【python PDF合并】python 合并同一个文件夹下所有PDF文件
一、需求说明
下载了网易云课堂的吴恩达免费的深度学习的pdf文档,但是每一节是一个pdf,我把这些PDF文档放在一个文件夹下,希望合并成一个PDF文件。于是写了一个python程序,很好的解决了这个问题。
二、数据形式

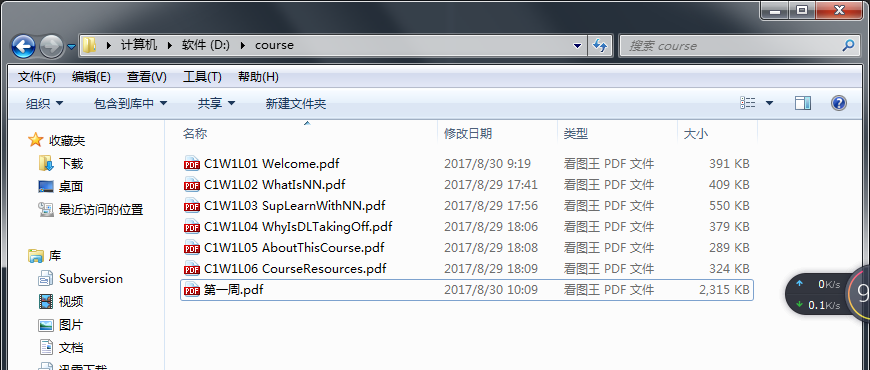
三、合并效果
四、python代码实现
# -*- coding:utf-8*-
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import os
import os.path
from pyPdf import PdfFileReader,PdfFileWriter
import time
time1=time.time()
# 使用os模块walk函数,搜索出某目录下的全部pdf文件
######################获取同一个文件夹下的所有PDF文件名#######################
def getFileName(filepath):
file_list = []
for root,dirs,files in os.walk(filepath):
for filespath in files:
# print(os.path.join(root,filespath))
file_list.append(os.path.join(root,filespath))
return file_list
##########################合并同一个文件夹下所有PDF文件########################
def MergePDF(filepath,outfile):
output=PdfFileWriter()
outputPages=0
pdf_fileName=getFileName(filepath)
for each in pdf_fileName:
print each
# 读取源pdf文件
input = PdfFileReader(file(each, "rb"))
# 如果pdf文件已经加密,必须首先解密才能使用pyPdf
if input.isEncrypted == True:
input.decrypt("map")
# 获得源pdf文件中页面总数
pageCount = input.getNumPages()
outputPages += pageCount
print pageCount
# 分别将page添加到输出output中
for iPage in range(0, pageCount):
output.addPage(input.getPage(iPage))
print "All Pages Number:"+str(outputPages)
# 最后写pdf文件
outputStream=file(filepath+outfile,"wb")
output.write(outputStream)
outputStream.close()
print "finished"
if __name__ == '__main__':
file_dir = r'D:/course/'
out=u"第一周.pdf"
MergePDF(file_dir,out)
time2 = time.time()
print u'总共耗时:' + str(time2 - time1) + 's'
"D:\Program Files\Python27\python.exe" D:/PycharmProjects/learn2017/合并多个PDF文件.py
D:/course/C1W1L01 Welcome.pdf
3
D:/course/C1W1L02 WhatIsNN.pdf
4
D:/course/C1W1L03 SupLearnWithNN.pdf
4
D:/course/C1W1L04 WhyIsDLTakingOff.pdf
3
D:/course/C1W1L05 AboutThisCourse.pdf
3
D:/course/C1W1L06 CourseResources.pdf
3
All Pages Number:20
finished
总共耗时:0.128000020981s
Process finished with exit code 0智能推荐

【python】多图片合并PDF
python 多图片合并pdf 起因 一个做美工的朋友需要将多个图片jpg 、png 合并起来,PS操作太慢了所以用了python进行完成这个任务 代码 - 合成后...

python将文件夹中所有文件合并成一个csv文件
背景 文件夹2019 的文件为csv文件,文件夹2020的文件为excel文件 目的 将两个文件夹中所有的文件合并成一个表格,以便进行后续的数据分析 反思 因为是不同的文件格式,只能将文件分成两个文件夹,分两次遍历文件。 步骤 a:先遍历excel2020文件夹所有的文件,合并一个csv表至2019文件夹 b:遍历2019文件夹所有的文件名,合并csv终表。 通过print(filename_ex...

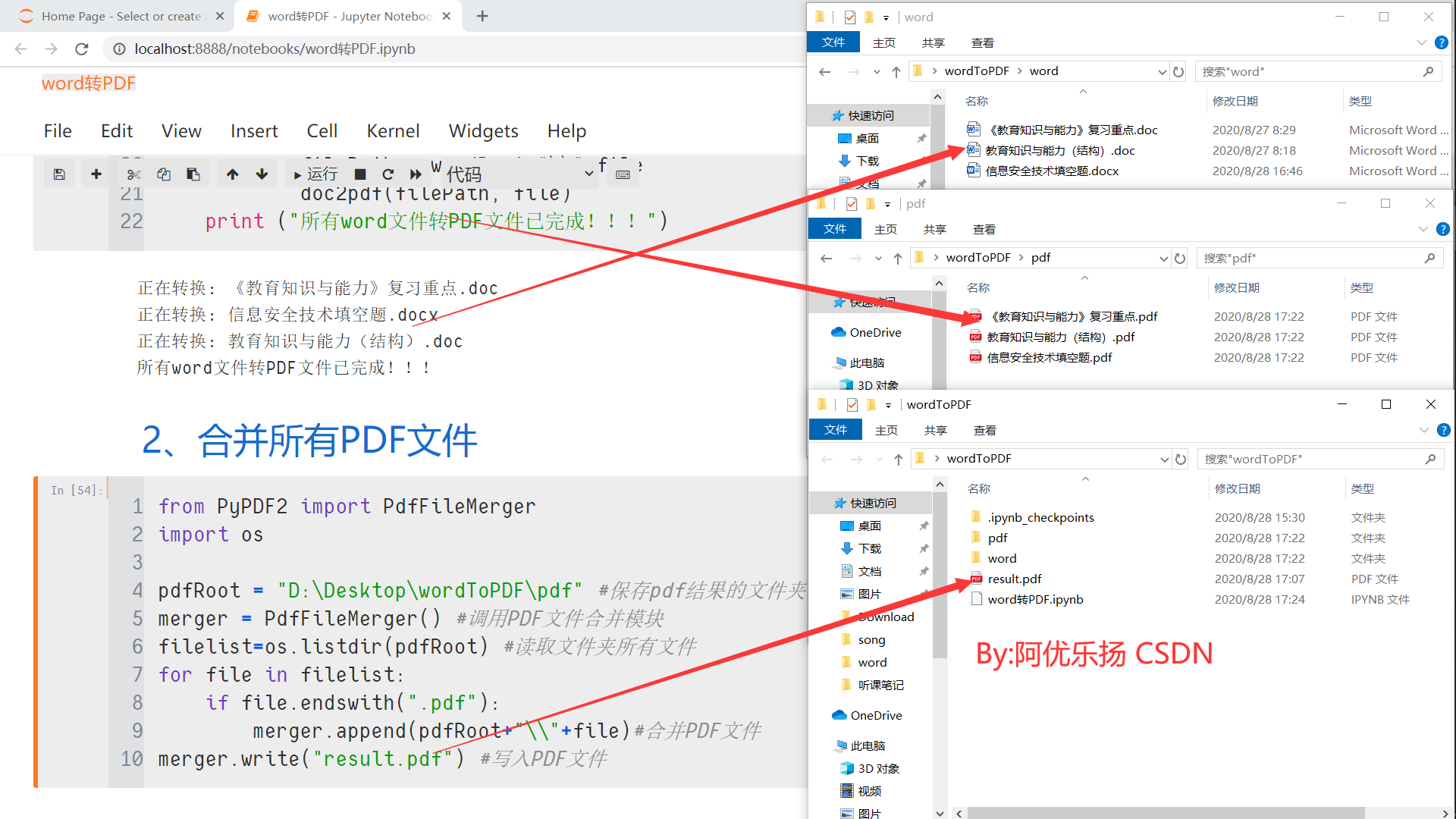
python完成文件夹批量word转pdf文件及pdf文件合并+word文件合并
前言:有同学问我,如何把文件夹中的文件一次性完成打印,由于文件太多,单个打印着实麻烦。这些文件主要有三种类型,分别为PDF,word(.doc和.docx),我决定把他们全部变为PDF文件,然后再合并所有的pdf文件为一个PDF文件,分两个步骤完成! 1.把所有word转化为PDF 2.合并所有PDF文件 3.多个word文件合并...
猜你喜欢
centos7部署配置迁移SVN
部署 安装 查看版本 创建版本库 配置svn信息 进入版本库中的配置目录conf,此目录有三个文件: svn服务综合配置文件(svnserve.conf)、 用户名口令文件(passwd)、权限配置文件(authz) svnserve.conf authz passwd 启用 连接路径 http配置 安装apache 修改apache默认端口 启动apache 测试,访问下面连接,出现apache...
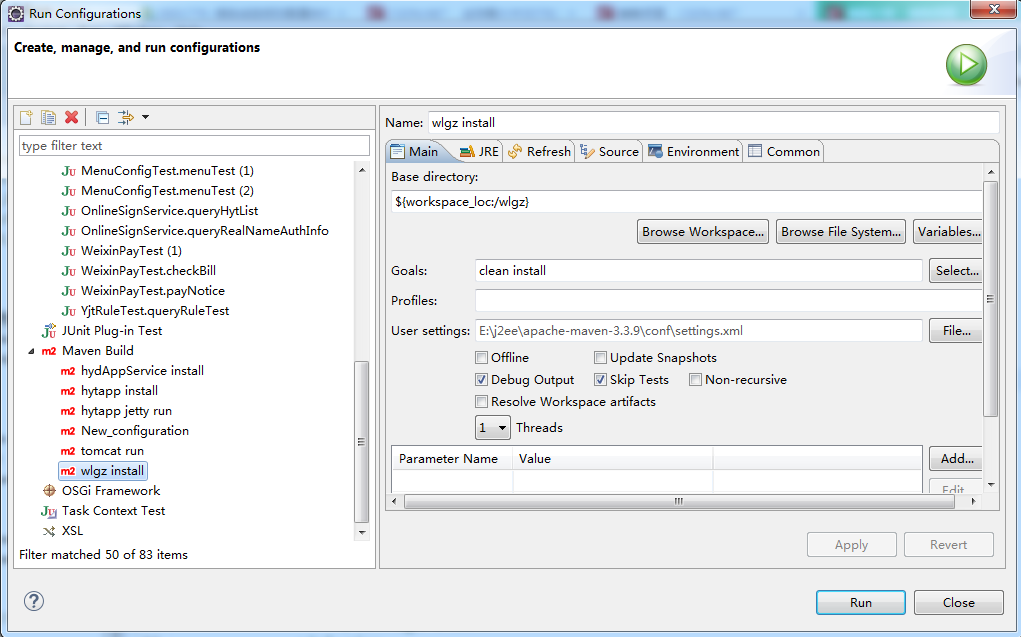
maven启动web工程
1.在pom.xml中新增了 打包install时会将xml相关文件打到war包中。 2.配置tomcat或者jetty容器 3.选择web项目右键,run as -->run configurations 双击maven build进入下面页面 4.一般先install在run,下面以tomcat启动为例。 5.如下图:...

Hadoop 之Mapreduce wordcount词频统计案例(详解)
阅读目录 一、创建项目 :example-hdfs 二、项目目录 三、WordCountMapper.class 四、WordCountReducer.class 五、WordCounfDriver.class 六、pom.xml 七、打包jar包 八、在SecureCRT软件上传刚刚生成的jar包 九、运行 十、错误及解决 MapReduce是什么? Map Reduce是Google公司开源的...
分享 webpack3.0 的安装与使用
准备开始 webpack3.0 的安装 之前在很多网站上寻找webpack3.0的知识,但是结果都不理想。经过很多努力,终于学到了一些知识,现在把这些知识分享出来吧。(希望能对小伙伴有所帮助) 全局安装 1.jpg 2.jpg 3.jpg 4.jpg 局部安装 5.jpg 更新webpack &nbs...

快速实现上滑加载更多
实现方式 在智能小程序的开发过程中,经常会遇到页面列表数量较多的情况,此时可以通过【分页】加载数据,并监听页面滑动到底部时触发【上滑加载更多】,从而增加页面首屏渲染速度。 想要实现这种分页展示数据,上滑加载更多的效果,主要有以下几种方式: 1. 使用 view自定义信息流组件 + onReachBottom 2. 使用 scroll-view + bindscrolltolower 3. 使用 s...