Python爬虫解析网页并生成m3u8文件
#-*- coding:gbk-*-
import urllib2
import re,sys,os
import json
import ssl
import urllib
reload(sys)
sys.setdefaultencoding("gbk")
context = ssl._create_unverified_context()
def get_data(url):
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36',
'Referer': 'https://qcfem364cngtx9jq66.amitaoapps.com',
}
print "get_data!\n"
try:
req = urllib2.Request(url, headers = header)
response = urllib2.urlopen(req,context=context,timeout=20)
html = json.loads(response.read())
except:
req = urllib2.Request(url, headers = header)
response = urllib2.urlopen(req,context=context,timeout=20)
html = json.loads(response.read())
with open("look.txt","wb") as f:
json.dump(html,f,indent=4,sort_keys=True)
return html
def get_content(text):
print "get_content!\n"
content=[]
for li in text["data"]:
get_id=li['id']
get_title=li['title']
get_pic=li['thumb']
data=[get_id,get_title,get_pic]
content.append(data)
return content
def get_m3u8(content,root):
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36',
'Referer': 'https://qcfem364cngtx9jq66.amitaoapps.com',
}
print ("get_m3u8! %d\n"% len(content))
if not os.path.exists("mitao"):
os.makedirs("mitao")
f=open(root,'w')
f.write("#EXTM3U\n")
reload(sys)
sys.setdefaultencoding('utf-8')
m3u8=[]
per=0
for txt in content:
base_url="https://qcfem364cngtx9jq66.amitaoapps.com/api/v3/node/detail?id="
all_url=base_url+str(txt[0])
while True:
try:
req = urllib2.Request(all_url, headers = header)
response = urllib2.urlopen(req,context=context,timeout=5)
text = json.loads(response.read())
break
except:
print "re_get_data!"
per+=1
print all_url+ " percent=" +str(round(((float(per)/len(content))*100), 2))+"%"
get_id=text["data"]['id']
get_title=text["data"]['title']
get_pic=text["data"]['cover']
get_url="https://cdn.first0351.com/"+text["data"]["play"][0]["url"]
f.write("#EXTINF:-1 ,"+get_title.encode("utf-8") + "\n" + get_url)
f.write("\n")
data=[get_id,get_title,get_pic,get_url]
m3u8.append(data)
return m3u8
def save_m3u8(list,root):
print "save_m3u8!\n"
if not os.path.exists("mitao"):
os.makedirs("mitao")
f=open(root,'w')
f.write("#EXTM3U\n")
reload(sys)
sys.setdefaultencoding('utf-8')
for line in list:
print (line[1]+"-->"+line[-1])
f.write("#EXTINF:-1 ,"+line[1] + "\n" + line[-1])
f.write("\n")
f.close()
try:
page=input(u"请输入下载的页面:\n".encode(sys.getfilesystemencoding()))
num=input(u"请输入该页面显示的数量:\n".encode(sys.getfilesystemencoding()))
search=raw_input(u"请输入关键字:\n".encode(sys.getfilesystemencoding()))
except:
page=input(u"请输入下载的页面:\n")
num=input(u"请输入该页面显示的数量:\n")
search=raw_input(u"请输入关键字:\n")
filter_con = (urllib.quote(search))
url="https://qcfem364cngtx9jq66.amitaoapps.com/api/v3/node/index?key=&tag_id=&actress_id=&filter="+filter_con+"&category_id=550&page="+str(page)+"&user_search_keys=&limit="+str(num)
root="mitao"
text=get_data(url)
content=get_content(text)
name="mitao/"+search+"_"+str(page)+"_"+str(num)+".m3u8"
m3u8=get_m3u8(content,name)
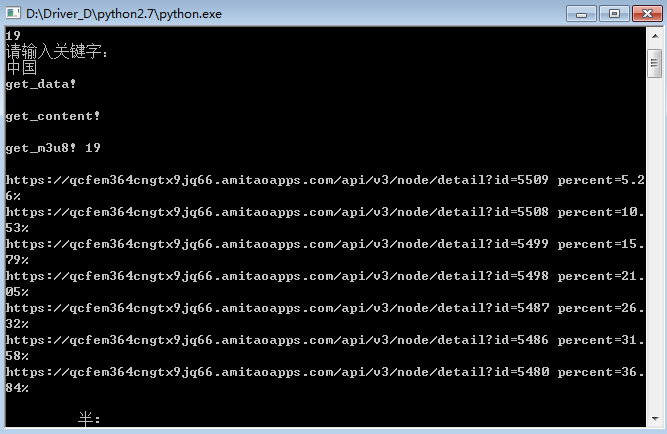
有搜索功能!
#-*- coding:utf-8 -*-
import urllib2
import re,sys,os
import json
import ssl
reload(sys)
sys.setdefaultencoding("utf-8")
context = ssl._create_unverified_context()
def get_data(url):
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36',
'Referer': 'https://qcfem364cngtx9jq66.amitaoapps.com',
}
print "get_data!\n"
try:
req = urllib2.Request(url, headers = header)
response = urllib2.urlopen(req,context=context,timeout=20)
html = json.loads(response.read())
except:
req = urllib2.Request(url, headers = header)
response = urllib2.urlopen(req,context=context,timeout=20)
html = json.loads(response.read())
with open("look.txt","wb") as f:
json.dump(html,f,indent=4,sort_keys=True)
return html
def get_content(text):
print "get_content!\n"
content=[]
for li in text["data"]:
get_id=li['id']
get_title=li['title']
get_pic=li['thumb']
data=[get_id,get_title,get_pic]
content.append(data)
return content
def get_m3u8(content,root):
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36',
'Referer': 'https://qcfem364cngtx9jq66.amitaoapps.com',
}
print ("get_m3u8! %d\n"% len(content))
if not os.path.exists("mitao"):
os.makedirs("mitao")
f=open(root,'w')
f.write("#EXTM3U\n")
m3u8=[]
per=0
for txt in content:
base_url="https://qcfem364cngtx9jq66.amitaoapps.com/api/v3/node/detail?id="
all_url=base_url+str(txt[0])
while True:
try:
req = urllib2.Request(all_url, headers = header)
response = urllib2.urlopen(req,context=context,timeout=5)
text = json.loads(response.read())
break
except:
print "re_get_data!"
per+=1
print all_url+ " percent=" +str((float(per)/len(content))*100)+"%"
get_id=text["data"]['id']
get_title=text["data"]['title']
get_pic=text["data"]['cover']
get_url="https://cdn.first0351.com/"+text["data"]["play"][0]["url"]
f.write("#EXTINF:-1 ,"+get_title + "\n" + get_url)
f.write("\n")
data=[get_id,get_title,get_pic,get_url]
m3u8.append(data)
return m3u8
def save_m3u8(list,root):
print "save_m3u8!\n"
if not os.path.exists("mitao"):
os.makedirs("mitao")
f=open(root,'w')
f.write("#EXTM3U\n")
for line in list:
print (line[1]+"-->"+line[-1])
f.write("#EXTINF:-1 ,"+line[1] + "\n" + line[-1])
f.write("\n")
f.close()
try:
page=input(u"请输入下载的页面:\n".encode(sys.getfilesystemencoding()))
num=input(u"请输入该页面显示的数量:\n".encode(sys.getfilesystemencoding()))
except:
page=input(u"请输入下载的页面:\n")
num=input(u"请输入该页面显示的数量:\n")
url="https://qcfem364cngtx9jq66.amitaoapps.com/api/v3/node/index?key=&tag_id=&actress_id=&filter=recommend&category_id=550&page="+str(page)+"&user_search_keys=&limit="+str(num)
root="mitao"
text=get_data(url)
content=get_content(text)
name="mitao/"+str(page)+"_"+str(num)+".m3u8"
m3u8=get_m3u8(content,name)
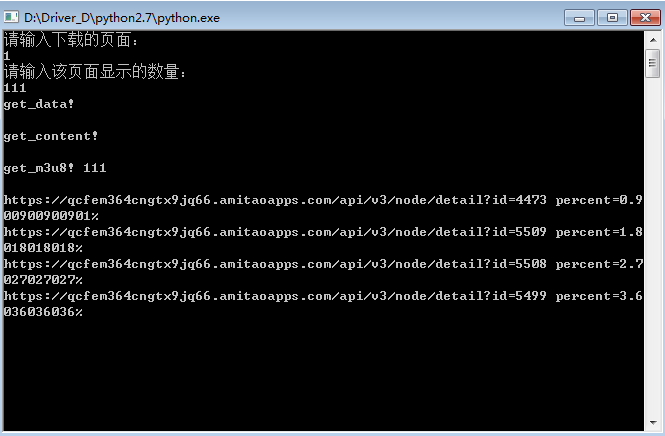
无搜索功能!
智能推荐
mp4视频分片生成m3u8流文件并加密
目录 场景描述 加密准备 视频分片 Java代码实现 场景描述 相信大家都有这样的经历,一个视频太大,放到服务器上面,播放的时候,受服务器宽带和自己网络的影响访问会很慢。 经常看视频的小伙伴肯定看到过下面的场景,网页上视频播放的时候,...
web安全简易规范123
web安全,大公司往往有专门的安全开发流程去保证,有专门的安全团队去维护,而对于中小网络公司,本身体量小,开发同时兼带运维工作,时间精力有限,但是,同样需要做一些力所能及的必要的事情。有时候,安全威胁并不是因为你的防盗窗被人撬开了,而是你晚上睡觉的时候忘了关门,而关上门对开发来说也许只是举手之劳。 1、不要用root,确定使用的中间件和框架是否默认打开了后门 我们总会在线上使用部署一些中间件、开源...


html5拖放--15行js代码实现两个div内容互换
本文首发于我的个人博客:http://cherryblog.site/ ,欢迎大家前去参观 本文项目地址,sortable插件地址:https://github.com/sunshine940326/sortable demo地址:https://github.com/sunshine940326/drag 在写我们后台的管理程序中需要有一个拖放的功能,然后我们有一个这样的功能,实现11个固定且大...

git切换分支报错,不管什么标题名字,都报非法字符,所以就不起名字了。
切换分支的时候,报了标题这么个错误,error: ”xxx did not match any file(s) known to git. 看见不能切换分支,我首先 git status 查看了一下当前状态,如下图 然后,就会发现,其实我的这个错误非常明显,就是在我的 beat 分支下有文件修改,所以切换不了。ok,解决方法: 1. 如果修改的这些文件没什么用,完全可以删除。(我这儿的...
猜你喜欢
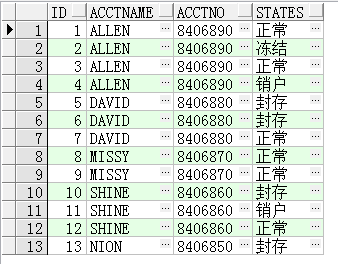
Oracle分析函数之LEAD和LAG实际应用
Oracle分析函数之LEAD和LAG实际应用 在前几天的工作中按照客户的需求,需要对客户信息进行数据分析,即某人存在多个状态的账号,将客户信息账号状态分析出结果,和客户确认汇报,根据保留规则,保留唯一账号,以保证程序可用性。起初,根据聚合函数进行查询分析,需要写一大串的SQL,即不美观又复杂,很容易产生错误。后续想到Oracle分析函数中的lead和lag,SQL简洁了很多且容易产生报告数据。 ...
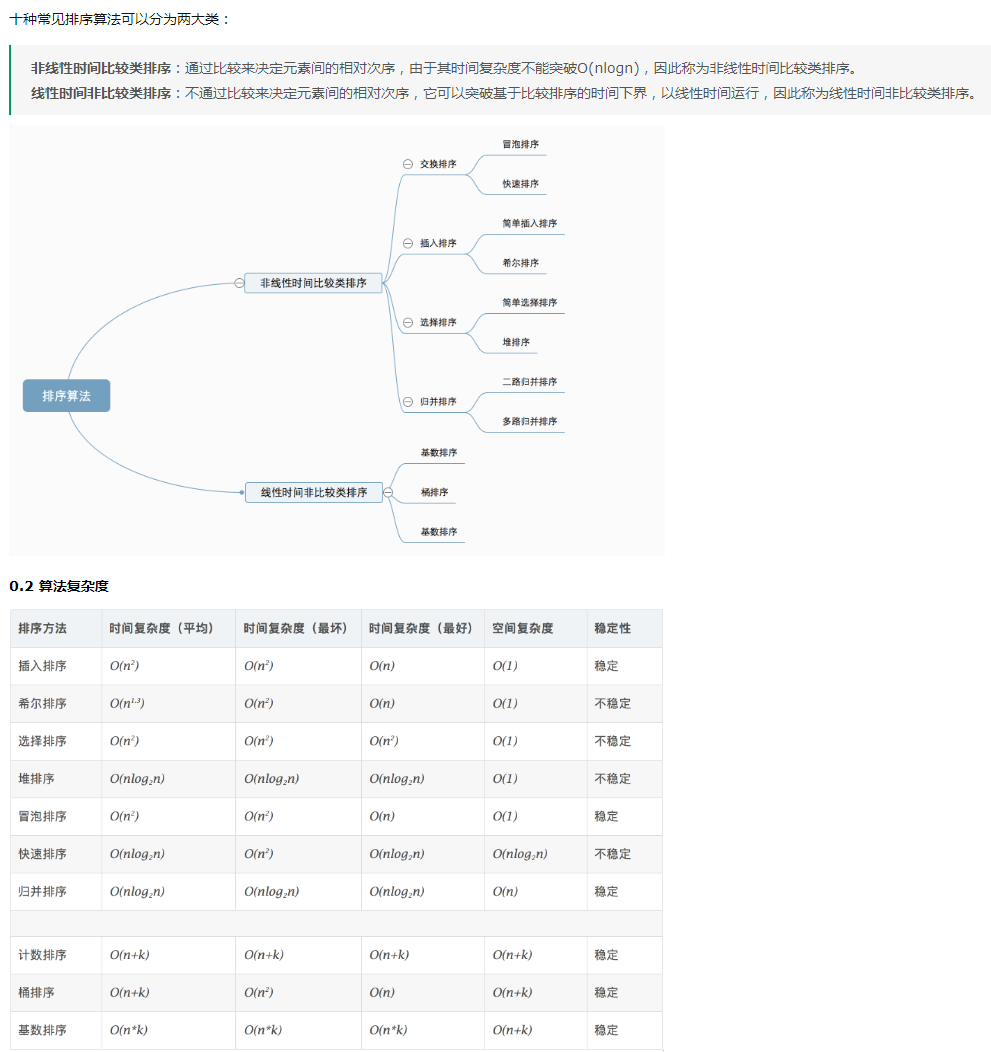
小知识积累(不断更新中)
判断变量的类型(数组,对象) tyopof:不推荐,因为无法区别数组与对象,数组是对象的子对象 instanceof:可以使用 还可以用来判断是否属于函数 Object.prototype.toString.call():最兼容,推荐使用 定时器的执行顺序或机制 js是单线程的,浏览器遇到setTimeout或者setInterval会把定时器推入浏览器的待执行事件队列里面但是不执行,先执行完当前...
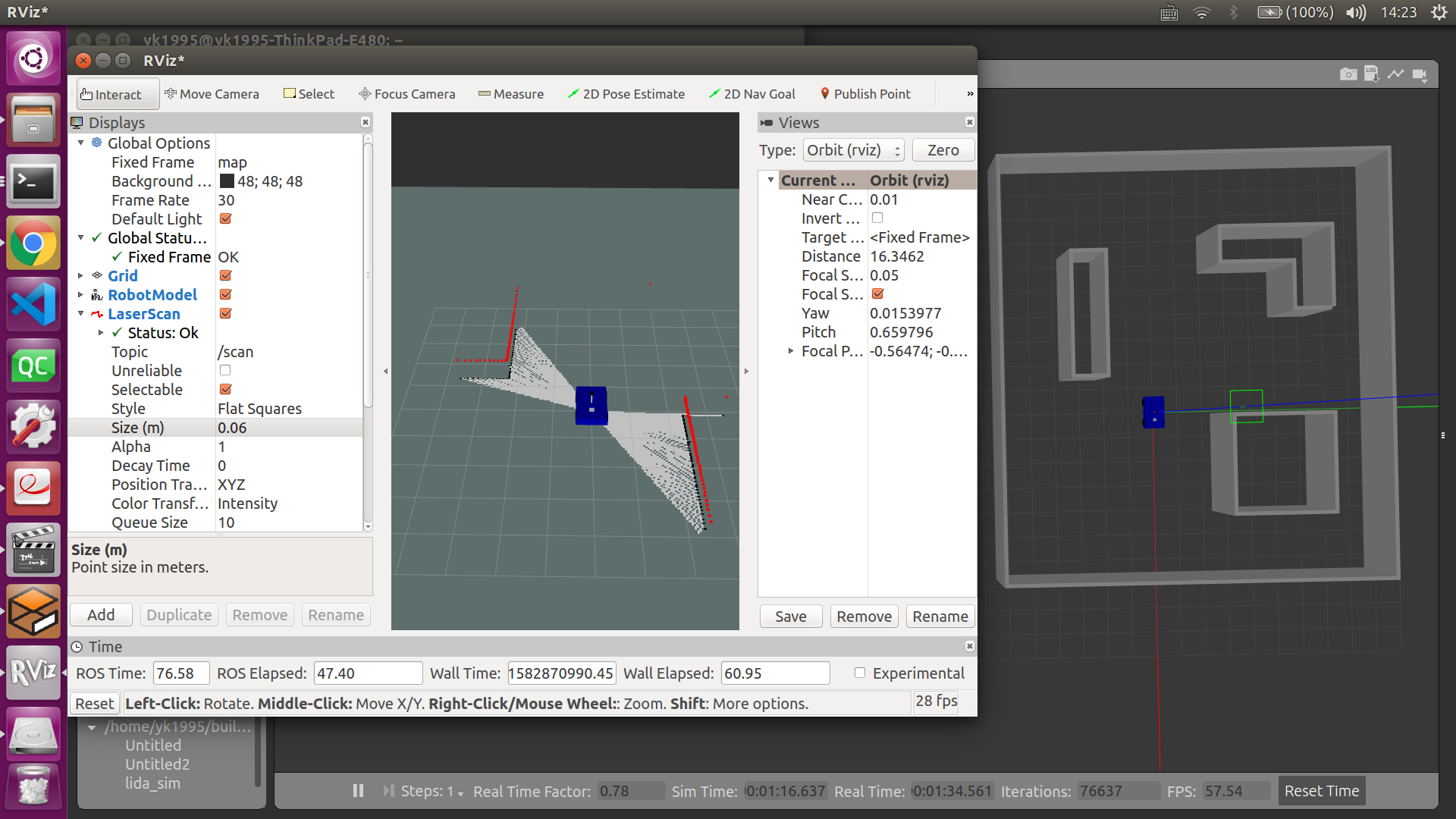
ROS自学实践(6):ROS进行激光SLAM建图——gmapping
本节主要记录运行ROS自带的SLAM建模包gmapping方法,为后续理解这些代码,建立自己的SLAM算法打下基础。 基于粒子滤波算法 二维栅格地图 需要里程计信息 1.通过命令行安装gmapping包 2.配置gmapping节点 3.运行gazebo模型及gmapping节点 4.打开rviz 添加laserscan、map、robotmodel模型 5.移动小车,建立模型 6.保存当前地图 ...

face-api.js中加入MTCNN:进一步支持使用JS实时进行人脸跟踪和识别
如果你现在正在阅读这篇文章,那么你可能已经阅读了我的介绍文章(JS使用者福音:在浏览器中运行人脸识别)或者之前使用过face-api.js。如果你还没有听说过face-api.js,我建议你先阅读介绍文章再回来阅读本文。 和往常一样,本文中为你准备了一个代码示例。我们将解析一个小的应用程序,这个程序将在浏览器中访问摄像头图像执行实时人脸检测和人脸识别,让我们开始吧! 使用face-api.js进行...
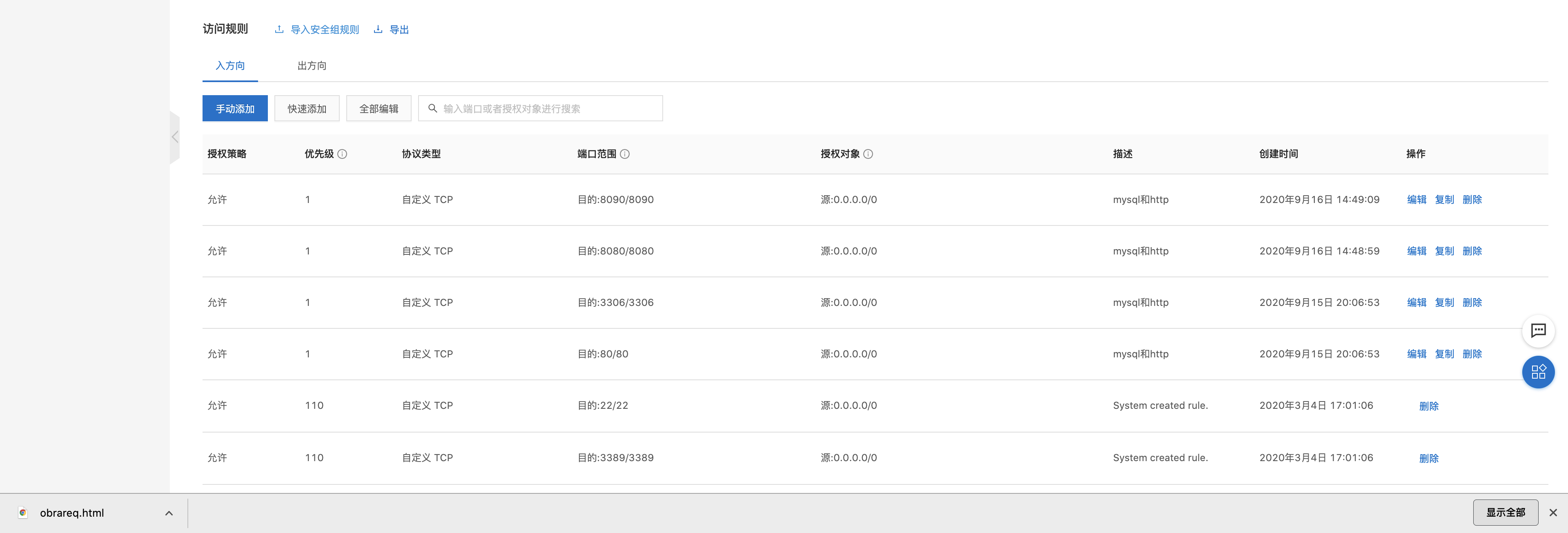
Centos yum安装tomcat8 (阿里云的端口坑!!!)
1.官网下载上传至服务器并解压 2.将解压下来的文件移动到自己的目录下 3.进入tomcat 的bin目录启动服务 4.配置 5.阿里云的端口 阿里云服务器 阿里云控制台打开端口:...