【Elasticsearch教程20】Pinyin拼音分词器 以及多音字修改
标签: Elasticsearch elasticsearch 大数据 拼音分词器 Pinyin
Elasticsearch Pinyin拼音分词器
1. 前言
在开发企业项目时,根据拼音搜索是很常见的场景,比如:
- 人员通讯录,不确定人名具体是哪个汉字,只知道读音,可以输入汉字+全拼音、汉字+拼音首字母、拼音首字母等
- 股票名称,炒股的人都知道,股票太多,记住所有股票code是不可能的,所以常用拼音首字母查股票。


Medcl大佬为我们提供了Pinyin分词器,可以让我们非常方便的使用拼音搜索文档。
2. pinyin分词器的多音字的错误修改
网上关于pinyin分词器的安装和使用的博客特别多,这里我就不赘述了。但是我得说一个非常重要的问题,目前我写博客时最新的版本8.x还是有这样的问题。虽然GitHub上,已经有人提出了这个Issue,但是目前还没有修复,所以我们就自己动手手动改改吧。
问题就是多音字“银行”的“行”,pinyin分词器会把“yin hang”错误的转成“yin xing”,当你测试“中国银行”时它是对的,但是“建设银行”时就又错了。不信的话你自己试试看。
这个时候需要修改下图中的jar包解压出来

然后修改如下图中文件polyphone.txt,注意千万不要一下子把"yin xing"替换成"yin hang"。
因为“隐形”、“银杏”这些词的拼音就是"yin xing"。这个你需要手动一个一个看好了改,我不确定这个问题是nlp-lang的问题还是pinyin分词器作者改的问题,我看nlp-lang1.7的源代码这个文件里“银行”确实是对的"yin hang"。
改好后,再重新打成nlp-lang-1.7.jar包,替换上图的那个nlp-lang-1.7.jar文件,然后重启ES就行啦。

3. 案例
Pinyin分词器的配置参数还是比较多的,可以参考它GitHub的说明,
这些配置一定要认真配,不同的配置,出来的搜索效果是不同的。
3.1 创建Mapping
- 我把拼音分词器作用在
name.pinyin这个子字段上,因为name这个主字段按照"standard"分词有用; - 我这么设计适合人名搜索、股票名称搜索这些值比较短的场景;
- 如果是文章内容,留言评论这些内容长的,一般按照IK分词就行,如果非要支持拼音搜索,可以把IK+Pinyin组合起来,设置tokenizer为ik_smart,filter为pinyin;
PUT pigg_test_pinyin
{
"settings":{
"analysis":{
"analyzer":{
"pinyin_analyzer":{
"tokenizer":"my_pinyin"
}
},
"tokenizer":{
"my_pinyin":{
"type":"pinyin",
"keep_first_letter":true,
"keep_separate_first_letter":true,
"keep_full_pinyin":true,
"remove_duplicated_term":true
}
}
}
},
"mappings":{
"properties":{
"name":{
"type":"text",
"analyzer":"standard",
"fields":{
"pinyin":{
"type":"text",
"analyzer":"pinyin_analyzer"
}
}
}
}
}
}
3.2 插入测试文档
PUT pigg_test_pinyin/_doc/1
{
"name": "亚瑟王"
}
PUT pigg_test_pinyin/_doc/2
{
"name": "鼓励王"
}
3.3 测试拼音搜索
按照中文:
GET pigg_test_pinyin/_search
{
"query": {
"match": {
"name.pinyin": {
"query": "瑟王",
"operator": "and"
}
}
}
}
按照中文+拼音全拼:
GET pigg_test_pinyin/_search
{
"query": {
"match": {
"name.pinyin": {
"query": "亚sewang",
"operator": "and"
}
}
}
}
按照中文+拼音首字母:
GET pigg_test_pinyin/_search
{
"query": {
"match": {
"name.pinyin": {
"query": "亚sw",
"operator": "and"
}
}
}
}
按照拼音首字母:
GET pigg_test_pinyin/_search
{
"query": {
"match": {
"name.pinyin": {
"query": "ysw",
"operator": "and"
}
}
}
}
3.4 查看拼音分词后结果
第1种方法:
GET pigg_test_pinyin/_doc/1/_termvectors?fields=name.pinyin
第2种方法:
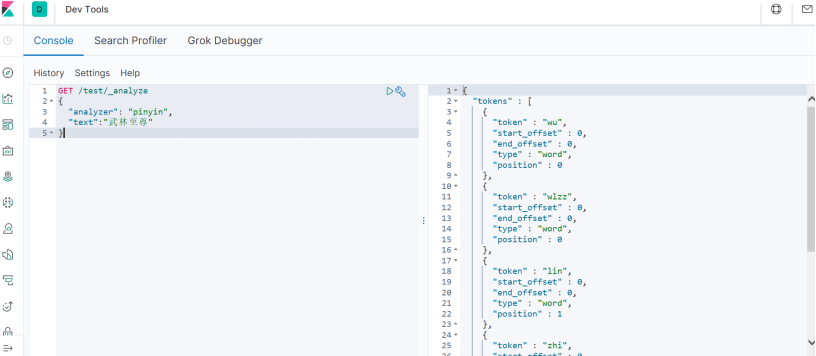
GET pigg_test_pinyin/_analyze
{
"analyzer" : "pinyin_analyzer",
"text" : "亚瑟王"
}
通过上面2种方法,都可以发现分词结果如下:
y, s, w, ysw, ya, se, wang
这是因为我设置了"keep_separate_first_letter":true,这样拼音的首字母ysw会再次拆分成y, s, w。
这样我们搜索"亚sw"时,就能匹配到文档了。
4. 结语
作为大龄程序员,30多岁了,不需要涉及太多技术,得潜心专研一两个技术,并戒掉浮躁,在项目实践中打磨自己。
所以光看文档、博客是没有用的,只有动手实践去解决业务问题,才会有更好的成长。
智能推荐
elasticsearch 拼音分词(elasticsearch-analysis-pinyin)
elasticsearch 拼音分词(elasticsearch-analysis-pinyin) 官网:https://github.com/medcl/elasticsearch-analysis-pinyin ***************************** 安装pinyin分词 进入容器,在线安装 查看分词插件 ...

【ES】ES 拼音 Pinyin 分词器
1.概述 转载:https://www.cnblogs.com/sanduzxcvbnm/p/12083606.html Elastic的Medcl提供了一种搜索Pinyin搜索的方法。拼音搜索在很多的应用场景中都有被用到。比如在百度搜索中,我们使用拼音就可以出现汉字: 对于我们中国人来说,拼音搜索也是非常直接的。那么在Elasticsearch中我们该如何使用pinyin来进行搜索呢?答案是我们...
Elasticsearch配置拼音分词和自定义分词器
下载elasticsearch-analysis-pinyin拼音分词器 https://codeload.github.com/medcl/elasticsearch-analysis-pinyin/zip/v6.4.3 解压 因为elasticsearch拼音插件和你的elasticsearch版本必须一致,如果不一致,可以修改pom.xml的版本为你的e...

linux上安装Qt4.8.6+QtCreator4.0.3
一、Qt简介 Qt是1991年奇趣科技开发的一个跨平台的C++图形用户界面应用程序框架。它提供给应用程序开发者建立艺术级的图形用户界面所需的所有功能。Qt很容易扩展,并且允许真正地组件编程。 准备工作 操作系统:centos6.5 位数:64位 二、安装 1、获取源码Qt4.8.6 2、获取源码QtCreator4.0.3 2、安装QtCreator4.0.3 进入QtCreator安装界面,指定...
react-native metro 分析
文章目录 前言 概念 Resolution Transformation Serialization 打包方式 Moudles Plain bundle Indexed RAM bundle File RAM bundle 流程 前置流程 resolve流程 Transformer流程 序列化流程 缓存 为什么要缓存 缓存的请求与缓存 Metro配置 结构 前言 metro是一种支持ReactNa...
猜你喜欢
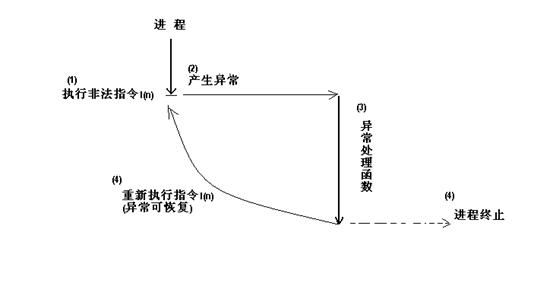
嵌入式Linux——应用调试:用户态打印段错误信息
简介: 很多时候我们会遇到段错误:segmentation fault,而段错误有时是由内核引起的,有时是由应用程序引起的。在内核态时,发生段错误时会打印oops信息,但是在用户态时,发生段错误却只会打印segmentation fault而并不会打印其他的信息。所以本文主要介绍在用户态时,通过修改内核设置和添加启动参数来打印引发segmentati...
springboot1.4.1整合logback 遇到的问题
springboot1.4.1整合logback 遇到的问题 项目使用了springboot1.4.1整合logback,然而设置的过期时间15 并没有生效, 2GB达到2G自动删除也没有生效,仅仅实现了按大小分割。 经过查看pom 父工程内的源码发现是默认的logback版本是1.1.7,而过期时间配置是在logback 1.1.8以后才支持的。 不得不说这是springboot1.4.1 的b...
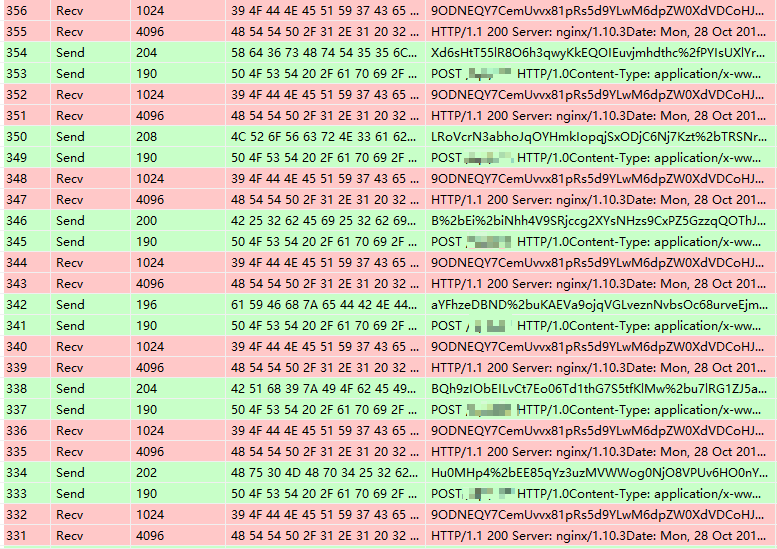
记一次C/S架构的渗透测试
概述 目标站点是http://www.example.com,官网提供了api使用文档,但是对其测试后没有发现漏洞,目录、端口扫描等都未发现可利用的点。后发现官网提供了客户端下载,遂对其进行一番测试。 信息收集 先抓了下客户端的包,使用Fiddler和BurpSuite都抓不到,怀疑走的不是HTTP协议,用WireShark查看其确实用的是HTTP协议,但是数据包不好重放,这里最后使用了WSExp...

Linux:结合Securecrt进行文件上传(lrzsz)P2
1、安装rzsz软件 2、点击Scurecrt的option——X/Y/Z配置上传和下载目录 3、首先在Linux里切换到一个目录,然后用rz命令,文件就会上传到钙Linux的目录下 只要敲rz即可,然后在弹出的对话框里选择需要上传的文件即可 4、下载文件用sz 下载单个文件:在当前目录下有该文件 sz filename 下载...

SQL 提示作为 布局 生存工具指南
下面是一些展示AdventureWorks中表现最好的销售人员并列出他们的经理的结构化查询语言代码。 它产生以下结果。 所以,代码是有效的,但它是丑陋的。 如果我需要理解和改进代码,我首先需要把它变成可读的形式。 我有结构化查询语言提示,所以我可以按下计算机的ctrl按键键 踢你自己),它会应用默认的内置代码样式,并对此进行修复。 不,不是,因为我相信你仍然不喜欢它的格式。 没有两个开发人员能够就...