docker+rabbitmq+HAproxy 部署 镜像模式 的集群
标签: rabbitmq rabbitmq集群 镜像集群 docker HAproxy
为了解决上篇文章中 的 docker+rabbitmq 部署 普通模式 的集群 问题,此次通过 docker+rabbitmq+HAproxy部署 镜像模式的集群;
镜像模式介绍
镜像模式 实现了 队列的高可用, 因为 客户端生产的 队列任务数据 会 立刻主动的 复制到 集群中的所有节点上;这样 保证 任何一个节点宕机后,其他节点保证在不丢失数据的情况下 继续提供服务;从而实现高可用;(在默认集群模式基础上 增加了 同步队列数据的功能)
节点间同步数据机制: 不必担心同步数据丢失问题,因为 主节点接收数据后 会立刻同步到每个可用节点中,只有所有节点都同步成功 才 返回给客户端 表示 上传消息成功的 通知;不会出现mysql主从 异步或同步 数据丢失的问题;
HAproxy介绍
HAproxy:是一款提供高可用性、负载均衡以及基于TCP和HTTP应用的代理软件, HAproxy是完全免费的、借助 HAproxy可以快速并且可靠的提供基于TCP和HTTP应用的代理解决方案,HAproxy适用于那些负载较大的web站点,这些站点通常又需要会话保持或七层处理。HAproxy可以支持数以万计的并发连接,并且 HAproxy的运行模式使得它可以很简单安全的整合进架构中,同时可以保护web服务器不被暴露到网络上;实现了负载均衡 和反向代理;
和其他web服务器的比较
相同点:在功能上,HAproxy通过反向代理方式实现 WEB均衡负载。和 Nginx,ApacheProxy,lighttpd,Cheroke 等一样。
不同点:Haproxy 并不是 web 服务器。以上提到所有带反向代理均衡负载的产品,都清一色是 WEB 服务器。简单说,就是他们能处理解析页面的。而Haproxy 仅仅是一款的用于均衡负载的应用代理。其自身并不能提供web服务。但其配置简单,拥有非常不错的服务器健康检查功能还有专门的系统状态监控页面,当其代理的后端服务器出现故障, HAProxy会自动将该服务器摘除,故障恢复后再自动将该服务器加入。
rabbitmq集群 为何引入 HAproxy?
在 客户 连接 rabbitmq集群时,如果没有 HAproxy,则 客户端 必须连接每个节点,保证 每个节点 负载尽量相同,并且在 某个节点宕机时 对应连接的 客户端 还要手动的 修改连接的 节点, 因为这些缺点 导致 必须因为 HAproxy;
docker+rabbitmq部署 镜像集群步骤
部署架构图:
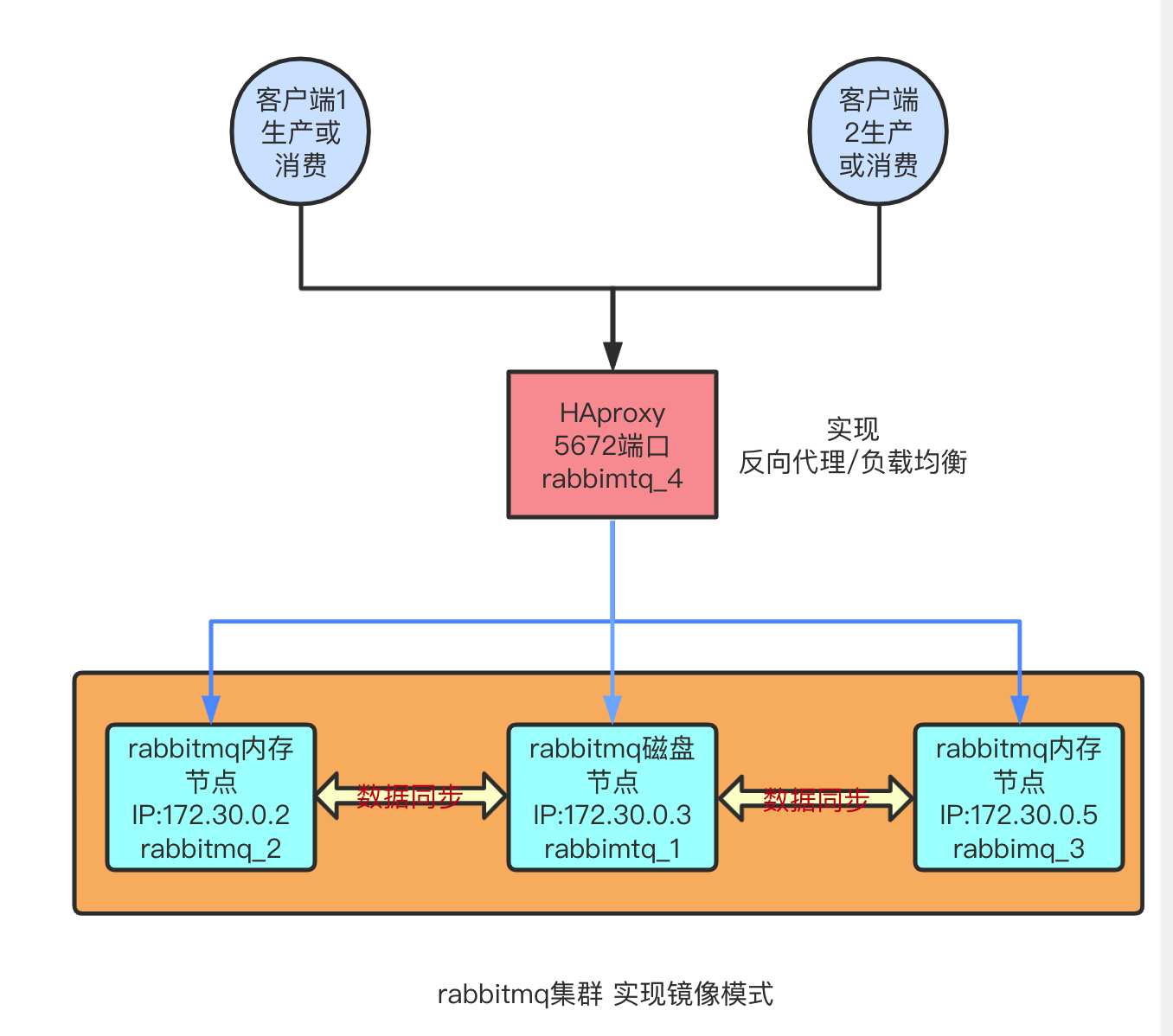
节点信息(部署 时 会用到):
内网IP hostname 容器ID web端口 节点类型
172.30.0.3 6e3c19a1cd23 rabbit_1 15673 disk(磁盘) 此节点为 主节点
172.30.0.2 cb959d1f3550 rabbit_2 15674 ram(内存)
172.30.0.5 16e7cb4bcfff rabbit_3 15675 ram(内存)由于 镜像模式+ HAproxy 部署 是在 默认集群模式基础上 添加的功能,因此 要先 实现 默认集群镜像模式的部署,请点击链接
1.设置镜像策略
在任何一个集群节点(rabbitmq_1,rabbitmq_2,rabbitmq_3)上执行如下命令:
rabbitmqctl set_policy -p / ha-all "^" '{"ha-mode":"all"}' # 给 vhost 为/ 策略名为 ha_all 的所有节点 进行镜像复制然后 打开集群节点 的 某个 WEB 界面 查看队列页面如下:
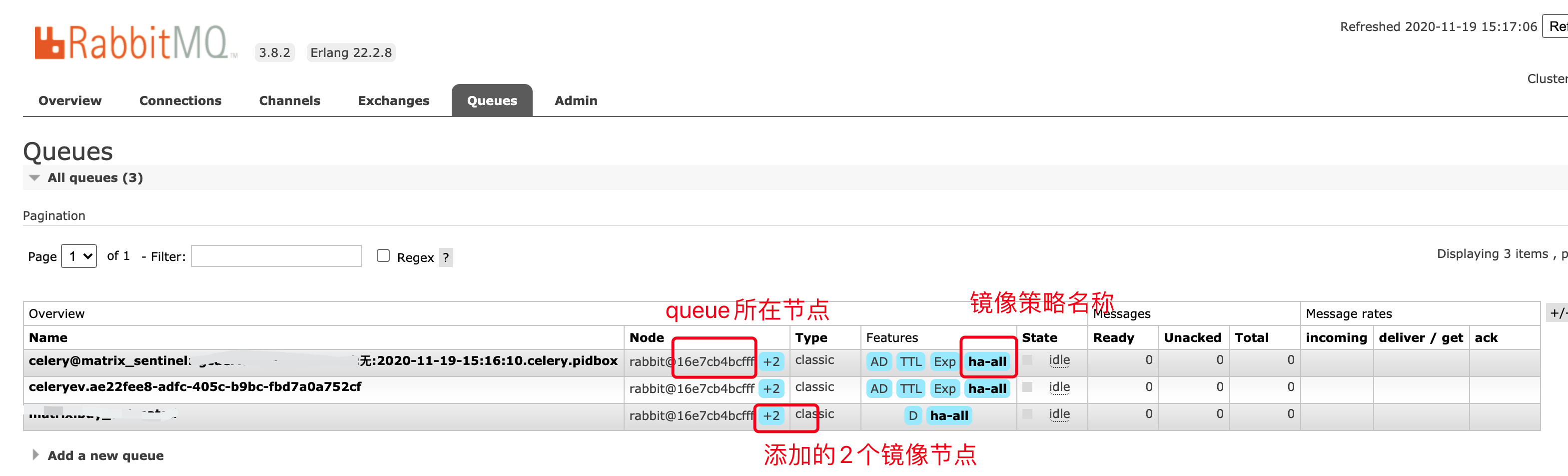
结论: 说明 持久化 和 节点存储类型无关,所以不存在 内存节点 比磁盘节点 存取数据 效率更高的情况;
2.设置 HAproxy
在 rabbitmq_4节点上 设置HAproxy
进入容器 输入如下命令
docker exec -it rabbitmq_1 /bin/bash停止 rabbitmq服务(此节点 只 做 HAproxy)
rabbitmqctl stop进入到 /etc/haproxy目录
编写 haproxy.cfg文件
global
log /dev/log local0
log /dev/log local1 notice
chroot /var/lib/haproxy
stats socket /run/haproxy/admin.sock mode 660 level admin expose-fd listeners
stats timeout 30s
user haproxy
group haproxy
daemon
# Default SSL material locations
ca-base /etc/ssl/certs
crt-base /etc/ssl/private
# Default ciphers to use on SSL-enabled listening sockets.
# For more information, see ciphers(1SSL). This list is from:
# https://hynek.me/articles/hardening-your-web-servers-ssl-ciphers/
# An alternative list with additional directives can be obtained from
# https://mozilla.github.io/server-side-tls/ssl-config-generator/?server=haproxy
ssl-default-bind-ciphers ECDH+AESGCM:DH+AESGCM:ECDH+AES256:DH+AES256:ECDH+AES128:DH+AES:RSA+AESGCM:RSA+AES:!aNULL:!MD5:!DSS
ssl-default-bind-options no-sslv3
defaults
log global
mode http
option tcplog
option dontlognull
timeout connect 5000
timeout client 50000
timeout server 50000
errorfile 400 /etc/haproxy/errors/400.http
errorfile 403 /etc/haproxy/errors/403.http
errorfile 408 /etc/haproxy/errors/408.http
errorfile 500 /etc/haproxy/errors/500.http
errorfile 502 /etc/haproxy/errors/502.http
errorfile 503 /etc/haproxy/errors/503.http
errorfile 504 /etc/haproxy/errors/504.http
# 对接 客户端
frontend Rabbitmq_frontend
# 客户端连接地址
bind 0.0.0.0:5672
# tcp连接
mode tcp
option clitcpka
timeout client 100m
maxconn 10000
# 对应 后端 集群
default_backend Rabbitmq_Backend
backend Rabbitmq_Backend
mode tcp
timeout queue 100m
timeout server 300m
option srvtcpka
option redispatch
fullconn 10000
# 负载均衡策略
balance roundrobin
option tcp-check
# 添加节点
# 主机hostname rabbitmq服务url 权重
server 6e3c19a1cd23 172.30.0.3:5672 weight 3 maxconn 1000 check port 5672 inter 5000 rise 2 fall 2
server cb959d1f3550 172.30.0.2:5672 weight 3 maxconn 1000 check port 5672 inter 5000 rise 2 fall 2
server 16e7cb4bcfff 172.30.0.5:5672 weight 3 maxconn 1000 check port 5672 inter 5000 rise 2 fall 2
listen stats
# web页面访问url
bind 0.0.0.0:8100
mode http
option httplog
stats enable
# 添加 的 路由 为 /rabbit 所有 访问 url为: http://0.0.0.0:8100/rabbit
stats uri /rabbit
# 5s刷新一下 数据
stats refresh 5s
# 登录认证 用户名:密码
stats auth root:root
# 启动命令为:haproxy -f ./haproxy.cfg然后执行如下 命令 生成 haproxy需要的文件夹
mkdir /run/haproxy然后运行 启动命令
mkdir /run/haproxy查看运行状况;如果有执行结果 表示 没问题,有 ALERT 可以忽略
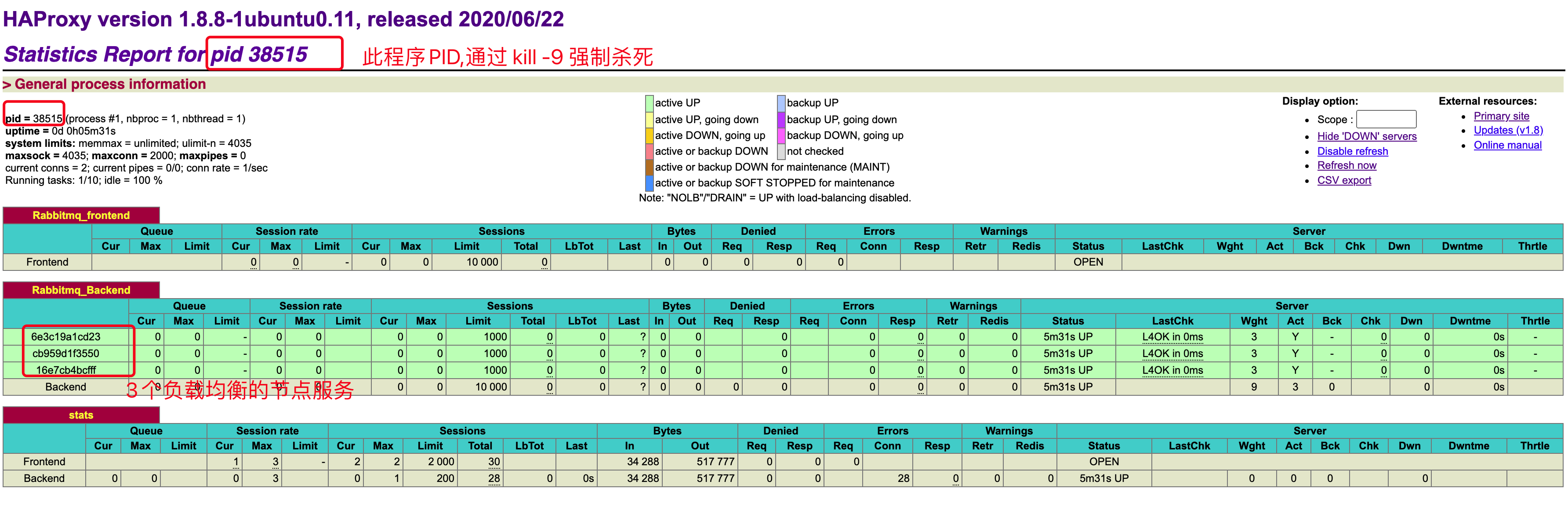
ps -ef | grep haproxyWEB页面查看效果图:
3.简单测试 此模式
ONE: 客户端代码 全部通过 5672端口访问 rabbitmq集群服务, 1个客户端生产者连接,3个客户端消费者连接,然后 生产者 发送一条消息, 查看消费者 是否 重复消费; 结论 没有重复消费
TWO: 上述操作后, 关闭 某节点服务,查看 3个消费者 连接是否 正常,以及HAproxy,Rabbitmq 的 web 界面是否出现对应 失效的节点; 结论:消费者会突然报错然后从新连接成功, web界面会出现对应失效节点信息;
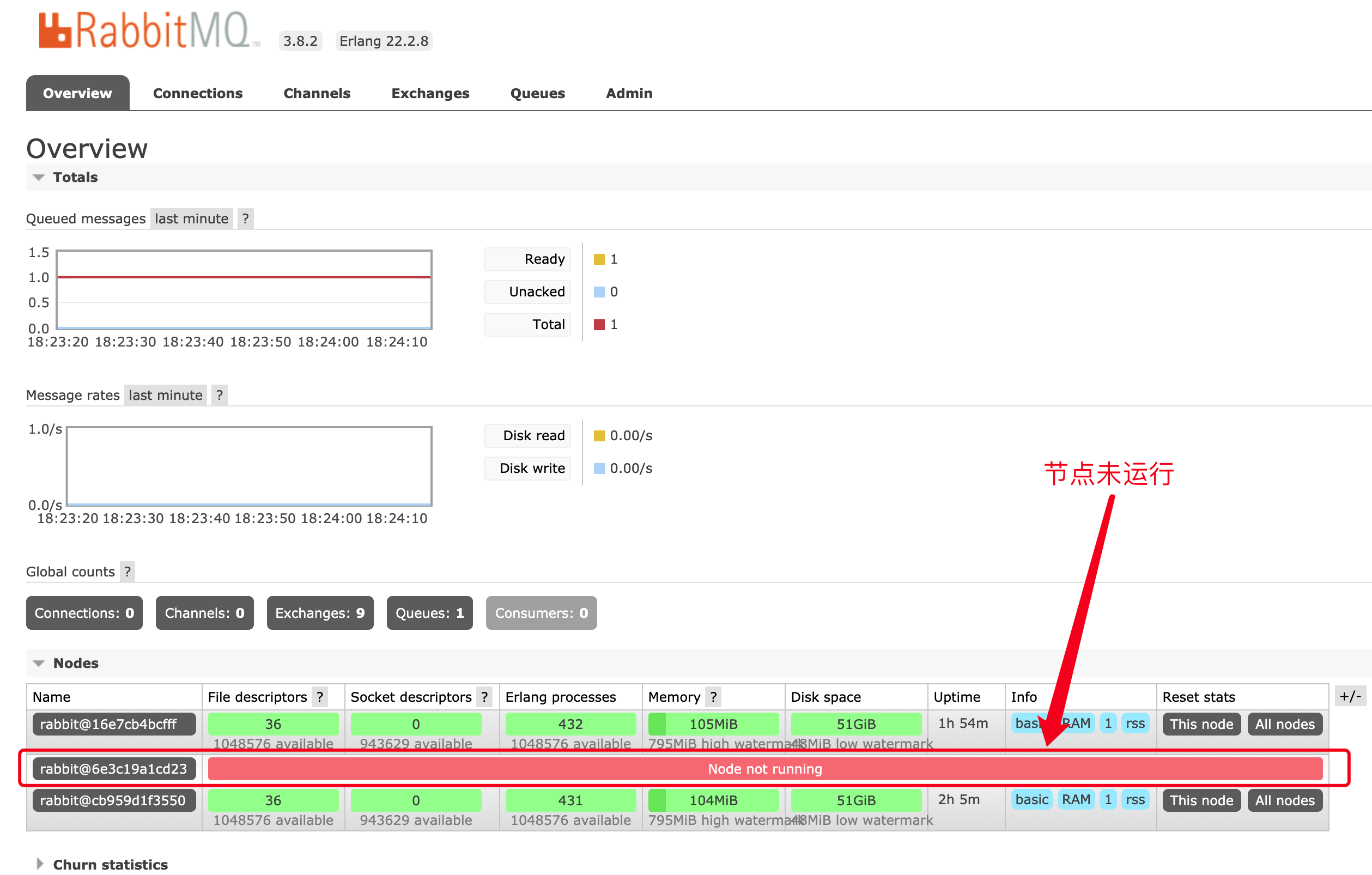
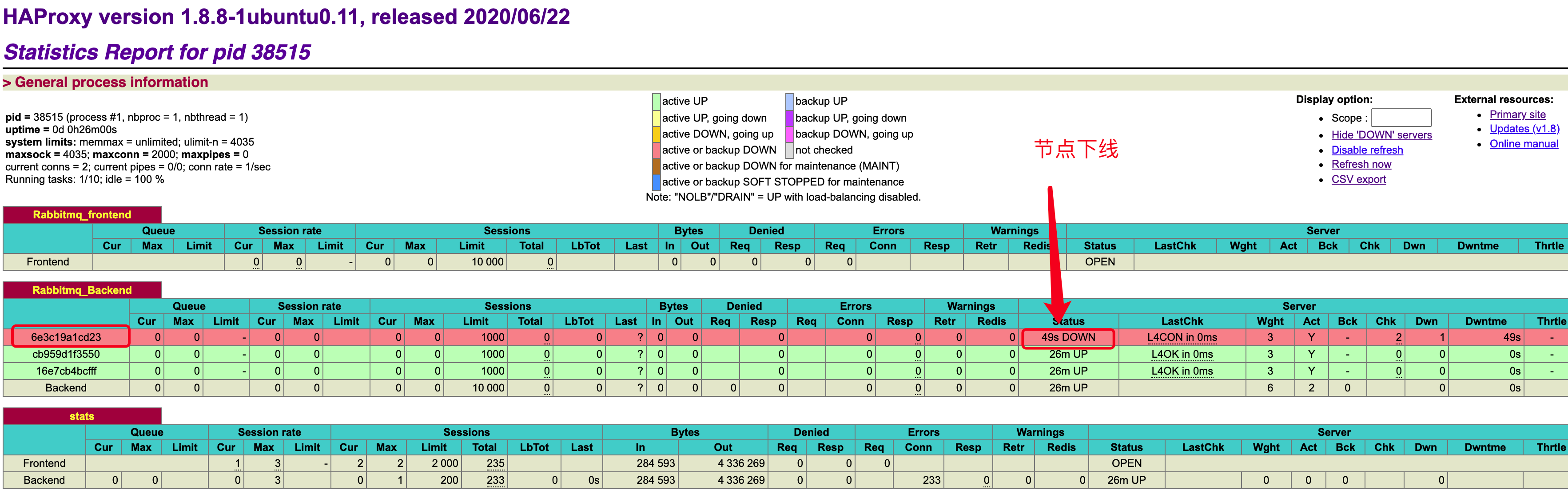
注意点:
主节点(被复制 .erlang.cookie文件) 宕机后 其他节点 照常提供服务(队列 如果在主节点,这时会 在其他节点新建);
在 所有节点 都宕机后 重启 每个节点的rabbitmq服务时,必须先启动 主节点(被复制 .erlang.cookie文件)的rabbitmq服务,在启动其他节点的rabbitmq服务,否则 会启动失败;
为了 更好的 应用 镜像模式 最好 理解一下 磁盘节点和内存节点的区别 , 然后得到如下 总结:
在 镜像模式中, 某些 非至关重要的 队列需求中,可以将 队列的 生产者 消费者 设置为 非持久化,再加上 好几个节点 进行容错, 在 只要不是狗屎运的情况下(所有节点都同时宕机),应该能 得到 很好的 消息存取速率,和保证消息不丢失(高可用);
相关连接:
https://www.rabbitmq.com/clustering.html
https://www.cnblogs.com/flat_peach/archive/2013/04/07/3004008.html#commentform
智能推荐

Spark的On Yarn集群模式部署及参数详解
Spark的On Yarn集群模式部署 官方文档 http://spark.apache.org/docs/latest/running-on-yarn.html 准备工作 安装启动Hadoop(需要使用HDFS和YARN) 安装单机版Spark 这里不需要启动集群,因为把Spark程序提交到YARN运行本质上就是把字节码给YARN集群上的JVM运行,但是有一个东西帮我们把任务提交上到YARN,所...
kubenetes集群模式部署minio
环境准备 一个部署完整的k8s集群,版本1.18.1 系统版本:CentOS7.2 docker版本:1.13.1 172.22.21.77 dev-learn-77 master 172.22.21.78 dev-learn-78 slave 172.22.21.79 dev-learn-79 slave 使用的是主机Host网络 存储使用本地文件系统 准备yaml文件 minio-distri...
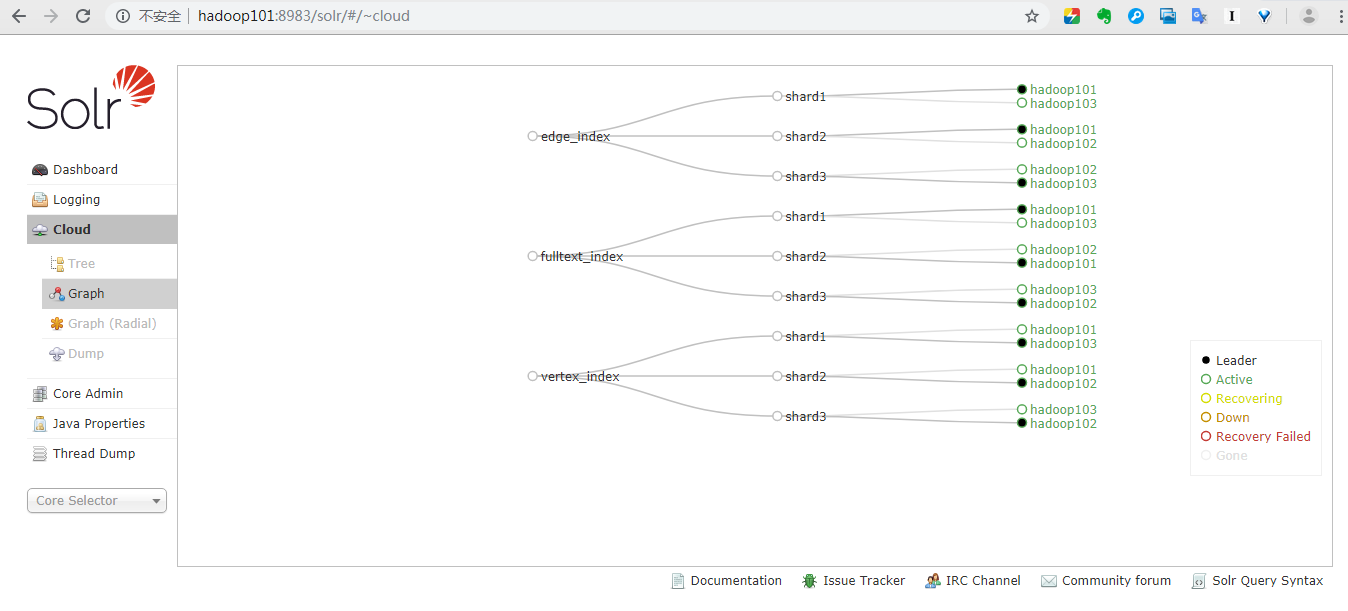
Atlas集群HA模式部署
Atlas 源码的编译此处省略,网上有很多资料。Atlas编译后会自动生成一系列安装包,选择apache-atlas-2.0.0-bin.tar.gz进行安装。注:编译源码包时,选择不包含自带的solr和hbase 本文按照生产模式进行安装,atlas HA, solr HA , hbase HA。 准备3台服务器,默认Hbase和zookeeper已经安装启动好 hadoop101 hadoop...

Mybatis基础(part 1)
一.mybatis调用SQL语句 1.使用XML配置SQL语句 在SqlMapConfig.xml配置数据源并指定映射配置文件的位置(每个DAO对应的XML文件,该文件映射了DAO的全限定类名) 2.使用注解配置sql语句 在SqlMapConfig.xml配置数据源和class属性(指定被注解的dao全限定类名),在DAO上写注解。 用注解来配置,故此处使用class属性指定被注解...

Docker 容器内运行 Dubbo 服务
原文:http://www.aqcoder.com/post/content?id=41 在使用 Docker 容器内运行 Dubbo 服务的时候一个令人很头痛的问题就是服务地址注册。 Docker 容器内有自己的 IP 段,和宿主主机是隔离的,Dubbo 会使用容器内的 IP 注册到 zookeeper 注册中心上。这样其他的服务是无法访问的。 方式一:–host 一个很直接的方案就...
猜你喜欢
python基础教程
Python基础教程 一、简介 1.1 python语言介绍 python的创始人:Guido Van Rossum Python下载地址:https://www.python.org/ Python文档下载地址:https://www.python.org/doc/ Pycharm下载地址:https://www.runoob.com/w3cnote/pycharm-windows-instal...
1、Git安装与配置
1、Git安装与配置 一:版本控制 定义:版本控制是一种记录一个或若干文件内容变化,以便将来查阅特定版本修订情况的系统。 为什么要用版本控制:在起初的项目开发中,我们会不断的编写代码,但是,害怕有一天系统突然挂掉了,完蛋,辛苦写的代码就这么没了,所有为了防止这一点,都会开发一点就以目录拷贝的形式保存下来,自己这么1.0、2.0、3.0…的这么去标记,开始的还好,后面的话你压根就不知道...

Golang net/rpc 包的深度解读和学习
Golang 提供了一个开箱即用的RPC服务,实现方式简约而不简单。本文对net/rpc 包做深度解读和学习实战。 RPC 简单介绍 远程过程调用 (Remote Procedure Call,RPC) 是一种计算机通信协议。允许运行在一台计算机的程序调用另一个地址空间的子程序(一般是开放网络中的一台计算机),而程序员就像调用调用本地程序一样,无需额外做交互编程。RPC 是一种 CS (Clien...
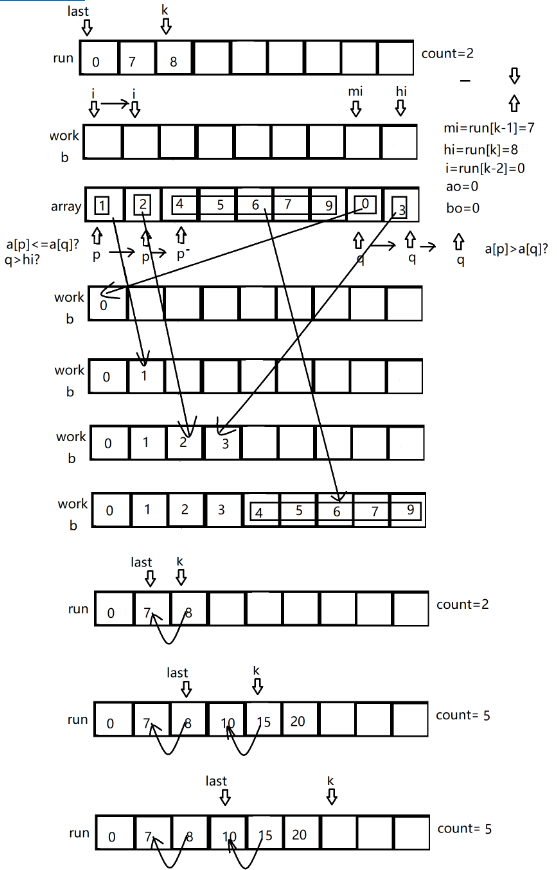
merge sort
归并排序(merge sort) 具体算法: I.对原数组进行分组:对数组进行遍历,每检测出一个有序序列则记录一个分组,一般分组都是上升序列,下降序列也会被转换成上升序列 II.对两两相邻的分组进行合并,合并后的分组也将被记录 III.迭代合并之前合并后的分组直到出现最后的一个有序的大分组,也就是排序的最终结果 java.util.DualPivotQuicksort类中的static void ...
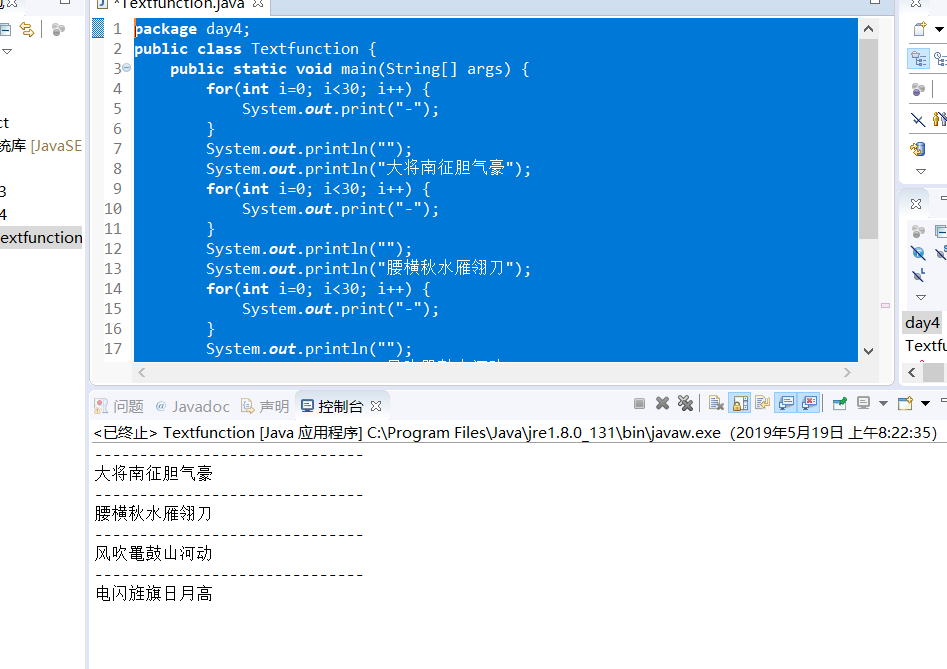
Java函数的学习
java学习 百知教育学习 - 胡鑫喆 - Java函数的学习 01_函数的定义 函数的定义 概念:实现特定功能的一段代码,可反复使用 定义语法: 函数名称许遵循命名规范 函数定义在类的内部,与main函数并列,并且使函数产生作用,需进行函数的调用 使用函数去掉冗余代码 02_函数的参数 函数的参数(函数名称() 其中()就是一个参数表) 无参函数(01_函数的定义中的下划线就为无参函数) 有参函...