Python通过m3u8文件下载合并ts视频
前段时间,接到一个需求,要求下载某一个网站的视频,然后自己从网上查阅了相关的资料,在这里做一个总结。
1. m3u8文件
m3u8是苹果公司推出一种视频播放标准,是一种文件检索格式,将视频切割成一小段一小段的ts格式的视频文件,然后存在服务器中(现在为了减少I/o访问次数,一般存在服务器的内存中),通过m3u8解析出来路径,然后去请求,是现在比较流行的一种加载方式。目前,很多新闻视频网站都是采用这种模式去加载视频。
M3U8文件是指UTF-8编码格式的M3U文件。M3U文件是记录了一个索引纯文本文件,打开它时播放软件并不是播放它,而是根据它的索引找到对应的音视频文件的网络地址进行在线播放。原视频数据分割为很多个TS流,每个TS流的地址记录在m3u8文件列表中。
下面就是m3u8文件的格式。
#EXTM3U
#EXT-X-VERSION:3
#EXT-X-MEDIA-SEQUENCE:0
#EXT-X-ALLOW-CACHE:YES
#EXT-X-TARGETDURATION:15
#EXTINF:6.916667,
out000.ts
#EXTINF:10.416667,
out001.ts
#EXTINF:10.416667,
out002.ts
#EXTINF:1.375000,
out003.ts
#EXTINF:1.541667,
out004.ts
#EXTINF:7.666667,
out005.ts
#EXTINF:10.416667,
2. ts文件处理
- 只有m3u8文件,需要下载ts文件
- ts文件能正常播放,但太多而小,需要合并 有ts文件
- 但因为被加密无法播放,需要解码
在这里我只记录下前两个步骤,因为,我目前研究的比较少,还没有遇到ts被加密的情况。
3. 分析举例
那么下面,我就正式举一个网站,第一财经网(直接点击)跟大家正式的讲解下。
这是该网站的视频。如下图:
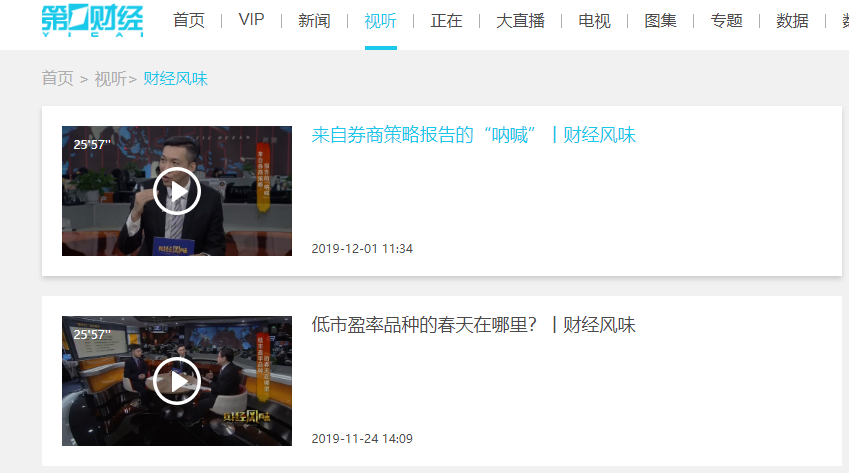
点击第一个视频,这就是我们这次要爬取的视频。
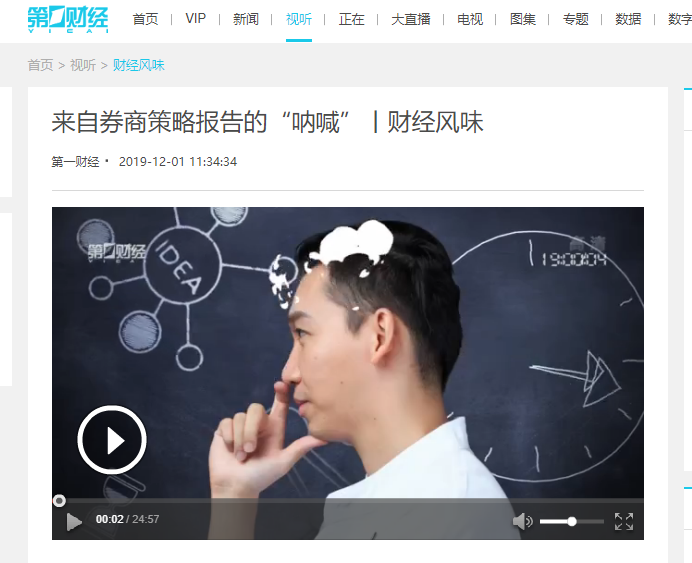
然后鼠标右键点击,选择"检查" 或者按F12键,进入开发者模式,查看网页代码。
然后,点击Network ,再点击other,寻找请求地址中带有m3u8和ts标记的请求地址。
不懂,请看下图。有一点,很重要。网站通过切割后ts加载视频,并不是没有规律的,而是通过m3u8文件附带的。也就说,网站一定是先加载m3u8文件,然后根据m3u8文件,去请求ts文件。所以,如果你找不到m3u8文件的话,你可以先找第一个ts文件,然后往上面翻,一定能找到m3u8文件。
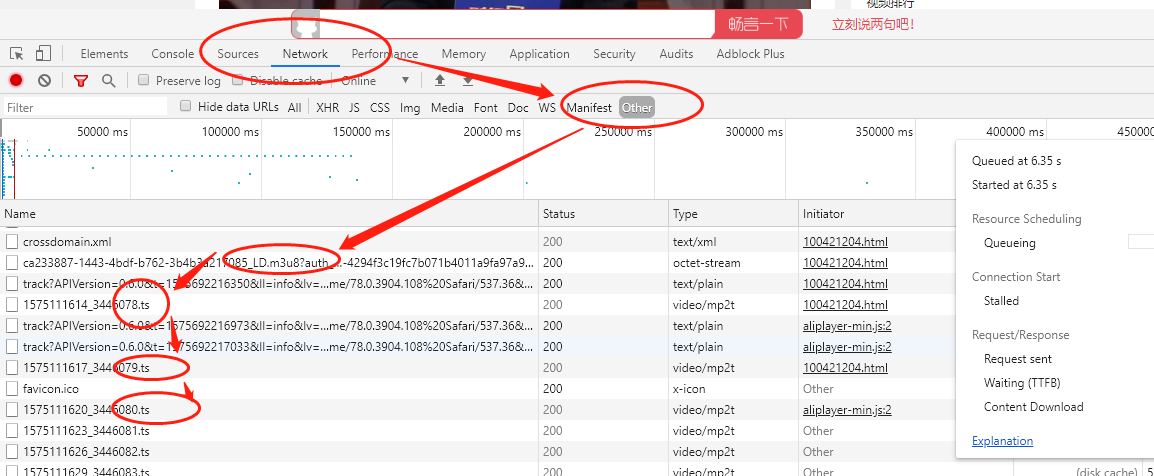
再点击这个m3u8文件,右侧对应的就是它的请求地址。
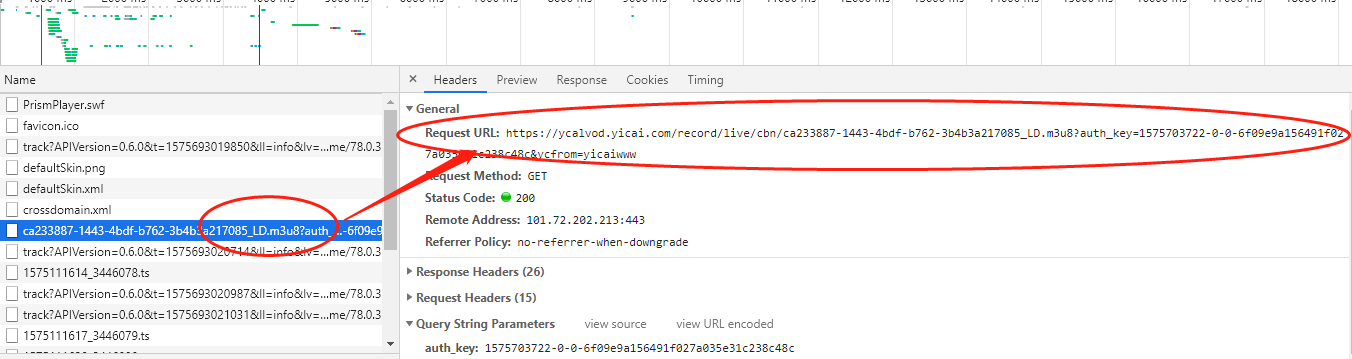
请求地址如下:
https://ycalvod.yicai.com/record/live/cbn/ca233887-1443-4bdf-b762-3b4b3a217085_LD.m3u8?auth_key=1575703722-0-0-6f09e9a156491f027a035e31c238c48c&ycfrom=yicaiwww
你可以把上面那个地址,输入浏览器地址框内,下载下来。也可以通过查看源码,找到该功能的对应的html代码。
这是下载下来的m3u8文件。

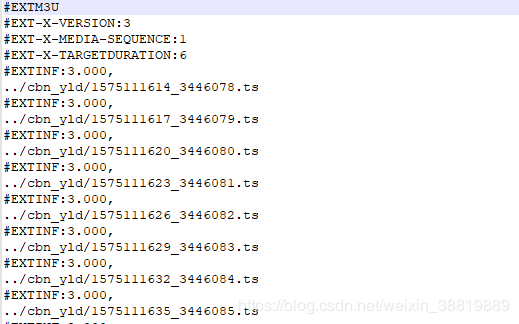
从图片可以看出来,每一个ts文件都是相对的地址,所以下面我们就需要找到绝对地址。
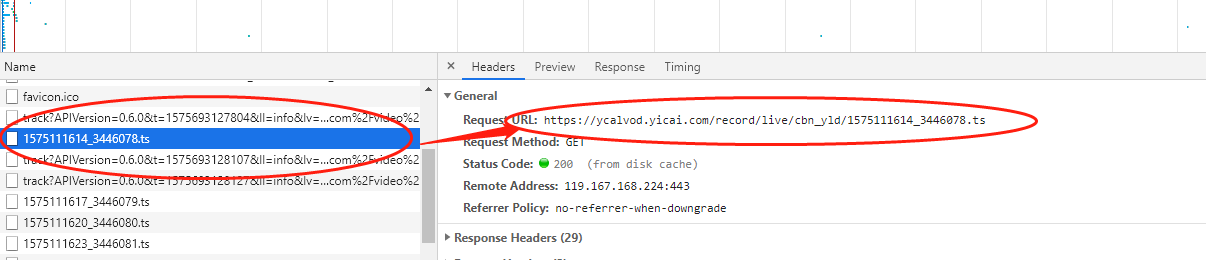
ts文件地址如下:
https://ycalvod.yicai.com/record/live/cbn_yld/1575111614_3446078.ts
上面,我们已经把这个网站的视频加载模式分析的很透彻,下面就开始撸代码了。
4. 获取ts文件
def getTsUrl():
ts_url_list = []
baseUrl = "https://ycalvod.yicai.com/record/live"
with open("ca233887-1443-4bdf-b762-3b4b3a217085_LD.m3u8", "r", encoding="utf-8") as f:
m3u8Contents = f.readlines()
for content in m3u8Contents:
if content.endswith("ts\n"):
ts_Url = baseUrl + content.replace("\n", "").replace("..", "")
ts_url_list.append(ts_Url)
print(ts_Url)
return ts_url_list
5. 下载ts文件
def download_ts_video(download_path, ts_url_list):
download_path = r"C:\Users\Administrator\Desktop\AiShu\下载视频\TS视频"
for i in range(len(ts_url_list)):
ts_url = ts_url_list[i]
try:
response = requests.get(ts_url, stream=True, verify=False)
except Exception as e:
print("异常请求:%s" % e.args)
return
ts_path = download_path + "\{}.ts".format(i)
with open(ts_path, "wb+") as file:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
file.write(chunk)
print("TS文件下载完毕!!")
这就是我本地下载好的ts切割视频
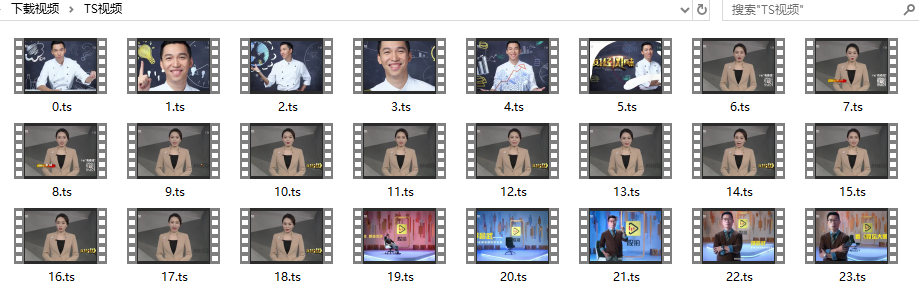
6. 合并TS视频
def heBingTsVideo(download_path,hebing_path):
all_ts = os.listdir(download_path)
with open(hebing_path, 'wb+') as f:
for i in range(len(all_ts)):
ts_video_path = os.path.join(download_path, all_ts[i])
f.write(open(ts_video_path, 'rb').read())
print("合并完成!!")
最后的结果如下:

7. 完整的代码
有兴趣的小伙伴,可以研究下。
import requests,os
def getTsUrl():
ts_url_list = []
baseUrl = "https://ycalvod.yicai.com/record/live"
with open("ca233887-1443-4bdf-b762-3b4b3a217085_LD.m3u8", "r", encoding="utf-8") as f:
m3u8Contents = f.readlines()
for content in m3u8Contents:
if content.endswith("ts\n"):
ts_Url = baseUrl + content.replace("\n", "").replace("..", "")
ts_url_list.append(ts_Url)
print(ts_Url)
return ts_url_list
def download_ts_video(download_path, ts_url_list):
download_path = r"C:\Users\Administrator\Desktop\AiShu\下载视频\TS视频"
for i in range(len(ts_url_list)):
ts_url = ts_url_list[i]
try:
response = requests.get(ts_url, stream=True, verify=False)
except Exception as e:
print("异常请求:%s" % e.args)
return
ts_path = download_path + "\{}.ts".format(i)
with open(ts_path, "wb+") as file:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
file.write(chunk)
print("TS文件下载完毕!!")
def heBingTsVideo(download_path,hebing_path):
all_ts = os.listdir(download_path)
with open(hebing_path, 'wb+') as f:
for i in range(len(all_ts)):
ts_video_path = os.path.join(download_path, all_ts[i])
f.write(open(ts_video_path, 'rb').read())
print("合并完成!!")
if __name__ == '__main__':
download_path = r"C:\Users\Administrator\Desktop\AiShu\下载视频\TS视频"
hebing_path = r"C:\Users\Administrator\Desktop\AiShu\下载视频\合并TS视频\第一财经.mp4"
ts_url_list = getTsUrl()
download_ts_video(download_path, ts_url_list)
heBingTsVideo(download_path,hebing_path)
智能推荐


html5拖放--15行js代码实现两个div内容互换
本文首发于我的个人博客:http://cherryblog.site/ ,欢迎大家前去参观 本文项目地址,sortable插件地址:https://github.com/sunshine940326/sortable demo地址:https://github.com/sunshine940326/drag 在写我们后台的管理程序中需要有一个拖放的功能,然后我们有一个这样的功能,实现11个固定且大...

git切换分支报错,不管什么标题名字,都报非法字符,所以就不起名字了。
切换分支的时候,报了标题这么个错误,error: ”xxx did not match any file(s) known to git. 看见不能切换分支,我首先 git status 查看了一下当前状态,如下图 然后,就会发现,其实我的这个错误非常明显,就是在我的 beat 分支下有文件修改,所以切换不了。ok,解决方法: 1. 如果修改的这些文件没什么用,完全可以删除。(我这儿的...
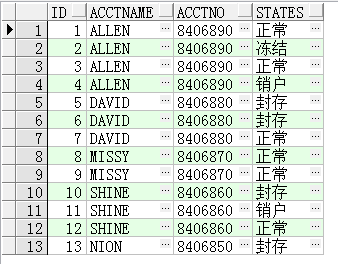
Oracle分析函数之LEAD和LAG实际应用
Oracle分析函数之LEAD和LAG实际应用 在前几天的工作中按照客户的需求,需要对客户信息进行数据分析,即某人存在多个状态的账号,将客户信息账号状态分析出结果,和客户确认汇报,根据保留规则,保留唯一账号,以保证程序可用性。起初,根据聚合函数进行查询分析,需要写一大串的SQL,即不美观又复杂,很容易产生错误。后续想到Oracle分析函数中的lead和lag,SQL简洁了很多且容易产生报告数据。 ...
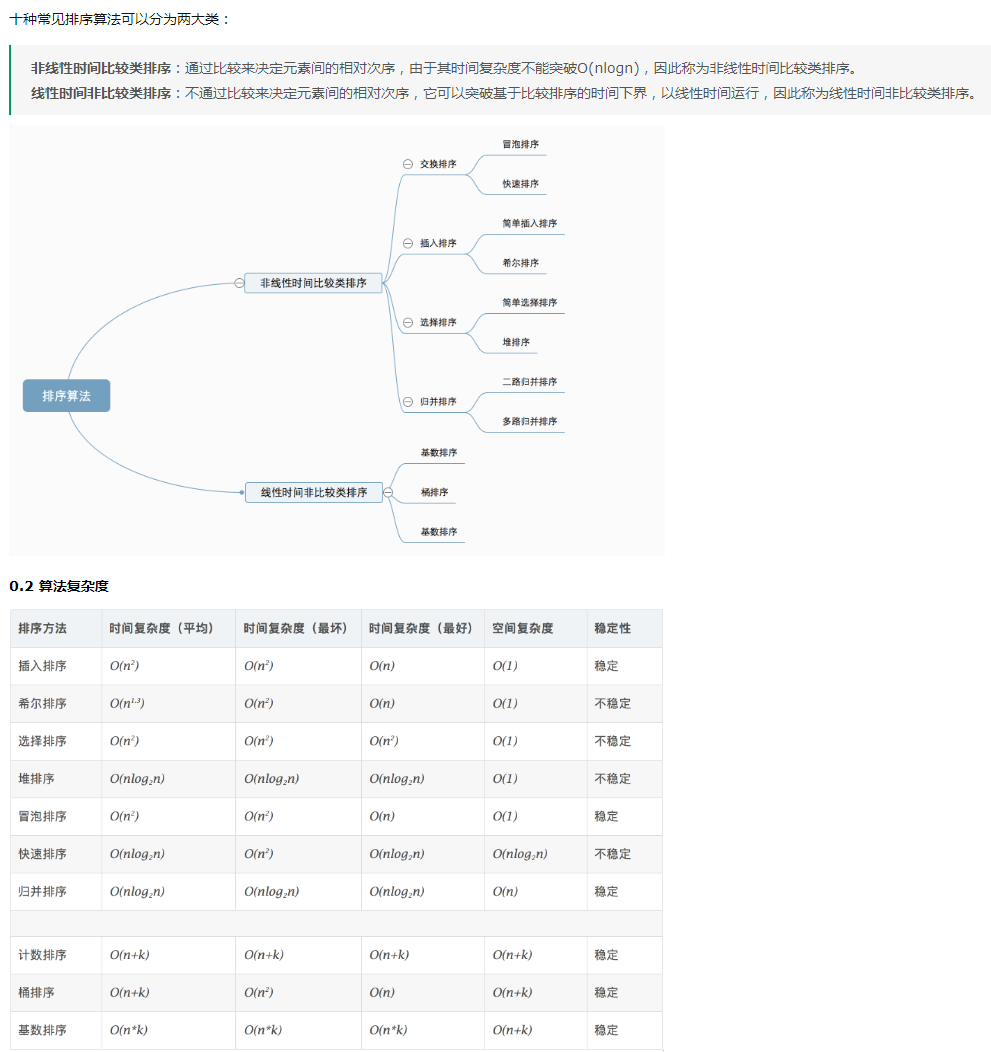
小知识积累(不断更新中)
判断变量的类型(数组,对象) tyopof:不推荐,因为无法区别数组与对象,数组是对象的子对象 instanceof:可以使用 还可以用来判断是否属于函数 Object.prototype.toString.call():最兼容,推荐使用 定时器的执行顺序或机制 js是单线程的,浏览器遇到setTimeout或者setInterval会把定时器推入浏览器的待执行事件队列里面但是不执行,先执行完当前...
猜你喜欢
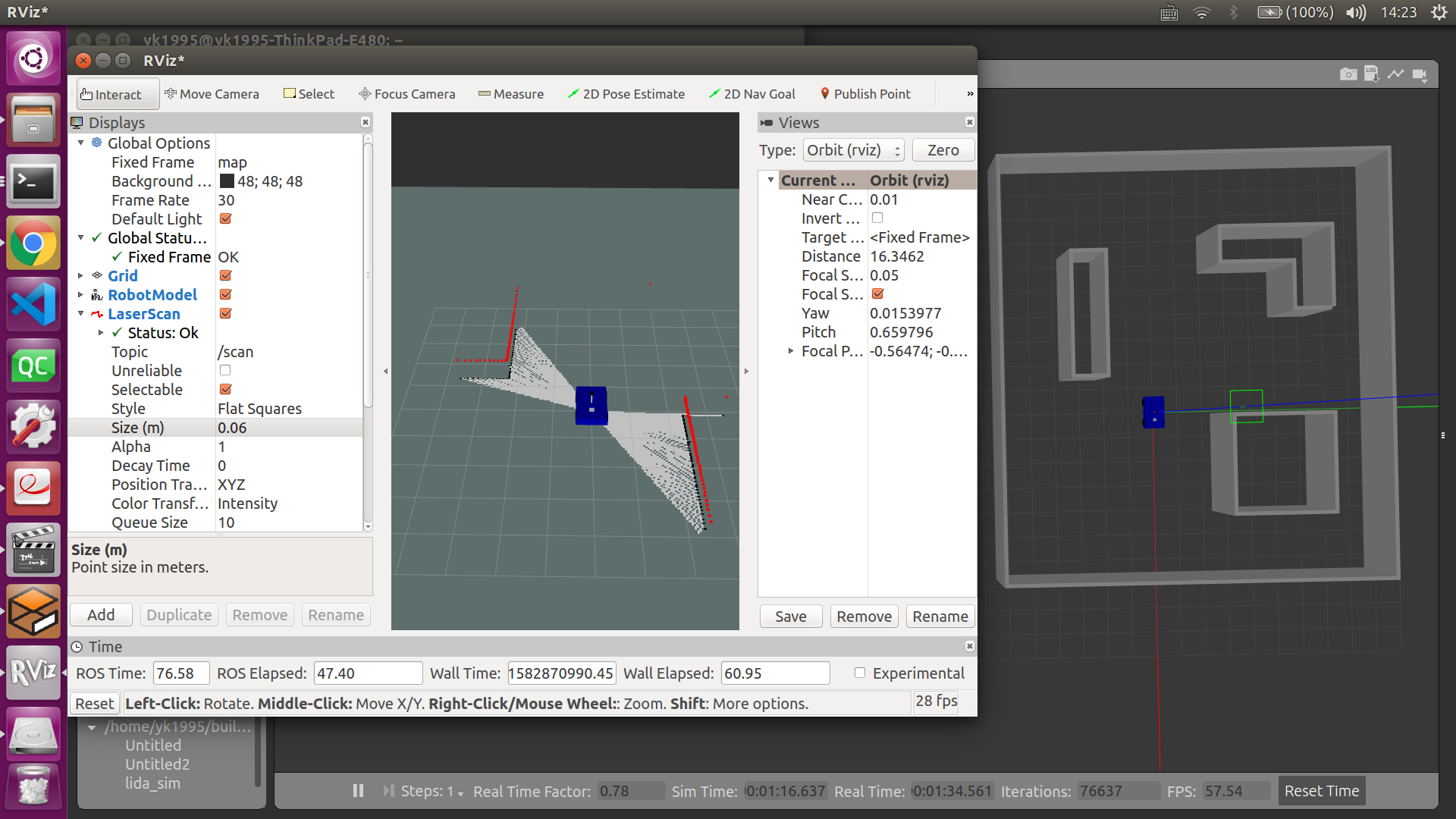
ROS自学实践(6):ROS进行激光SLAM建图——gmapping
本节主要记录运行ROS自带的SLAM建模包gmapping方法,为后续理解这些代码,建立自己的SLAM算法打下基础。 基于粒子滤波算法 二维栅格地图 需要里程计信息 1.通过命令行安装gmapping包 2.配置gmapping节点 3.运行gazebo模型及gmapping节点 4.打开rviz 添加laserscan、map、robotmodel模型 5.移动小车,建立模型 6.保存当前地图 ...

face-api.js中加入MTCNN:进一步支持使用JS实时进行人脸跟踪和识别
如果你现在正在阅读这篇文章,那么你可能已经阅读了我的介绍文章(JS使用者福音:在浏览器中运行人脸识别)或者之前使用过face-api.js。如果你还没有听说过face-api.js,我建议你先阅读介绍文章再回来阅读本文。 和往常一样,本文中为你准备了一个代码示例。我们将解析一个小的应用程序,这个程序将在浏览器中访问摄像头图像执行实时人脸检测和人脸识别,让我们开始吧! 使用face-api.js进行...
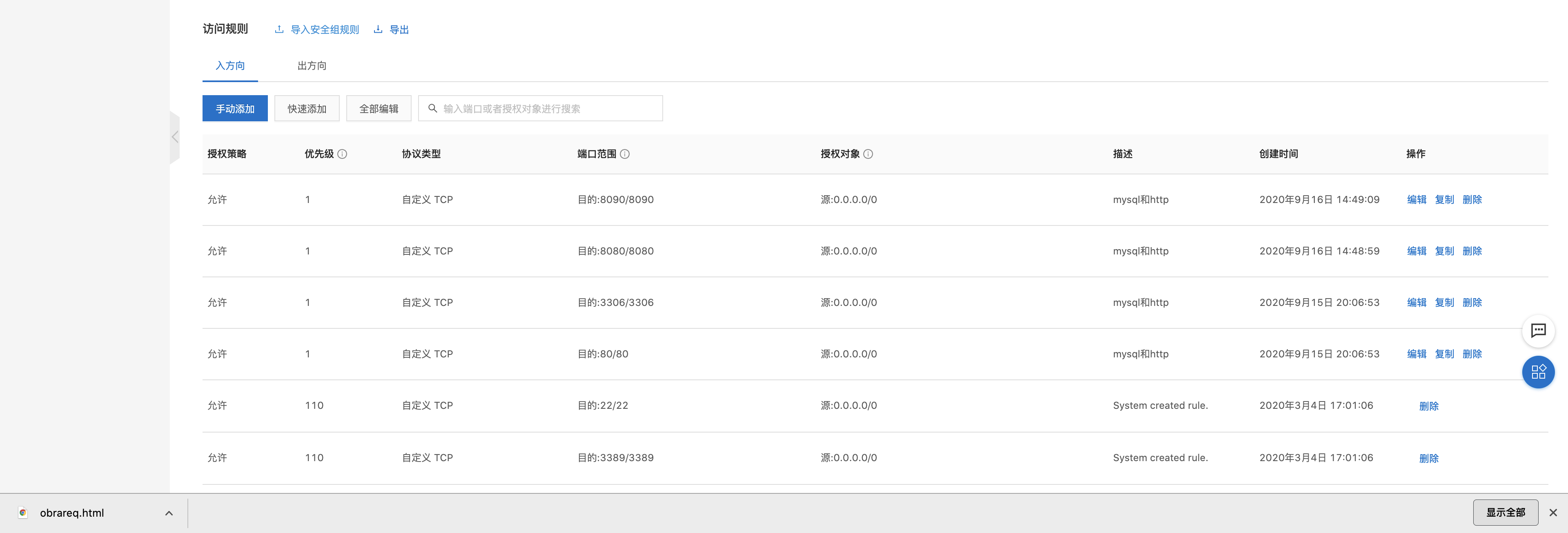
Centos yum安装tomcat8 (阿里云的端口坑!!!)
1.官网下载上传至服务器并解压 2.将解压下来的文件移动到自己的目录下 3.进入tomcat 的bin目录启动服务 4.配置 5.阿里云的端口 阿里云服务器 阿里云控制台打开端口:...

idea springboot项目热更新
前言 在项目开发过程中,常常会改动页面数据或者修改数据结构,为了显示改动效果,往往需要重启应用查看改变效果。这种开发体验无疑是很差的,Springboot为我们提供了devtools来帮助我们实现热更新。 使用springboot提供的spring-boot-devtools 添加devtools依赖 springboot maven插件配置 application.properties配置 启动...
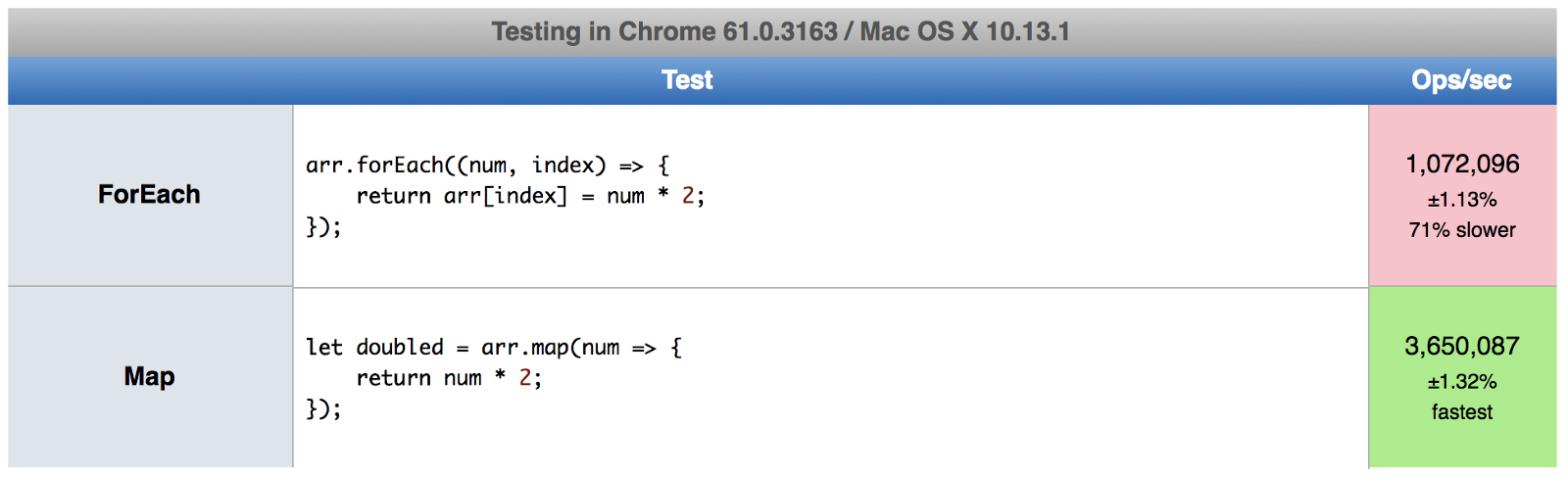
JavaScript中Map和ForEach的区别
译者按: 惯用Haskell的我更爱map。 原文: JavaScript — Map vs. ForEach - What’s the difference between Map and ForEach in JavaScript? 译者: Fundebug 为了保证可读性,本文采用意译而非直译。另外,本文版权归原作者所有,翻译仅用于学习。 如果你已经有使用JavaSc...