UVM——sequence机制(五)
标签: UVM
sequence机制【上】
一、sequence的执行流程
控制和产生一系列的激励,并通过sequencer将激励发送给driver的机制。如果按照交通道路的车流来打比方,sequence就是道路,sequence item是道路上行驶的货车,sequencer是目的地的关卡,而driver便是最终目的地卸货的地方。从软件实施的层面来讲,这里的货车是从sequence一端出发的,再经过了sequencer,最终抵达了driver,经过driver的卸货,每一辆的货车也就完成了它的使命。而driver对每一件到站的货物,经过它的扫面处理,将它分解为更小的信息量,提供给DUT。
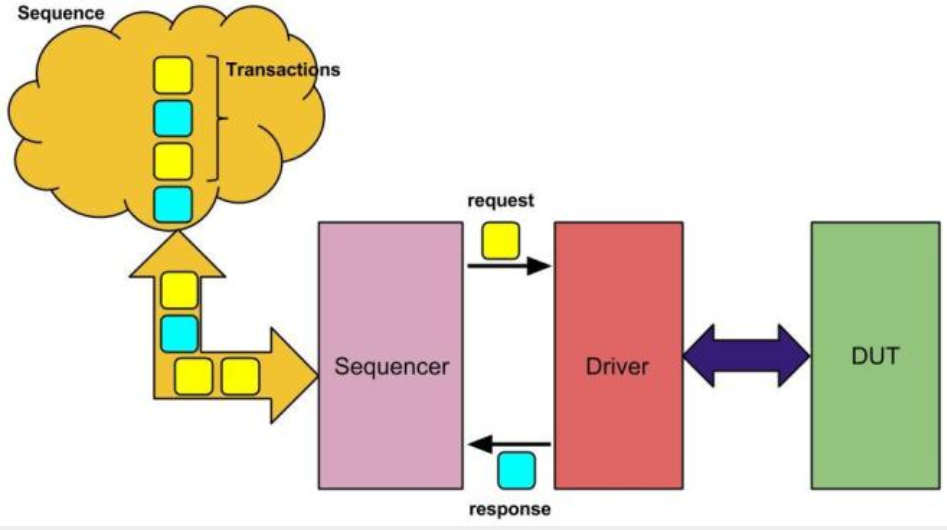
Sequence是一个产生和发送数据的过程,会消耗仿真时间。只有在task_phase中才会启动。 sequence item是每一次driver与DUT互动的最小粒度内容,在sequence与driver之间起到桥梁作用的是sequencer,sequencer与driver均是component组件,sequence item和sequence是基于uvm_object,可以在任何阶段建立。uvm_object独立于build阶段之外。且基类具备核心方法,copy(),clone(),compare()等。
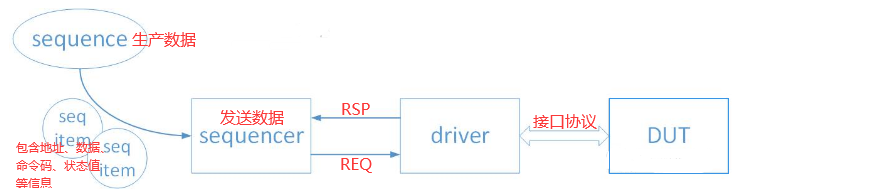
- uvm_sequence_item(
包装数据):只能对数据进行封装,不存在自动执行的函数; - uvm_sequence(
生产数据):具有可自动执行的函数,可通过body()函数进行可执行操作,产生数据激励; - uvm_sequencer(
发送数据):将数据发送给driver;
- sequence对象自身会产生目标数量的sequence item对象。借助于SV的随机化和sequence item对随机化的支持,使得产生的每个sequence item对象中的数据内容都不相同。
- 产生的sequence item会经过sequencer再流向driver。
- driver得到了每一个sequence item,经过数据解析,再将数据按照与DUT的物理接口协议写入到接口上,对DUT形成有效激励。
- 必要时,driver在每解析并且消化完一个sequence item,也会将最后的状态信息同sequence item对象本身再度返回给sequencer,最终抵达sequence对象一侧。这么做的目的在于,有的时候sequence需要得知driver与DUT互动的状态,这就需要driver仍然有一个回路再将处理了的sequence item对象和状态信息写回到sequence一侧。
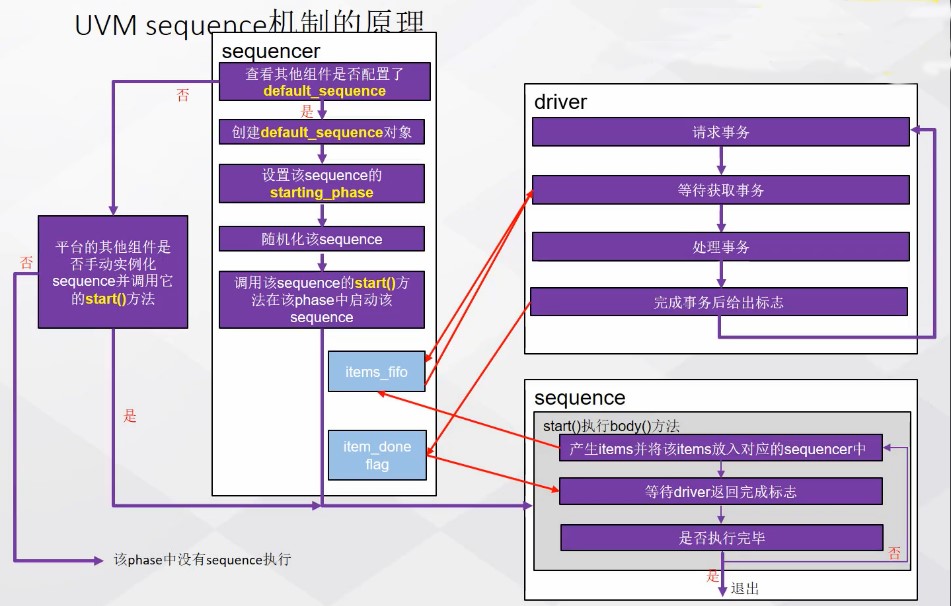
1、Sequencer: 当sequencer启动时,首先会检查自身的default_sequence是否配置,如果配置了就会创建实体,设置该sequence的starting_phase并随机化该sequence。最后调用sequence的start()函数启动该sequence。
2、Sequence:当sequence的start的函数启动,sequence会执行body方法,产生事物,并将事物发送给sequencer放入FIFO中储存。Sequence会等待一个driver的完成响应,得到之后会退出该次事物的产生。
3、Driver:首先向sequencer发送一个事物请求,然后等待事物,sequencer会将产生好的事物发送给driver,driver在处理完该事物后,返回一个完成响应。
二、sequence和item
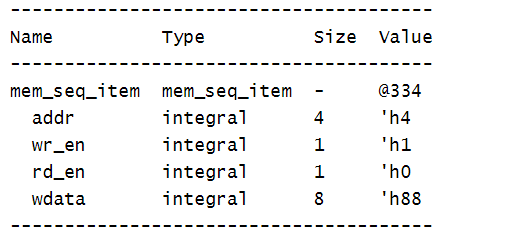
看下面一个完整的sequence item例子(我们注意到sequence item不需要使用宏在工厂中注册):
class mem_seq_item extends uvm_sequence_item;//sequence item不需要在factory中注册
//Control Information
rand bit [3:0] addr;
rand bit wr_en;
rand bit rd_en;
//Payload Information
rand bit [7:0] wdata;
//Analysis Information
bit [7:0] rdata;
//Utility and Field macros,
`uvm_object_utils_begin(mem_seq_item)//这也是一种注册宏
`uvm_field_int(addr,UVM_ALL_ON)
`uvm_field_int(wr_en,UVM_ALL_ON)
`uvm_field_int(rd_en,UVM_ALL_ON)
`uvm_field_int(wdata,UVM_ALL_ON)
`uvm_object_utils_end
//Constructor
function new(string name = "mem_seq_item");
super.new(name);
endfunction
//constaint, to generate any one among write and read
constraint wr_rd_c { wr_en != rd_en; };
endclass
//-------------------------------------------------------------------------
//Simple TestBench to create and randomize sequence item
//-------------------------------------------------------------------------
module seq_item_tb;
//instance
mem_seq_item seq_item;
initial begin
//create method
seq_item = mem_seq_item::type_id::create();//创建对象:句柄名=类名::type_id::create();
//randomizing the seq_item
seq_item.randomize();//随机化对象
//printing the seq_item
seq_item.print();//打印:对象名.print();
end
endmodule
-
如果item数据域用来做驱动,应该考虑定义为rand类型,并给出合适的constraint。
-
由于item本身的数据属性,为了充分利用UVM域声明的特性,我们建议将必要的数据成员都通过`uvm_field_xxx宏来声明。
-
如果按照item对象的生命周期来区分,它的生命应该开始于sequence中的创建,而后经历了随机化和穿越sequencer最终到达driver,直到被driver消化之后,它的生命周期一般来讲才算寿终正寝。
sequence可以分类为:
- 扁平类(flat sequence)。这一类中往往只用来组织更细小的粒度,即item示例的组织。
- 层次类(hierarchical sequence)。这一类则是由更高层的sequence用来组织底层的sequence,进而让这些sequence或者按照顺序的方式,或者按照并行的方式,挂载到同一个sequencer上。
- 虚拟类(virtual sequence)。这一类则是最终控制整个测试场景的方式,鉴于整个环境中往往存在不同种类的sequencer和其对应的sequence,我们需要一个虚拟的sequence来协调顶层的测试场景。之所以称这个方式为virtual sequence,是因为该序列本省并不固定挂载于某一种sequencer类型上,而是它会将其内部的各种不同类型的sequence最终挂载到不同的目标sequencer上面。这也是最大的不同于hierarchical sequence的一点。
三、Sequence 和 Driver
driver同sequencer之间的TLM通信采取了get模式,即由driver发起请求,从sequencer一端获得item,再由sequencer将其传递至driver。按照TLM通信模式的描述, TLM通信可以绘制为下图:

UVM专门定义了匹配的TLM端口供sequencer和driver使用:
-
uvm_seq_item_pull_port #(type REQ=uvm_sequence_item, type RSP=REQ) -
uvm_seq_item_pull_export #(type REQ=uvm_sequence_item, type RSP=REQ) -
uvm_seq_item_pull_imp #(type REQ=uvm_sequence_item, type RSP=REQ, type imp=int)
用户可以不在定义sequence或者driver时指定sequence item类型,使用默认类型REQ = uvm_sequence_item。RSP类型与REQ类型保持一致,这么做的好处是为了便于统一处理,方便item对象的拷贝、修改等操作。
由于driver是请求发起端,所以在driver一侧例化了下面的两种端口:
-
uvm_seq_item_pull_port #(REQ, RSP) seq_item_port -
uvm_analysis_port #(RSP) rsp_port
而sequencer一侧则为请求的响应端,在sequencer一侧例化了与上面对应的两种端口:
-
uvm_seq_item_pull_imp #(REQ, RSP, this_type) seq_item_export -
uvm_analysis_export #(RSP) rsp_export
uvm_driver中有一个派生自uvm_seq_item_pull_port的成员 **seq_item_port**;
uvm_sequencer中有一个派生自uvm_seq_item_pull_imp的成员**seq_item_export**。
Driver应该使用uvm_seq_item_pull_port内含的多种方法实现sequence->sequencer->driver的数据传输以及driver->sequence的反馈机制:
-
task get_next_item(output REQ req_arg):采取blocking的方式等待从sequence获取下一个item。
-
task try_next_item(output REQ req_arg):采取nonblocking的方式从sequencer获取item,如果立即返回的结果req_arg为null,则表示sequence还没有准备好。
-
function void item_done(input RSP rsp_arg=null):用来通知sequence当前的sequence item已经消化完毕,可以有选择性地传递RSP参数,返回状态值。
-
task wait_for_sequences():等待当前的sequence直到产生下一个有效的item。
-
function bit has_do_available():如果当前的sequence准备好而且可以获取下一个有效的item,则返回1,否则返回0。
-
function void put_response(input RSP rsp_arg):采取nonblocking方式发送response,如果成功返回1,否则返回0。
-
task get(output REQ req_arg):采用get方式获取item。
-
task peek(output REQ req_arg):采用peek方式获取item。
-
task put(input RSP rsp_arg):采取blocking方式将response发送回sequence。
uvm_seq_item_pull_* 类型的TLM端口含有许多特殊的可调用方法,Driver可以使用这些方法来从Sequencer的FIFO中得到transaction,告知transaction使用完毕,也可以将处理完的transaction返回给Sequence。
3.1.Driver有哪些操作
uvm_driver实际上是一个具有TLM通信端口的uvm_component的子类,用来与Sequencer进行通信,将Sequence产生transaction通过Interface发送给DUT,需要时也会将transcation反馈给Sequence。
uvm_driver具有两个参数,一个request另一个是response,默认情况下这两个参数的类型是一致的,一般会被指定为用户定义的transaction类型。这两个参数也是uvm_driver自带的seq_item_port的参数类型。
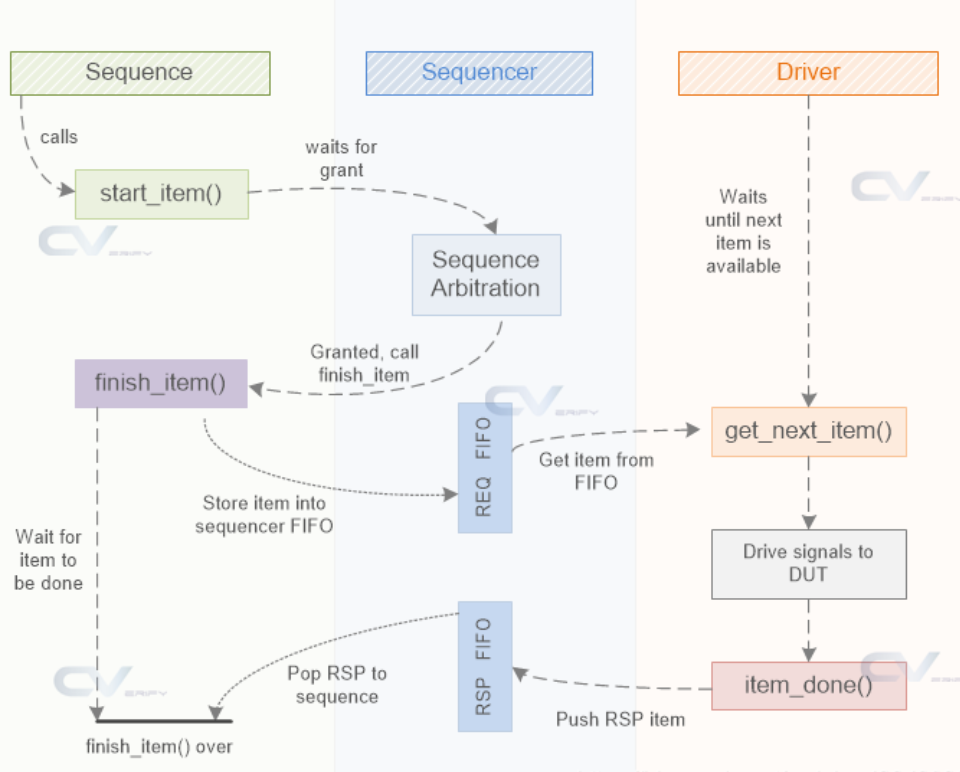
如上所示,Driver与Sequencer进行通信主要就是依靠uvm_seq_item_pull_port派生的TLM端口seq_item_port的上述多种方法。所以其实也可以不用uvm_driver来派生Driver,只需要在Driver中自行定义seq_item_port并指定好参数类型,并与Sequencer的seq_item_export连接,进而调用seq_item_port的方法即可。
Driver调用get_next_item()时,Sequencer中的FIFO会pop出一个transaction送给Driver,Driver将这个transaction的数据驱动给DUT后,需要和Sequence达成握手,告诉它这笔transaction已经使用完了,可以发送下一个transaction了(否则sequence会阻塞在`uvm_do或finish_item等指令上),所以它会调用seq_item_port的item_done()函数。
在driver消化完当前的request,即可以通过item_done(input RSP rsp_arg=null)方法来告知sequence此次传输已经结束,参数中的RSP可以选择填入,返回正确的状态值。driver也可以单独通过put_response()或者put()方法来单独发送response。此外,发送response还可以通过成对的uvm_driver::rsp_port和uvm_driver::rsp_export端口来完成,方法为uvm_driver::rsp_port::write(RSP)来完成。
在定义driver时,在它的主任务driver::run_phase()中也应通常做出如下的处理:
-
通过seq_item_port.get_next_item(REQ)从sequencer获取有效的request item。
-
从request item中获取数据,进而产生数据激励。
-
对request item进行克隆生成新的对象response item。
-
修改response item中的数据成员,最终通过seq_item_port.item_done(RSP)将response item对象返回给sequence。
3.2.Sequence有哪些操作
Sequence是uvm_sequence的子类,它同样是参数化的类,一个参数是REQ,对应发送的transaction的类型,一个是RSP,对应Driver反馈的transaction类型,一般来说两种相同。
Sequence在与Driver的通信中负责发送transaction。很多Sequence使用`uvm_do等系列宏来操作,uvm_do宏实际上是将transaction的实例化、随机化、start_item、finish_item放在了一个操作里。其中最主要的是start_item,和finish_item任务,它们实际上又是由以下方法组成:(下章会细聊这块)
create_item(item) \
sequencer.wait_for_grant(prior) (task) \ start_item \
parent_seq.pre_do(1) (task) / \
`uvm_do* macros
parent_seq.mid_do(item) (func) \ /
sequencer.send_request(item) (func) \finish_item /
sequencer.wait_for_item_done() (task) /
parent_seq.post_do(item) (func) /
所以Sequence操作细分入下:
- 创建item
- 通过start_item(),等待获得sequence的授权许可,其后执行parent sequence的方法pre_do()。
- 对item进行随机化处理
- 通过finish_item(),在对item进行了随机化处理之后,执行parentsequence的mid_do(),以及调用uvm_sequencer::send_request()和uvm_sequencer::wait_for_item_done()来将item发送至sequencer再完成与driver之间的握手。最后,执行了parent_sequence的post_do()。
3.3.使用get()和put()完成通信
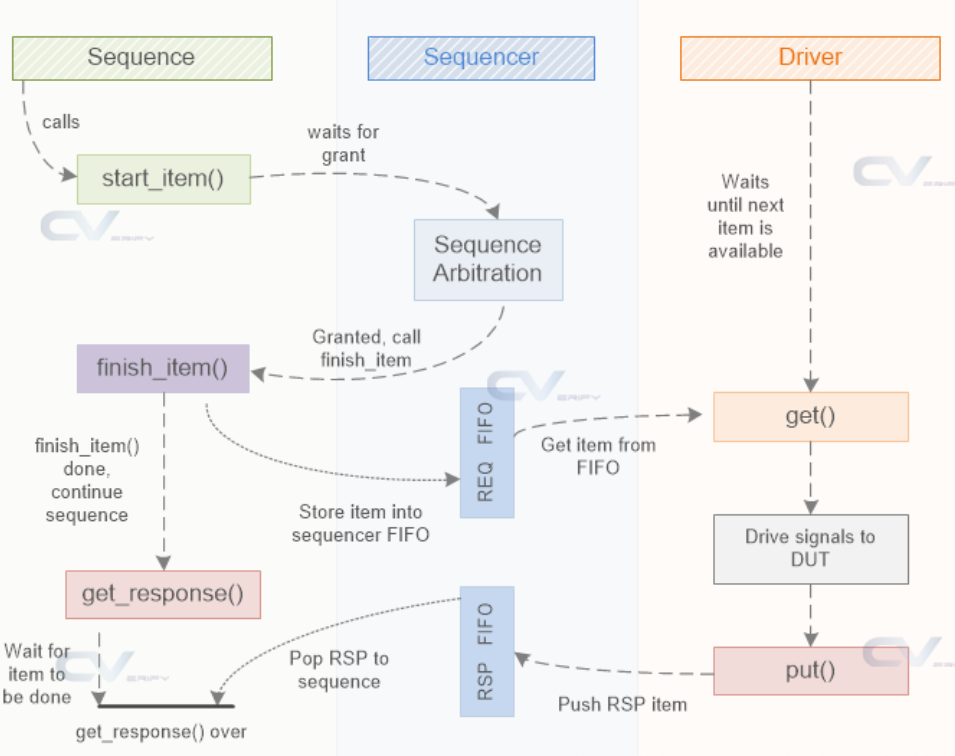
上面提到Driver使用get_next_item()获得item,使用item_done()通知sequence使用完成。此外还有使用get()和put()达成接收transaction和反馈的操作:
在Driver中:
class my_driver extends uvm_driver #(my_data);
`uvm_component_utils (my_driver)
virtual task run_phase(uvm_phase phase);
super.run_phase(phase);
// 1. Get an item from the sequencer using "get" method
seq_item_port.get(req);
// 2. For simplicity, lets assume the driver drives the item and consumes 20ns of simulation time
#20;
// 3. After the driver is done, assume it gets back a read data called 8'hAA from the DUT
// Assign the read data into the "request" sequence_item object
req.data = 8'hAA;
// 4. Call the "put" method to send the request item back to the sequencer
seq_item_port.put(req);
endtask
endclass
在Sequence中:
class my_sequence extends uvm_sequence #(my_data);
`uvm_object_utils (my_sequence)
// Create a sequence item object handle to store the sequence_item contents
my_data tx;
virtual task body();
// 1. Create the sequence item using standard factory calls
tx = my_data::type_id::create("tx");
// 2. Start this item on the current sequencer
start_item(tx);
// 3. Do late randomization since the class handle pointers are the same
tx.randomize();
// 4. Finish executing the item from the sequence perspective
// The driver could still be actively driving and waiting for response
finish_item(tx);
// 5. Because "finish_item" does not indicate that the driver has finished driving the item,
// the sequence has to wait until the driver explicitly tells the sequencer that the item is over
// So, wait unitl the sequence gets a response back from the sequencer.
get_response(tx);
`uvm_info ("SEQ", $sformatf("get_response() fn call done rsp addr=0x%0h data=0x%0h, exit seq", tx.addr, tx.data), UVM_MEDIUM)
endtask
endclass
首先在Driver中使用get()方法从Sequencer中获得了transaction,并进行了处理(比如驱动DUT)。事实上get()和get_next_item()的区别在于get()中调用了item_done()函数,所以可以发现在上面的代码中,get到了transaction后并没有item_done()操作。使用get()后,在Sequence中finish_item也紧接着结束。可以查看https://www.chipverify.com/uvm/driver-using-get-and-put中的举例的运行结果进行验证。
之后再使用put()方法将处理完的req返回给Sequence。需要注意两点:put()与put_response()的区别是,put()是阻塞的,而put_response()是非阻塞的,并且前者是任务,后者是由返回值的函数;此外上面代码中put()的反馈回去的参数是req,也是接收的transaction,实际上一般使用rsp,这会在下面的内容中讨论。
在Sequence中,其它部分和之前一样,主要差别是使用了get_response方法获得反馈的transaction,这是一个阻塞的方法,只有成功的获得返回数据后,它才会结束阻塞。
所以使用get()和put()加上get_response()建立的sequence->sequencer->driver通信主要是为了反馈机制。这种情况下,一个item的周期始于item creat,结束于get_response()。
3.4.response机制:Driver->Sequence的反馈
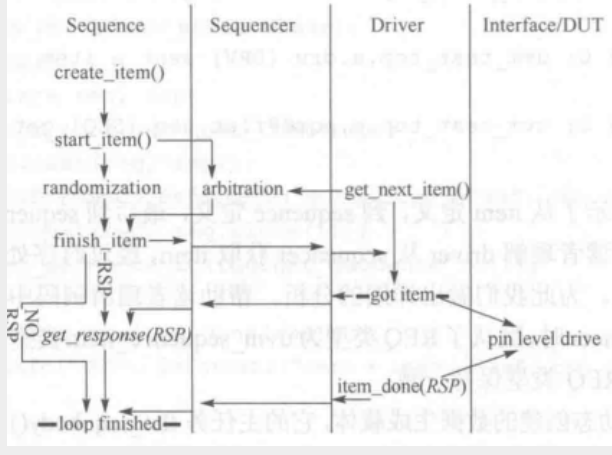
1、上图是完整的TLM通讯,对于Sequence而言,流向Sequencer都是sequence item。始于create_item(),继而通过start_item()尝试从sequencer获取可以通过的权限。如果没有transaction,可以调用get_next_item()来尝试从sequence一侧获取item。
2、接下来sequence中的item将穿过sequencer到达driver一侧,这个重要节点标志着sequencer第一次充当通信桥梁的角色已经完成。
3、driver在得到新的item之后,会提取有效的数据信息,将其驱动到与DUT连接的接口上面。
4、在完成驱动后,driver应当通设item_done()来告知sequence已经完成数据传送,而sequence在获取该消息后,则表示driver与sequence双方完成了这一次item的握手传输。
5、在这次传递中,driver可以选择将RSP作为状态返回值传递给sequence,而sequence也可以选择调用get_response(RSP)等待从driver一侧获取返回的数据对象。
在Sequence中就只有一种方法获得返回的item: get_response()。
seq_item_port.get_next_item(req);
$cast(rsp,req.clone());
drive_one_pkt(req);
rsp.set_id_info(req);//回response 一定要加上这句!!!
seq_item_port.put(rsp);
seq_item_port.item_done();
-
在多个sequence同时向sequencer发送item时,就需要有ID信息表明该item从哪个sequence来,这个ID信息在sequence创建item时就赋值了,而在到达driver以后,这个ID也能用来跟踪它的sequence信息
-
如果使用rsp作为response的话,一定要加上rsp.set_id_info(req)这句,这个方法会将req中的信息复制给rsp,包括id信息。由于可能存在多个Sequence在同一个Sequencer上启动的情况,只有设置了rsp的id等信息,sequencer才知道将response返回给哪个Sequence。实际上这句话也可以用下面的代码替代:
void’($cast (rsp, req.clone( ));
rsp.set_sequence_id (req.get_sequence_id ( )); -
response的机制原理是driver将rsp推送给Sequencer,而Sequencer内部维持一个队列,当有新的response进入时,就推入此队列,Sequence中的get_response()就是从这个队列中取出返回数据。这个队列的大小为8,当只有put的情况而没有get情况下,队列中存满了8个response时,会发出溢出错误提示。
-
有时为了“简便”,会直接使用req作为反馈给Sequence的response transaction,这样做的好处是不用做set_id_info操作,也不用声明rsp。这么做看来,似乎节能环保,但实际上殊不知可能埋下隐患,一方面它延长了本来应该丢进垃圾桶的request item寿命,同时也无法再对request item原始生成数据做出有效记录。
-
此外还能使用uvm_dirver中自带的rsp_port和uvm_sequence中对应的rsp_export来达成反馈机制。
参考:https://blog.csdn.net/wonder_coole/article/details/90665876
https://blog.csdn.net/weixin_46017929/article/details/107154495
智能推荐
react-native metro 分析
文章目录 前言 概念 Resolution Transformation Serialization 打包方式 Moudles Plain bundle Indexed RAM bundle File RAM bundle 流程 前置流程 resolve流程 Transformer流程 序列化流程 缓存 为什么要缓存 缓存的请求与缓存 Metro配置 结构 前言 metro是一种支持ReactNa...
嵌入式Linux——应用调试:用户态打印段错误信息
简介: 很多时候我们会遇到段错误:segmentation fault,而段错误有时是由内核引起的,有时是由应用程序引起的。在内核态时,发生段错误时会打印oops信息,但是在用户态时,发生段错误却只会打印segmentation fault而并不会打印其他的信息。所以本文主要介绍在用户态时,通过修改内核设置和添加启动参数来打印引发segmentati...
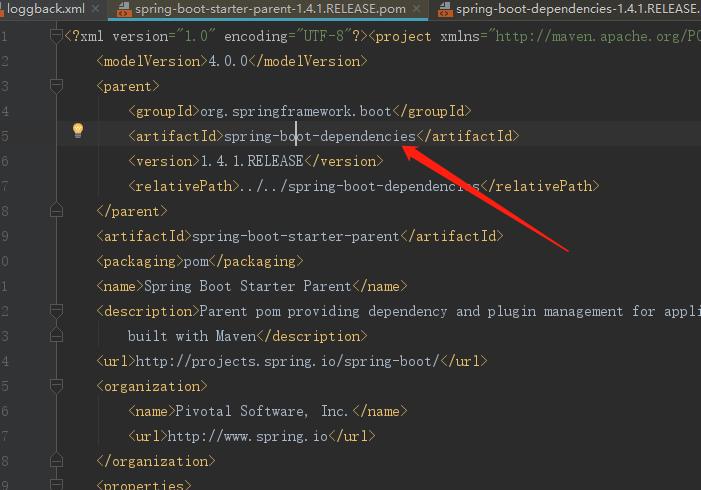
springboot1.4.1整合logback 遇到的问题
springboot1.4.1整合logback 遇到的问题 项目使用了springboot1.4.1整合logback,然而设置的过期时间15 并没有生效, 2GB达到2G自动删除也没有生效,仅仅实现了按大小分割。 经过查看pom 父工程内的源码发现是默认的logback版本是1.1.7,而过期时间配置是在logback 1.1.8以后才支持的。 不得不说这是springboot1.4.1 的b...
记一次C/S架构的渗透测试
概述 目标站点是http://www.example.com,官网提供了api使用文档,但是对其测试后没有发现漏洞,目录、端口扫描等都未发现可利用的点。后发现官网提供了客户端下载,遂对其进行一番测试。 信息收集 先抓了下客户端的包,使用Fiddler和BurpSuite都抓不到,怀疑走的不是HTTP协议,用WireShark查看其确实用的是HTTP协议,但是数据包不好重放,这里最后使用了WSExp...

Linux:结合Securecrt进行文件上传(lrzsz)P2
1、安装rzsz软件 2、点击Scurecrt的option——X/Y/Z配置上传和下载目录 3、首先在Linux里切换到一个目录,然后用rz命令,文件就会上传到钙Linux的目录下 只要敲rz即可,然后在弹出的对话框里选择需要上传的文件即可 4、下载文件用sz 下载单个文件:在当前目录下有该文件 sz filename 下载...
猜你喜欢

SQL 提示作为 布局 生存工具指南
下面是一些展示AdventureWorks中表现最好的销售人员并列出他们的经理的结构化查询语言代码。 它产生以下结果。 所以,代码是有效的,但它是丑陋的。 如果我需要理解和改进代码,我首先需要把它变成可读的形式。 我有结构化查询语言提示,所以我可以按下计算机的ctrl按键键 踢你自己),它会应用默认的内置代码样式,并对此进行修复。 不,不是,因为我相信你仍然不喜欢它的格式。 没有两个开发人员能够就...
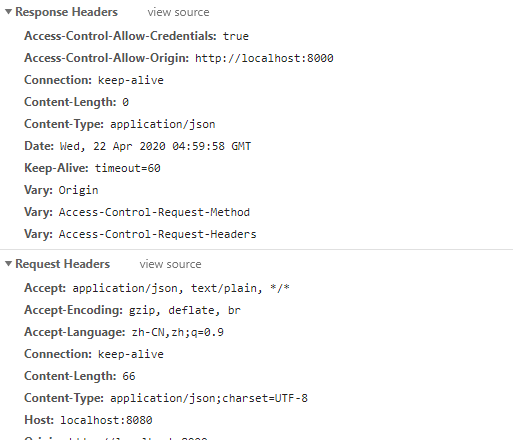
Vue+Springboot解决数据传输时参数格式不匹配问题
前端:使用的是ant design vue ,端口号为8000 后端:使用的是springboot框架开发,端口号为8080 需求:已经解决跨域问题,前端发送登录的信息给后台,后台接收不到 样例: 前端: 后台: 请求的数据格式为json格式,后台参数类型不匹配 解决方案 第一种: 修改后端,参数类型: 第二种方式: 在前端vue框架中加入qs插件,qs 是一个增加了一些安全性的查询字符串解析和序...
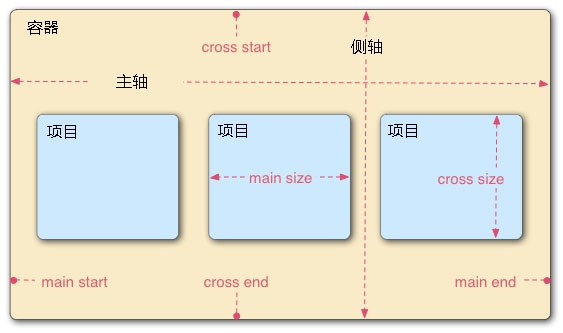
Flex布局做出自适应页面--语法和案例
本文发布在: github项目地址:https://github.com/tenadolanter/flex-layout-demo SegmentFault地址:https://segmentfault.com/a/1190000012916949/ CSDN地址:http://blog.csdn.net/qq_34648000/article/details/79115294 博客园地址:ht...
Java - 基于 Apache POI 创建 Excel 文件
基于 Apache POI 创建 Excel 文件 准备 新建 Maven Project,引入依赖: 创建行和列 设置列宽 设置列宽(第 19 行): 注意:其他行的首列的宽度是受第一行、第一列的影响而变宽,并非我们设置的。 设置字体颜色 设置字体颜色(第 25 ~ 31 行): 设置网页超链接 设置网页超链接(第 18、27 ~ 29 行): 参考 java操作excel常用的两种方式...
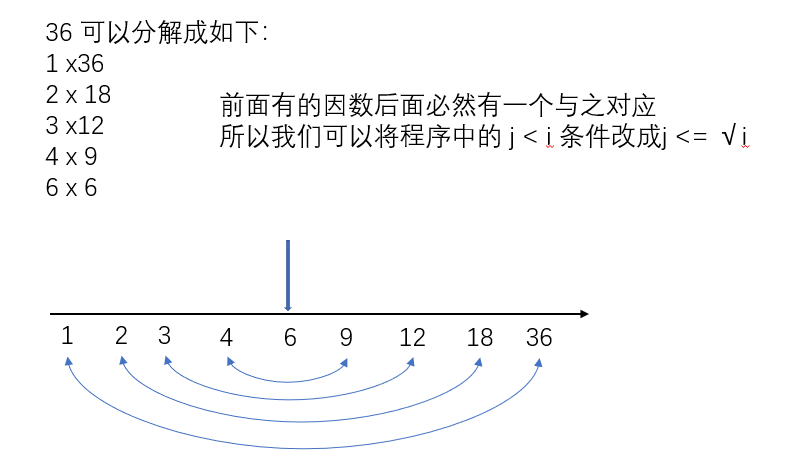
python基础-质数判断及优化
文章目录 一、问题描述 二、代码 三、问题2优化 四、数学补充 一、问题描述 质数判断条件: 质数是只能被1和它自身整除的数,1不是质数也不是合数。 二、代码 问题1代码 问题2代码 三、问题2优化 优化方案: 模块,通过模块可以对Python进行扩展 引入一个time模块,来统计程序执行的时间 time()函数可以用来获取当前的时间,返回的单位是秒 获取程序开始的时间,以运行时间来衡量优化结果。...