基于字典学习的图像去噪研究与实践
机器学习在图像处理中有非常多的应用,运用机器学习(包括现在非常流行的深度学习)技术,很多传统的图像处理问题都会取得相当不错的效果。今天我们就以机器学习中的字典学习(Dictionary Learning)为例,来展示其在图像去噪方面的应用。文中代码采用Python写成,其中使用了Scikit-learn包中提供的API,读者可以从【2】中获得演示用的完整代码(Jupyter notebook)。
一、什么是字典学习?
字典学习 (aka Sparse dictionary learning) is a branch of signal processing and machine learning. 特别地,我们也称其为a representation learning method. 字典学习 aims at finding a sparse representation of the input data (also known as sparse coding or 字典) in the form of a linear combination of basic elements as well as those basic elements themselves。These elements are called atoms and they compose a dictionary。字典中,some training data admits a sparse representation。The sparser the representation, the better the dictionary。如下图所示,现在我们有一组自然图像,我们希望学到一个字典,从而原图中的每一个小块都可以表示成字典中少数几个atoms之线性组合的形式。

二、字典学习应用于图像去噪的原理
首先来看看图像去噪问题的基本模型,如下图所示,对于一幅噪声图像y,它应该等于原图像x 假设噪声w,而在这个关系中,只有y是已知的,去噪的过程就是在此情况下推测x的过程。

在此基础上,我们通常把去噪问题看成是一个带约束条件的能量最小化问题,即对下面这个公式进行最下好从而求出未知项x。最小化公式中的第一项表示x和y要尽量接近,否则本来一幅猫噪声的图像,降噪之后变成了狗,这样的结果显然不是我们所期望的。第二项则表示对x的一个约束条件,否则如果没有这一项,那么x就变成了噪声图像y,那去噪也就失去了意义。这又变成了一个最大后验估计(Maximum-a-Posteriori (MAP) Estimation) 问题,关于MAP的概念你可以参考【3】。

关于第二项到底应该符合什么标准,不同学者都提出了各自的观点。其中一派就认为,x应该满足“稀疏”这个条件,因为这也是自然图像中所普遍存在的一个现实。
如果所x是一个m维的信号,D=[d1,..., dn]是一组标准基向量(basis vectors),其大小为m×p,也就是我们所说的字典。D is "adapted" to y if it can represent it with a few basis vectors, that is, there exists a sparse vector a,这里a是一个p维向量,such that y≈Da。这里a 就是所谓的稀疏编码。

为什稀疏对于去噪是好的?显然,a dictionary can be good for representing a class of signals, but not for representing white Gaussian noise。直觉上,也即是说,用字典来近似表达y的时候,就会略掉噪声。
于是乎,Elad and Aharon在2006年便提出了用字典学习来进行去噪的技术方案。首先,我们从y中提取所有的overlapping的矩形窗口(例如8×8),然后求解如下矩阵分解(matrix factorization)问题

基于这一基本原理,字典学习还可以应用于图像的inpaint(也就是图像修复),例如下面是修复前和修复后的图像对比

再来看看局部效果,可见毫无违和感

三、Scikit-learn实现的基于字典学习的图像去噪实例
首先引入所需的各种包,并读入一张Lena图像。
print(__doc__)
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
import scipy as sp
from sklearn.decomposition import MiniBatchDictionaryLearning
from sklearn.feature_extraction.image import extract_patches_2d
from sklearn.feature_extraction.image import reconstruct_from_patches_2d
%matplotlib inline
from keras.preprocessing.image import load_img
# load an image from file
image = load_img('lena_gray_256.tif')
from keras.preprocessing.image import img_to_array
# convert the image pixels to a numpy array
image = img_to_array(image)
image = image[:,:,0]
print("original shape", image.shape)image = image.astype('float32')
image/=255
plt.imshow(image, cmap='gray')然后是向其中加入高斯噪声,我们把含噪声的图像放在本文最后以便直观地对比去噪效果。
noise = np.random.normal(loc=0, scale=0.05, size=image.shape)
x_test_noisy1 = image + noise
x_test_noisy1 = np.clip(x_test_noisy1, 0., 1.)
plt.imshow(x_test_noisy1, cmap='Greys_r')# Extract all reference patches from the original image
print('Extracting reference patches...')
patch_size = (5, 5)
data = extract_patches_2d(image, patch_size)
print(data.shape)这里data的shape是一个三维向量[x, y, z],x表示patches的数量,y和z是每个小patch的宽和高。但在进行运算时,我们需要把每个小矩形“拉直”,于是有
data = data.reshape(data.shape[0], -1)
print(data.shape)
data -= np.mean(data, axis=0)
data /= np.std(data, axis=0)# #############################################################################
# Learn the dictionary from reference patches
print('Learning the dictionary...')
dico = MiniBatchDictionaryLearning(n_components=144, alpha=1, n_iter=500)
V = dico.fit(data).components_你也可以查看一下字典V的形状,或者把它显示出来看看具体内容。这里我们设计的字典中一共有144个atoms,所以分12排来打印,每排12个atoms。
print(V.shape)
plt.figure(figsize=(4.2, 4))
for i, comp in enumerate(V[:144]):
plt.subplot(12, 12, i + 1)
plt.imshow(comp.reshape(patch_size), cmap=plt.cm.gray_r,
interpolation='nearest')
plt.xticks(())
plt.yticks(())
plt.suptitle('Dictionary learned from patches\n', fontsize=16)
plt.subplots_adjust(0.08, 0.02, 0.92, 0.85, 0.08, 0.23)字典如下图所示。

接下来要做的是从噪声图像中提取同样大小的patches,然后从字典中找到一组最逼近这个小patch的一组原子的线性组合,并用这个组合来重构噪声图像中的小patch。
# #############################################################################
# Extract noisy patches and reconstruct them using the dictionary
print('Extracting noisy patches... ')
data = extract_patches_2d(x_test_noisy1, patch_size)
data = data.reshape(data.shape[0], -1)
intercept = np.mean(data, axis=0)
data -= intercept这里所使用的算法是OMP。函数recontruct_from_patches_2d用于重构图像。方法transform的作用是Encode the data as a sparse combination of the dictionary atoms
print('Orthogonal Matching Pursuit\n2 atoms' + '...')
reconstructions = x_test_noisy1.copy()
dico.set_params(transform_algorithm='omp', **{'transform_n_nonzero_coefs': 2})
code = dico.transform(data)
patches = np.dot(code, V)
patches += intercept
patches = patches.reshape(len(data), *patch_size)
reconstructions = reconstruct_from_patches_2d(patches, (256, 256))
plt.imshow(reconstructions, cmap='Greys_r')去噪后的图像由文末对比结果中的左下角图像给出。
四、从噪声图像中学习字典
现实中,噪声图像的原图像是无法获取的,否则就不需要去噪了。但我们可以直接从噪声图中学习字典。于是修改之前的代码,我们从直接从噪声图像中获取用于字典学习的patches。
# Extract all reference patches from noisy image
print('Extracting reference patches...')
patch_size = (5, 5)
data = extract_patches_2d(x_test_noisy1, patch_size)
print(data.shape)data = data.reshape(data.shape[0], -1)
print(data.shape)
data -= np.mean(data, axis=0)
data /= np.std(data, axis=0)# #############################################################################
# Learn the dictionary from reference patches
print('Learning the dictionary...')
dico = MiniBatchDictionaryLearning(n_components=144, alpha=1, n_iter=500)
V = dico.fit(data).components_
print(V.shape)
plt.figure(figsize=(4.2, 4))
for i, comp in enumerate(V[:144]):
plt.subplot(12, 12, i + 1)
plt.imshow(comp.reshape(patch_size), cmap=plt.cm.gray_r,
interpolation='nearest')
plt.xticks(())
plt.yticks(())
plt.suptitle('Dictionary learned from patches\n', fontsize=16)
plt.subplots_adjust(0.08, 0.02, 0.92, 0.85, 0.08, 0.23)下图便是我们从噪声图像中学习到的字典。

再次使用之前的代码。其中,set_params的作用是Set the parameters of this estimator。其中,transform_n_nonzero_coefs 是 Number of nonzero coefficients to target in each column of the solution. 也就是稀疏解的稀疏程度。默认情况下,它等于 0.1 * n_features(features的数量)。该参数 is only used by algorithm=’lars’ and algorithm=’omp’ and is overridden by alpha in the omp case。
# #############################################################################
# Extract noisy patches and reconstruct them using the dictionary
print('Extracting noisy patches... ')
data = extract_patches_2d(x_test_noisy1, patch_size)
data = data.reshape(data.shape[0], -1)
intercept = np.mean(data, axis=0)
data -= intercept
print('Orthogonal Matching Pursuit\n2 atoms' + '...')
reconstructions_frm_noise = x_test_noisy1.copy()
dico.set_params(transform_algorithm='omp', **{'transform_n_nonzero_coefs': 2})
code = dico.transform(data)
patches = np.dot(code, V)
patches += intercept
patches = patches.reshape(len(data), *patch_size)
reconstructions_frm_noise = reconstruct_from_patches_2d(patches, (256, 256))
plt.imshow(reconstructions_frm_noise, cmap='Greys_r')
imgs = (reconstructions_frm_noise * 255).astype(np.uint8)
Image.fromarray(imgs).save('lena_denoise_from_noise.png')读者还可以参考Scikit-learn官方文档中给出的例子【1】,以了解其他参数或算法的使用。
参考文献
【1】文中程序取材自Scikit-learn提供的示例,笔者有修改
【2】代码下载链接
【3】资料链接
智能推荐

arp协议
arp协议叫做地址解析协议,通常与ip地址共同使用,将ip地址转换成硬件地址(MAC地址)。arp既可以放在网络层,也可以放在数据链路层,因为它做了两层的工作。 当一个主机向另一个主机发送数据报时,通过arp协议,向局域网中发送arp请求,所有在局域网中的主机都可以收到,但会在网络层丢弃,只有一台符合目的ip的主机会发送给源主机arp响应包含自己mac地址,因此源主机就可以向目的主机发送报文。 l...

模拟登陆改版后的知乎(最新版)
今天,想着看看视频,把模拟登陆这一块学习学习,以后弄把梯子,去爬爬FaceBook什么的。就拿知乎练练手吧,可曾想,知乎竟然改版了!!之前的教程书籍对现在的知乎来说,都是扯淡,连页面都找不到了。下面一起谈谈改版后的纸糊的模拟登陆吧。 页面分析 抓包 首先,打开页面:https://www.zhihu.com/signup?next=%2F(登录网址都变了…),F12,输入账号密码(记...

干货分享——比微信域名防封防举报更牛逼的防封方案
从微信兴起到现在,微信的流量就一直居高不下,在淘宝时代和传统的电商时代,只要把广告打出去,别人通过搜索就可以找到我们,所以,移动互联网的到来,在微信爆棚的今天,都想在微信里面推广自己的产品,借力微信,达到客户沉淀,营销宣传,传播影响的目的,可以由于微信种种机制,有人腾讯要维护自身的利益,也有人说是微信要营造一个健康的生态圈,种种限制,比如分享次数过多,域名会被微信拦截屏蔽封杀,还比如微信中的链接不...
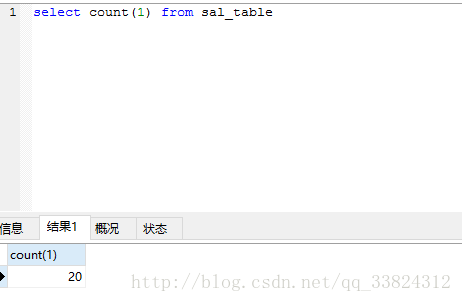
mysql的事务提交(java)
个人理解的一个事务:是一个Connection一系列的操作过程,如果是两个Connection连接在操作,那就是两个事务。 事务的前提:数据库的存储引擎是innodb。 事务的目的:保证数据的安全性。 事务安全: 1.自动提交事务:每执行一条sql语句,就同步到数据库中。 2.手动提交事务:执行一系列的sql语句后一起同步到数据库中。 事务的四大特性: A(at...
猜你喜欢
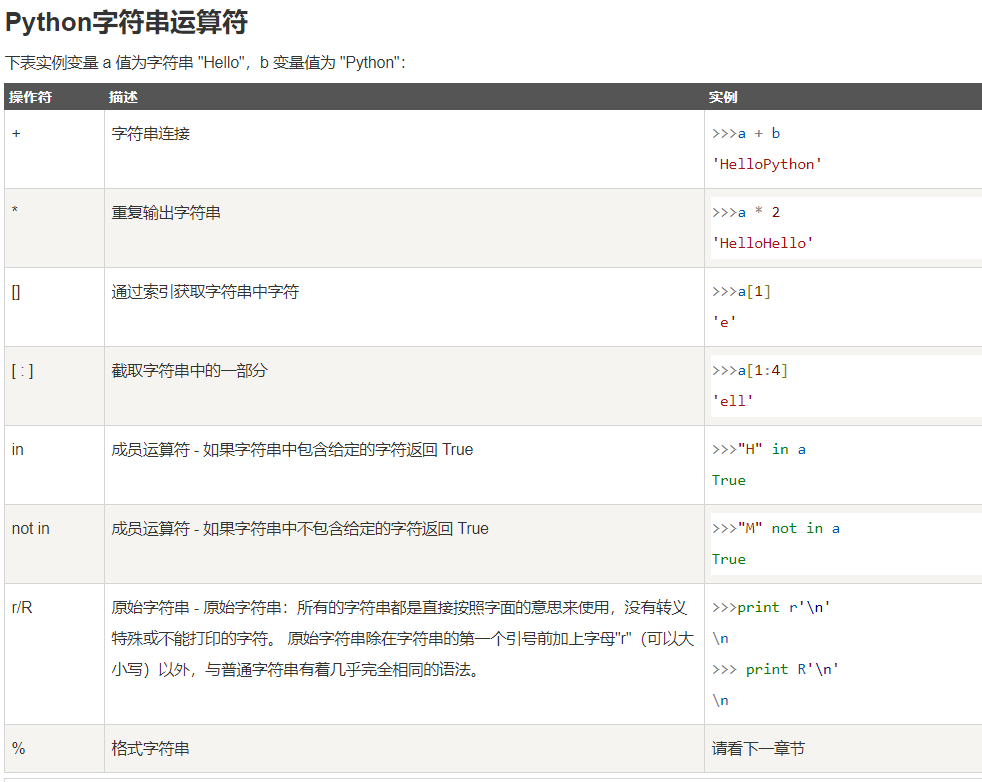
Python基础(二)
一、Python语言基础要素 2.字符串 处理字符串的一个常用标准库块是string。在string模块中,你可以使用多个函数来有效管理字符串,下面的示例说明了使用这些字符串函数的方法。 1.split split()是通过指定分隔符对字符串进行切片,如果参数num有指定值,则分隔num+1个子字符串。 基本语法:str.split(str='',num=string.count(str)) st...

数据结构-二叉搜索树
**首先来了解一下树的一些术语: (图片来源:中国大学mooc —— 浙大数据结构) 二叉树定义: 1、每个结点最多有两颗子树,结点的度最大为2。 2、左子树和右子树是有顺序的,次序不能颠倒。 3、即使某结点只有一个子树,也要区分左右子树。 二叉树的几种状态: 特殊二叉树: 下面放一张错误的完全二叉树 一些公式做笔试题用的: 二叉树介绍完了,下面介绍一下二叉搜索树,此案例代...

Qt开发记录10——功能开发——快捷键设置
目录 实现效果 编码 自定义弹窗类ShortcutSetDialog 新建shortcutsetdialog.h文件,创建自定义实体类ShortcutSetDialog 新建shortcutsetdialog.cpp文件 新建shortcutsetdialog.ui文件,创建ui界面 打开窗体时,捕获键盘事件grabKeyboard() 捕获键盘按下事件keyPressEvent 关闭窗体时,释放...
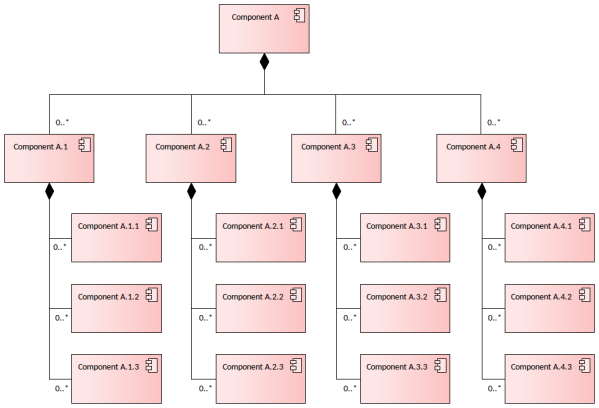
GA001-181-08
Two Level Component Composition Hierarchy 角色名称和多重性描述了每个组件在层次结构中所扮演的角色以及每个组件的允许实例的数量。 图1.显示了一个类图,其中包含组件的层次结构。 角色名称和多重性修饰在关联的结束部分 Discussion 该模式的目的是允许工程师、架构师和实现分析人员对组件及其组成部分进行建模。由此产生的层次结构允许他们观察系统的逻辑部分的结...

WebStorm + BootStrap 安装 用 Tomcat 部署Web项目(图文详解 + 实例 )
WebStorm安装和** 1.官网下载 2.安装 ,安装地址看个人情况修改 . 32位 这里选择 32-bit launcher &nbs...