ES pinyin 插件 拼音搜索 原理 match_phase
标签: search es pinyin 拼音搜索 原理 match_phrase
背景
中文搜索很多时候都要用到pinyin搜索,基本绕不开这个插件;如搜索人名之类的;
介绍
插件github:地址
在README的最后,举的例子挺有意思;经过一系列操作之后,对刘德华建index,竟然搜liudh,刘dh,各种奇葩的搜索都能搜出来,这是为啥呢?让我们来仔细分析一下。
如官网的配置
配置analyzer
PUT /medcl3/
{
"settings" : {
"analysis" : {
"analyzer" : {
"pinyin_analyzer" : {
"tokenizer" : "my_pinyin"
}
},
"tokenizer" : {
"my_pinyin" : {
"type" : "pinyin",
"keep_first_letter":true,
"keep_separate_first_letter" : true,
"keep_full_pinyin" : true,
"keep_original" : false,
"limit_first_letter_length" : 16,
"lowercase" : true
}
}
}
}
}
主要是用了分词器tokenizer:my_pinyin。
具体的设置是,
keep_first_letter: true ; 也就是会将刘德华 -> ldh
keep_seperate_first_letter: true; 将刘德华 -> l 、 d 、 h
keep_full_pinyin: true; 将刘德华 -> liu, de, hua
有了这些设置之后,我们发现对刘德华进行analyze:
GET /hjxtest_pinyin/_analyze
{
"text": "刘德华",
"analyzer": "pinyin_analyzer"
}
得到结果就是上面说的这7个key
{
"tokens": [
{
"token": "l",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 0
},
{
"token": "liu",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 0
},
{
"token": "ldh",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 0
},
{
"token": "d",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 1
},
{
"token": "de",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 1
},
{
"token": "h",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 2
},
{
"token": "hua",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 2
}
]
}
然后我们建好index,搜索liudh的时候,会先用相同的分词方法分词:
GET /hjxtest_pinyin/_analyze
{
"text": "liudh",
"analyzer": "pinyin_analyzer"
}
分词结果
{
"tokens": [
{
"token": "liu",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 0
},
{
"token": "liudh",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 0
},
{
"token": "d",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 1
},
{
"token": "h",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 2
}
]
}
可见,我们牛皮的分词器,会分词出结果 liu + d + h + liudh
回顾我们建的倒排索引: liu de hua l d h ldh
搜索的时候
liu d h都能找到咱们的文档,当然就可以搜到结果了:
GET /hjxtest_pinyin/_search
{
"query": {"match": {
"name.pinyin": "liudh"
}}
}

但是我们发现一个有意思的现象,当我们搜liudh的时候,竟然会把黄渤也搜出来,这是什么鬼?
盲猜是因为 analyze的时候,黄渤 analyze的结果是:
huang + bo + h + b + hb
然后搜索的时候跟liudh的h match上了
验证一下: 黄渤 analyze的结果是:
{
"tokens": [
{
"token": "h",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 0
},
{
"token": "huang",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 0
},
{
"token": "hb",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 0
},
{
"token": "b",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 1
},
{
"token": "bo",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 1
}
]
}
果然跟猜想的一致。
那怎么办呢,这种准确率也太低了吧
我们看到github上给的查询例子实际上是match_phase而不是match
区别是啥?参看官网

match_phrase要求query和doc不仅要在term上有交集,还需要顺序保持一致
具体到我们这个例子,我搜liudh 文档里的liu d h 也必须匹配着顺序出现,所以就只有刘德华可以匹配上了:
GET /hjxtest_pinyin/_search
{
"query": {"match_phrase": {
"name.pinyin": "liudh"
}}
}

这样就提高了准确率了。

智能推荐
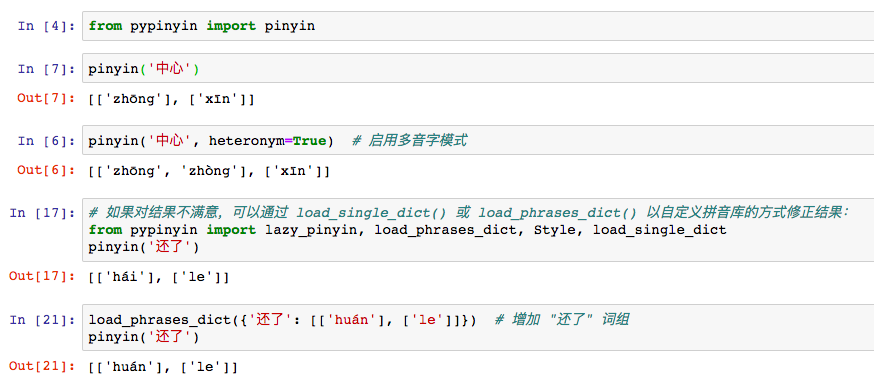
汉字拼音转换工具 pypinyin 和pinyin 安装使用比对记录
将汉字转为拼音。可以用于汉字注音、排序、检索 记录整理两个包的安装使用过程 pypinyin和pinyin pypinyin: https://pypi.org/project/pypinyin/ 作者mozillazg, 闲耘 pinyin: https://pypi.org/project/pinyin/ 作者Author: Lx Yu pypinyin 安装pypinyin包 查看安装的包的...
探索PinYin4j.jar将汉字转换为拼音的基本用法
将汉字转换为拼音在Android开发中是个很常见的问题。例如:在android手机应用开发中,要查询联系人的姓名,通常都是用拼音进行查询的。 Pinyin4j是一个功能强悍的汉语拼音工具包,是sourceforge.net上的一个开源项目。 主要的功能有: - 支持同一汉字有多个发音 - 支持拼音的格式化输出,比如第几声之类的 - 支持简体中文、繁体中文转换为拼音 首先,在Android Stud...

linux上安装Qt4.8.6+QtCreator4.0.3
一、Qt简介 Qt是1991年奇趣科技开发的一个跨平台的C++图形用户界面应用程序框架。它提供给应用程序开发者建立艺术级的图形用户界面所需的所有功能。Qt很容易扩展,并且允许真正地组件编程。 准备工作 操作系统:centos6.5 位数:64位 二、安装 1、获取源码Qt4.8.6 2、获取源码QtCreator4.0.3 2、安装QtCreator4.0.3 进入QtCreator安装界面,指定...
react-native metro 分析
文章目录 前言 概念 Resolution Transformation Serialization 打包方式 Moudles Plain bundle Indexed RAM bundle File RAM bundle 流程 前置流程 resolve流程 Transformer流程 序列化流程 缓存 为什么要缓存 缓存的请求与缓存 Metro配置 结构 前言 metro是一种支持ReactNa...
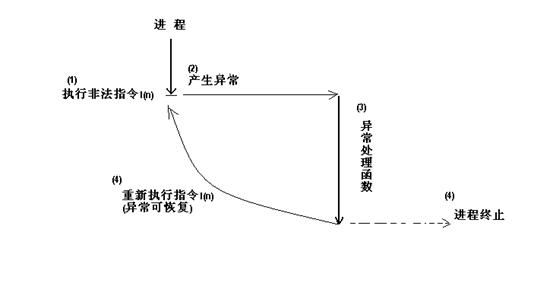
嵌入式Linux——应用调试:用户态打印段错误信息
简介: 很多时候我们会遇到段错误:segmentation fault,而段错误有时是由内核引起的,有时是由应用程序引起的。在内核态时,发生段错误时会打印oops信息,但是在用户态时,发生段错误却只会打印segmentation fault而并不会打印其他的信息。所以本文主要介绍在用户态时,通过修改内核设置和添加启动参数来打印引发segmentati...
猜你喜欢
springboot1.4.1整合logback 遇到的问题
springboot1.4.1整合logback 遇到的问题 项目使用了springboot1.4.1整合logback,然而设置的过期时间15 并没有生效, 2GB达到2G自动删除也没有生效,仅仅实现了按大小分割。 经过查看pom 父工程内的源码发现是默认的logback版本是1.1.7,而过期时间配置是在logback 1.1.8以后才支持的。 不得不说这是springboot1.4.1 的b...
记一次C/S架构的渗透测试
概述 目标站点是http://www.example.com,官网提供了api使用文档,但是对其测试后没有发现漏洞,目录、端口扫描等都未发现可利用的点。后发现官网提供了客户端下载,遂对其进行一番测试。 信息收集 先抓了下客户端的包,使用Fiddler和BurpSuite都抓不到,怀疑走的不是HTTP协议,用WireShark查看其确实用的是HTTP协议,但是数据包不好重放,这里最后使用了WSExp...

Linux:结合Securecrt进行文件上传(lrzsz)P2
1、安装rzsz软件 2、点击Scurecrt的option——X/Y/Z配置上传和下载目录 3、首先在Linux里切换到一个目录,然后用rz命令,文件就会上传到钙Linux的目录下 只要敲rz即可,然后在弹出的对话框里选择需要上传的文件即可 4、下载文件用sz 下载单个文件:在当前目录下有该文件 sz filename 下载...

SQL 提示作为 布局 生存工具指南
下面是一些展示AdventureWorks中表现最好的销售人员并列出他们的经理的结构化查询语言代码。 它产生以下结果。 所以,代码是有效的,但它是丑陋的。 如果我需要理解和改进代码,我首先需要把它变成可读的形式。 我有结构化查询语言提示,所以我可以按下计算机的ctrl按键键 踢你自己),它会应用默认的内置代码样式,并对此进行修复。 不,不是,因为我相信你仍然不喜欢它的格式。 没有两个开发人员能够就...
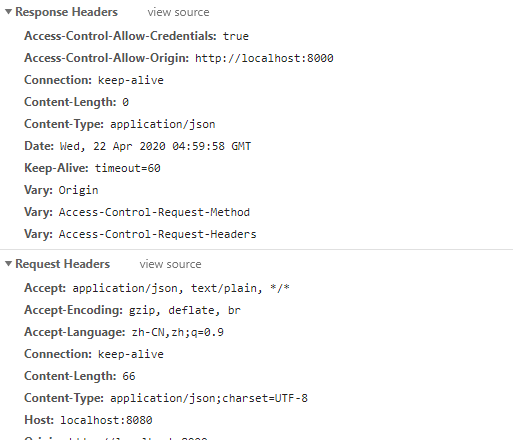
Vue+Springboot解决数据传输时参数格式不匹配问题
前端:使用的是ant design vue ,端口号为8000 后端:使用的是springboot框架开发,端口号为8080 需求:已经解决跨域问题,前端发送登录的信息给后台,后台接收不到 样例: 前端: 后台: 请求的数据格式为json格式,后台参数类型不匹配 解决方案 第一种: 修改后端,参数类型: 第二种方式: 在前端vue框架中加入qs插件,qs 是一个增加了一些安全性的查询字符串解析和序...