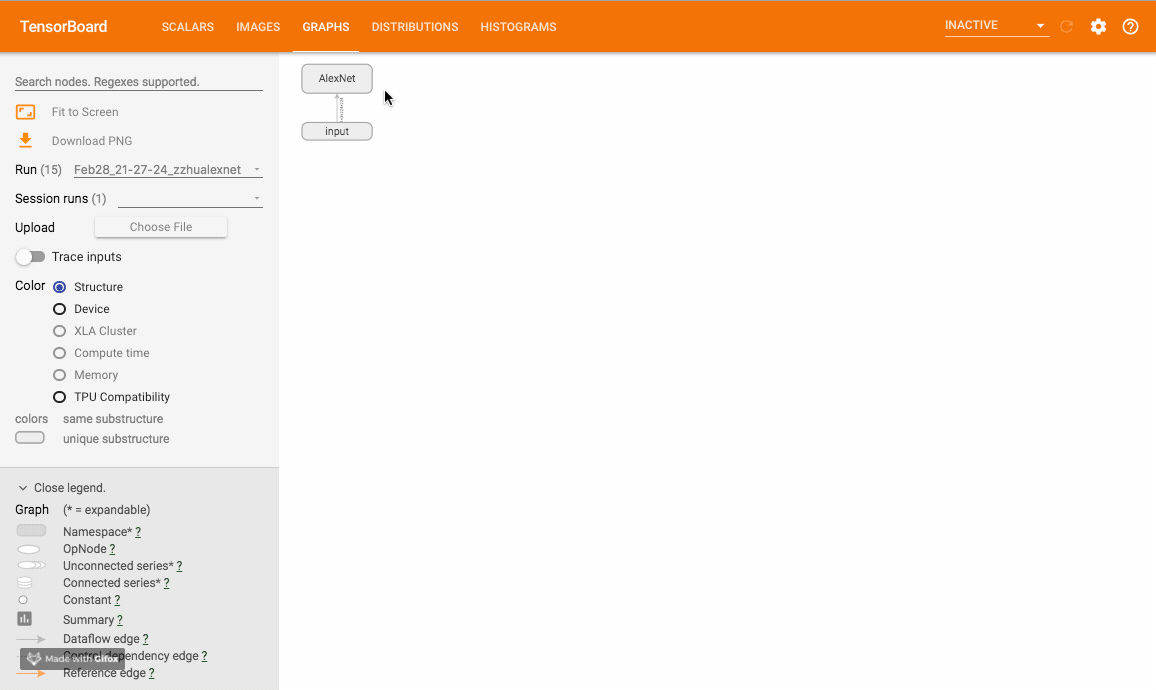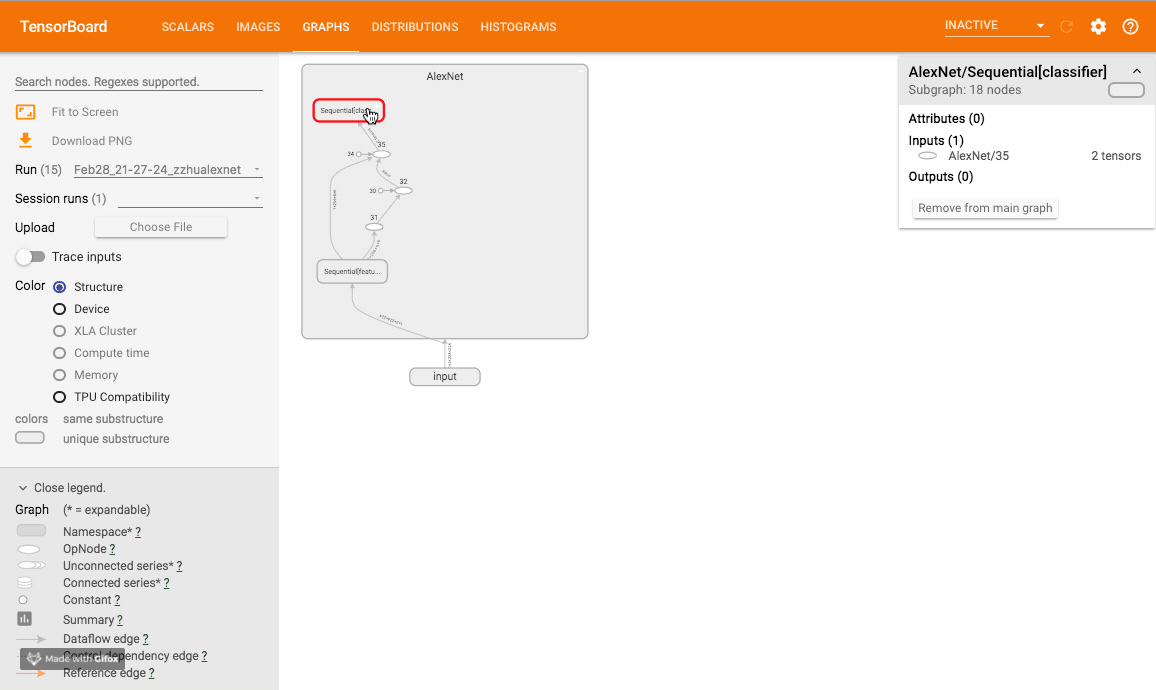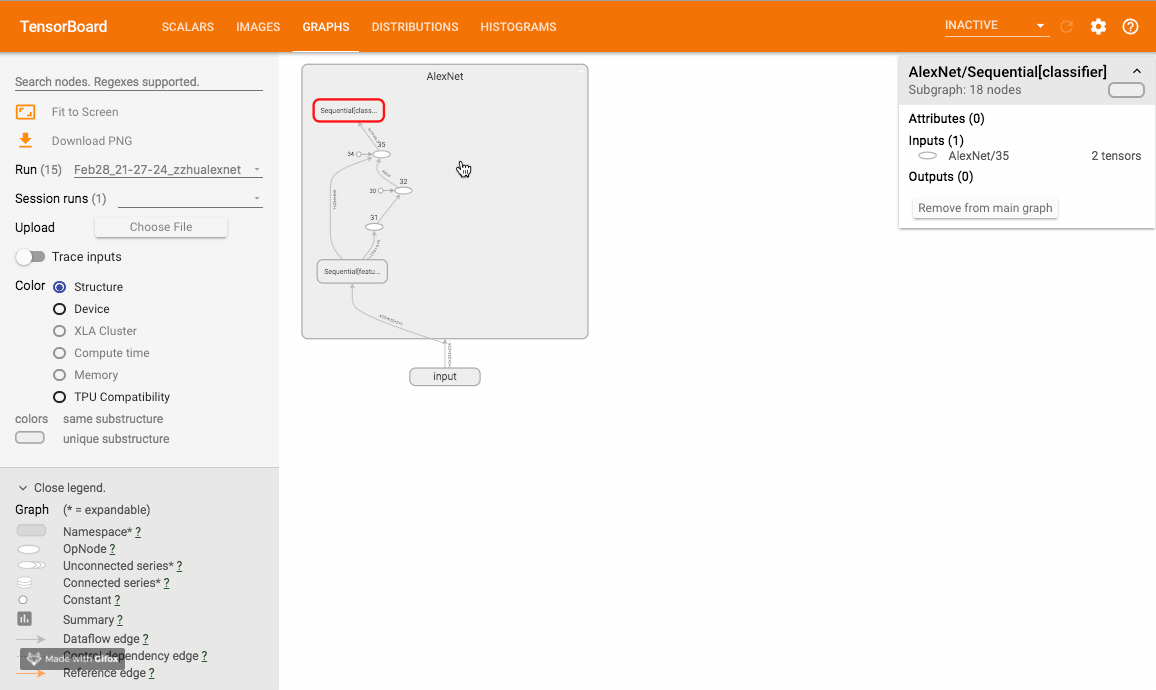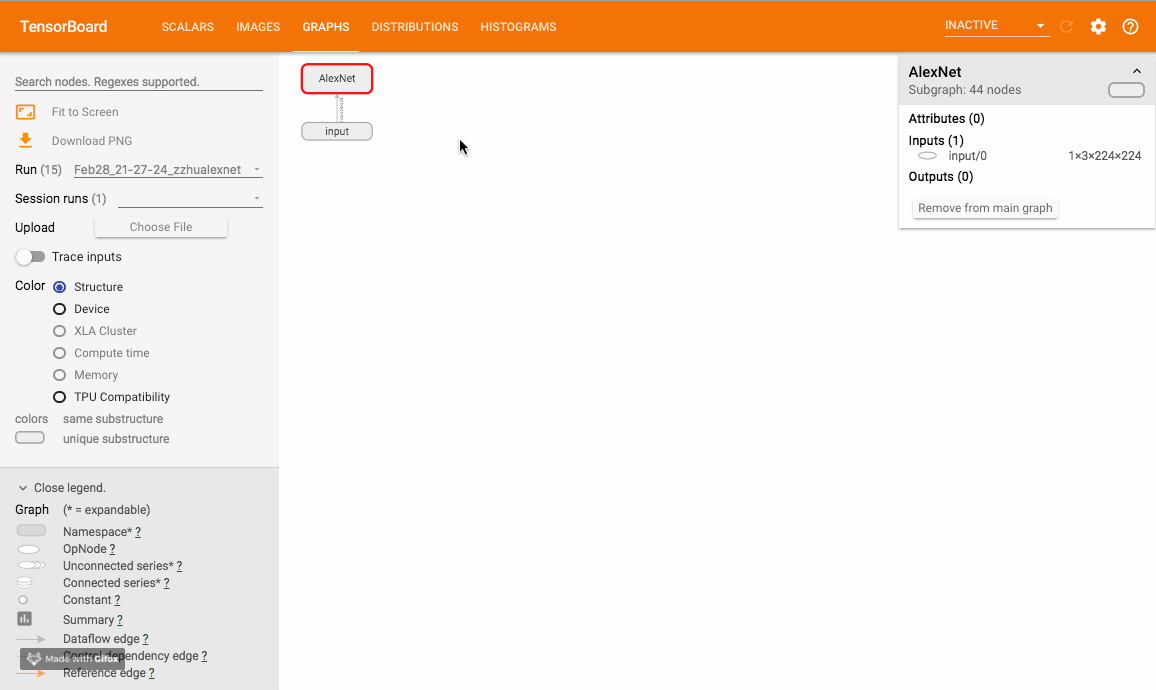
一些tips
- tensorboard 有缓存,如果进行了一些 runs 文件夹的删除操作,最好重启 tensorboard,以避免无效数据干扰展示效果。
- 如果执行 add 操作后没有实时在网页可视化界面看到效果,试试重启 tensorboard。
参看博客:https://blog.csdn.net/bigbennyguo/article/details/87956434
一些操作实例
方便理解tensorboardX的具体使用过程
1)Graph:
运行结果
点击Net1部分可以将其网络展开,查看网络内部构造,如下图所示。其他部分可以继续展开查看详情。
2)实现线性回归的训练过程中的loss可视化和模型的保存
打开tensorboard可视化结果如下:
模型可视化:
损失可视化:
3)综合Demo
本Demo代码为TensorboardX提供的官方Demo代码。
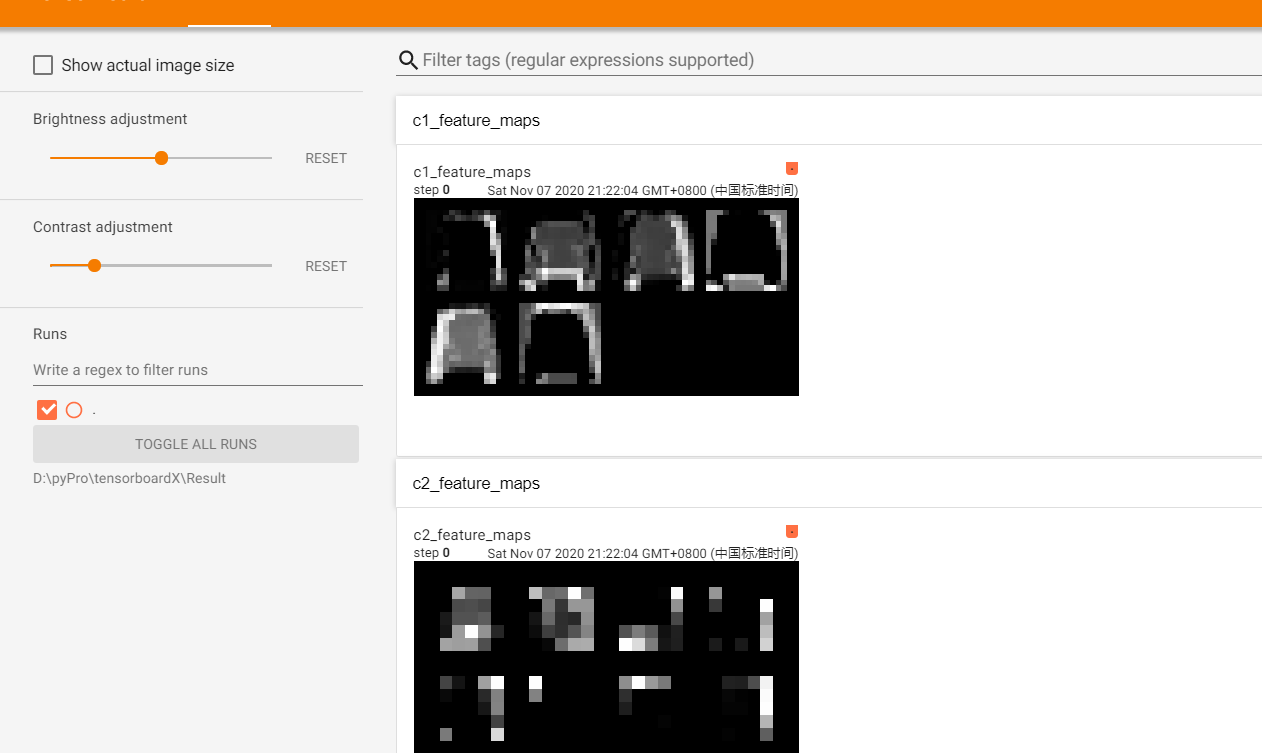
可视化结果如下:
智能推荐
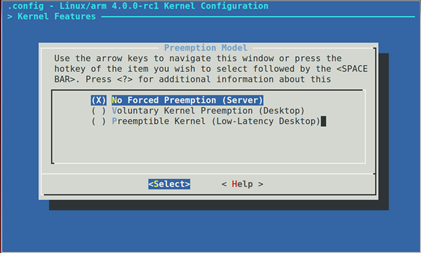
Linux内核之进程调度3:进程调度
1. 吞吐率和响应 吞吐:单位时间内做的有用功; 响应:低延迟。 吞吐追求的整个系统CPU做有用功,响应追求的是某个特定任务的延迟低; 1GHZ的CPU切换线程保存恢复现场约几个微妙级别,看似消耗不了太多时间,但是由于系统的局部性原理,会保存当前线程数据的缓存,切换线程会打乱局部性引起cache miss,而CPU访问cache速度远大于内存访问,这样综合看来上下文切换花销还是很大的。无用功占用较...
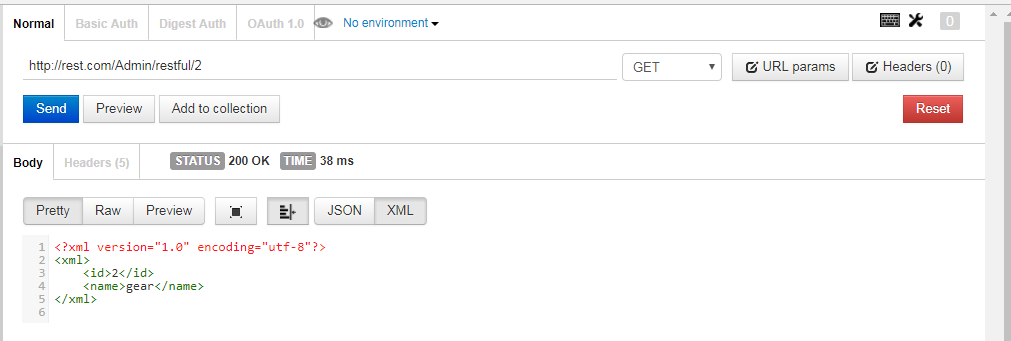
restful+ci框架 实践
restful架构: 是就是目前最流行的一种互联网软件架构。它结构清晰、符合标准、易于理解、扩展方便,所以正得到越来越多网站的采用。具体理论请看我上一篇写的restful理论。本篇主要记录下关于restful的实践。 restful实践: 工具: 这次在ci框架+restful 主要文件: 在控制器中添加控制器类:Restful.php。 在头部包含REST_Controller.php文件并继承...
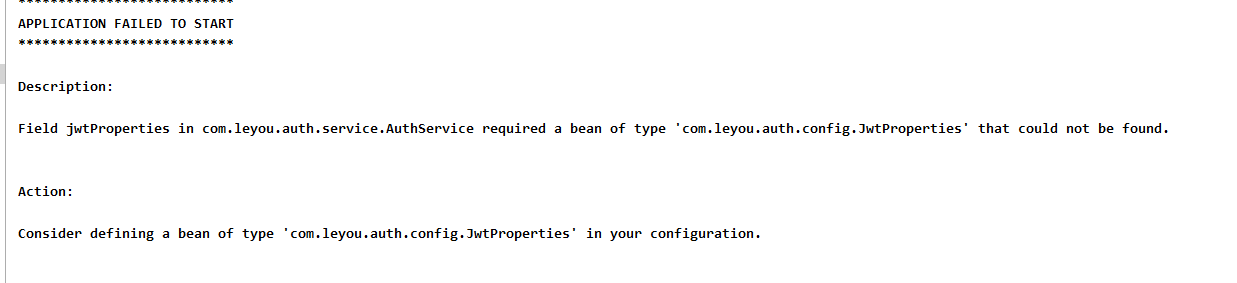
Configuration, ConfigurationProperties和EnableConfigurationProperties用法
最近刚刚解决了个错误,突然又发现这个类在spring容器中找不到, 于是我就加一个 @Component的注解,哈哈直接启动成功,那我如果吧这个注解去掉,加上一个@Configuration的注解呢,哈哈还是可以的,毕竟里面已经有这个@Component的注解了。所以我就整理下Configuration,ConfigurationProperties,EnableConfigurationProp...
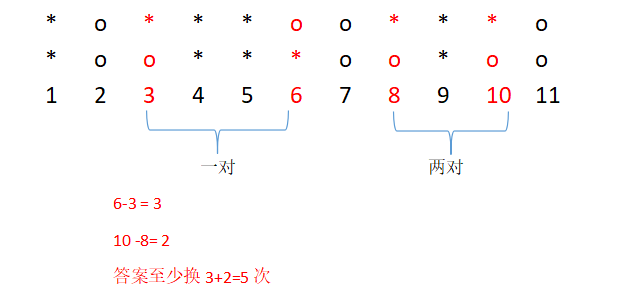
备战蓝桥杯--贪心算法刷题整理5
翻硬币(贪心算法) 看了一下网上的题解,感觉挺强,网友的做题思想值得借鉴,这里分享一下网友的链接,同时再分享一下自己的解题方案 链接:https://blog.csdn.net/qq_34594236/article/details/60326782 题目描述: 小明正在玩一个“翻硬币”的游戏。 桌上放着排成一排的若干硬币。我们用 * 表示正面,用 o 表示反面(是小写字母...
猜你喜欢
部署高可用RabbitMQ
安装 准备工作 这里我们使用三个RabbitMQ节点: 开通端口(具体见官方文档): 安装ErLang和RabbitMQ Server 安装文档见:https://www.rabbitmq.com/install-rpm.html。 采用RPM包而不是Repo的安装命令如下(以下的版本号可根据实际情况修改): 安装管理插件 安装文档见:https://www.rabbitmq.com/manage...

Opencv常用代码总结
文章目录 读取显示图像 保存图片 查看图片信息 读取视频 截取部分图像数据 颜色通道提取、融合与保留 边界填充 数值计算 图像融合 图像阈值 图像平滑(降噪) 形态学-腐蚀操作 形态学-膨胀操作 开运算与闭运算 梯度运算 礼帽与黑帽 图像梯度 Sobel算子 Scharr算子 laplacian算子 Canny边缘检测 图像金字塔 高斯金字塔:向下采样(缩小) 高斯金字塔:向上采样(放大) 拉普拉...
Numpy实现LDA
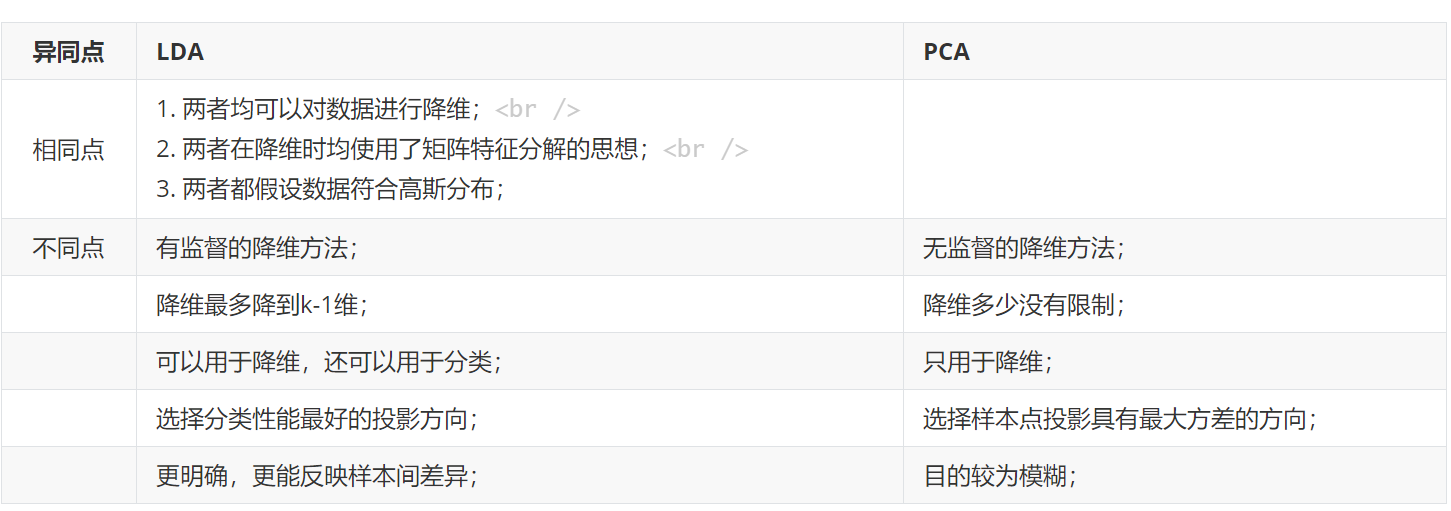
LDA与PCA的区别如下表: LDA的原理如下: 代码实现如下,这里使用的a,b是Nx2的二维点集合,经过LDA后,二维的点变为一维。更高维度的也是可以做到的。函数里的dim是原始数据的维度,d是想要降到的维度。 初始的数据如下图,红色点和蓝色点代表不同的分类。 经过LDA后,投影的一维数值如下图所示。 可见LDA实现了降维,而且两种分类的间距较大,类内的散度较小。...
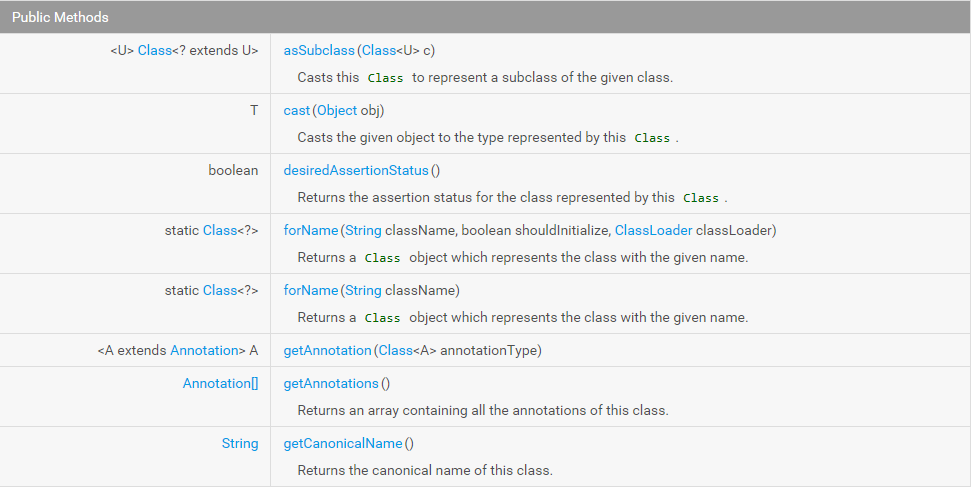
Java反射机制
相关类型: java.lang.Class java.lang.reflect.Constructor java.lang.reflect.Field java.lang.reflect.Method java.lang.reflect.Modifier 作用: 1、反编译 .class –> .java&n...