linux Haproxy+rabbitMQ 镜像集群安装
标签: rabbitmq
rabbitMQ 安装需要安装erlang,erlang 需要 c++编译处理。因此安装步骤如下:
多说一句,为了以后集群方便知道 rabbitmq在那个主机,建议修改hostname。具体修改方法请参考其他网友解决方案
如:http://blog.csdn.net/yangshangwei/article/details/52878530
我分别给两台服务器修改了hostname, 修改后的ip和hostname 分别为:
172.17.209.21 zqadmin
172.17.209.22 zaweb
下一步分别给两台主机分别安装rabbitmq
一、c++ 安装
yum -y install make gcc gcc-c++ kernel-devel m4 ncurses-devel openssl-devel unixODBC unixODBC-devel httpd python-simplejson1.下载erlang
wget http://erlang.org/download/otp_src_19.2.tar.gz
tar -xzvf otp_src_19.2.tar.gz
cd otp_src_19.2
./configure --prefix=/usr/local/erlang --enable-smp-support --enable-threads --enable-sctp --enable-kernel-poll --enable-hipe --with-ssl --without-javac
–prefix 指定安装目录
–enable-smp-support启用对称多处理支持(Symmetric Multi-Processing对称多处理结构的简称)
–enable-threads启用异步线程支持
–enable-sctp启用流控制协议支持(Stream Control Transmission Protocol,流控制传输协议)
–enable-kernel-poll启用Linux内核poll
–enable-hipe启用高性能Erlang –with-ssl 启用ssl包 –without-javac 不用java编译
make && make install 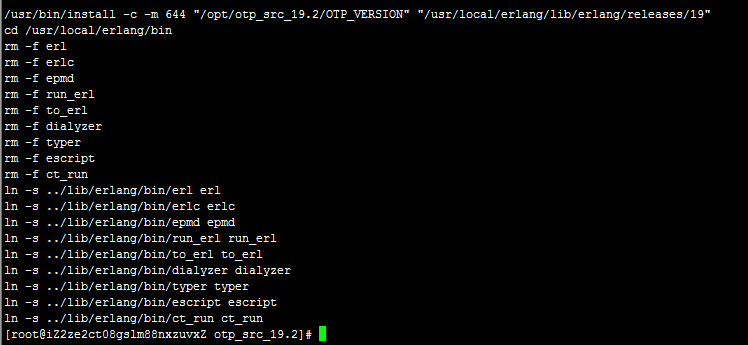
到这就编译完成
6.配置erlang环境变量
6.1 vim /etc/profile6.2 在文件末尾添加:export PATH=/usr/local/erlang/bin:$PATH6.3 是环境变量生效:source /etc/profile6.4 检验是否安装完成:在 erlang 目录执行 erl
出现上图结果、则表明已安装完成。然后 ctrl+c 回车;a 退出即可。
三、rabbitmq安装
1、下载rabbitmq安装包
wget http://www.rabbitmq.com/releases/rabbitmq-server/v3.6.9/rabbitmq-server-generic-unix-3.6.9.tar.xz
tar -xvf rabbitmq-server-generic-unix-3.6.9.tar.xz
mv rabbitmq_server-3.6.9/ /usr/local/rabbitmqvim /etc/profile
文件最后加上
export PATH=/usr/local/rabbitmq/sbin:$PATH
source /etc/profile
rabbitmq-plugins enable rabbitmq_management7、启动rabbitmq服务(-detached 为后台启动)
./usr/local/rabbitmq/sbin/rabbitmq-server -detached8、添加用户权限(rabbitmq安装完之后默认有guest账号,如果在windows中可以用guest账号登录,密码也是guest)
./usr/local/rabbitmq/sbin/rabbitmqctl add_user admin admin9、添加权限(以下命令都需要再 rabbitmq目录中 sbin中执行)
rabbitmqctl set_permissions -p "/" admin ".*" ".*" ".*"rabbitmqctl set_user_tags admin administrator
有关 rabbitMQ 相关命令请移步:rabbitMQ ——windows安装(rabbitmq之一)
按照以上步骤再安装另外一台rabbitmq,需要注意的是,如果有防火墙切记需要开启访问端口、否则无法访问了
四、修改hosts文件,同步.erlang.cookie,将rabbitmq服务器的ip hostname分别添加到各个主机中,比如我的:
1、用vi /ect/hosts hosts文件
在172.17.209.21中
172.17.209.22 zqweb
chmod
777 .erlang.cookie
2-4.拷贝文件
scp-P
5898 .erlang.cookie root@zqweb:/root/.erlang.cookie
然后输入服务器密码即可,标红是因为我把服务器ssh端口号改为5898了。如果还是默认22,去掉即可。
2-5.恢复文件权限(源文件权限为400)
chmod 400 .erlang.cookie
2-6.查看服务器所有 .erlang.cookie文件内容、以确保所有服务器的文件统一

五、rabbitmq集群设置
1、先查看一下各服务器rabbitmq状态
rabbitmqctl status
2、如果已启动?停止重启:启动
停止:rabbtimqctl stop
启动:rabbitmq-service -detached(后台启动)
查看状态:rabbitmqctl status
3、集群配置 命令 join_cluster(集群配置中,需要至少有一个节点为磁盘节点也就是将数据存储在磁盘,rabbitmq默认磁盘节点)
3-1、rabbitmq-service启动rabbitmq会启动节点和应用,要配置集群需要将应用停掉
3-2、选一个rabbitmq作为cluster
然后再其他rabbitmq中使用:rabbitmqctl stop_app 此命令只会停应用、不停节点。
我这就两台。我选择zqadmin作为主cluster,zqweb加入到zqadmin中。
3-3、在zqweb中执行:(使用 join_cluster --ram 把zqweb作为内存节点,也就是存在内存中)
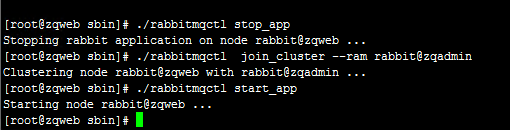
3-4、查看内存节点状态(任意机器都可以)
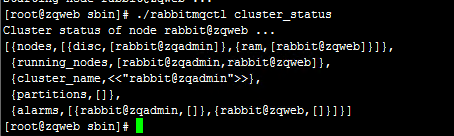
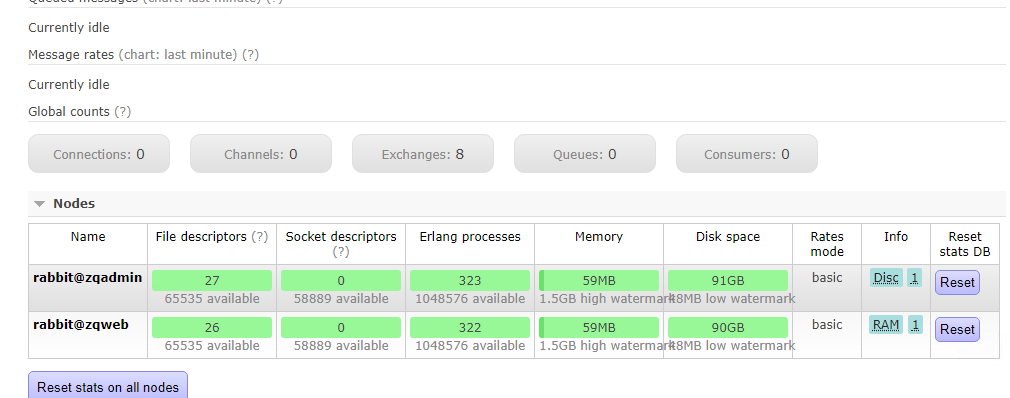
看见看到 nodes中 disc(磁盘节点)的 rabbit@zqadmin 以及 ram(内存节点)的 rabbit@zqweb
同时也可以在web 管理端查看,如下:
3-5、镜像策略配置
a).rabbitmqctl
set_policy ha-all "^" '{"ha-mode":"all"}'
设置各个节点的所有状态全部一致
b).也可以在页面端设置 admin-policies 中设置
到此rabbitMQ的镜像安装完成了。下一步安装haproxy
六、haproxy负载均衡安装。
本文采用安装包的方式安装。
1.下载安装包:
地址HA下载,我下载的是:1.7.9版本。
2.解压压缩包:
tar -zxvf haproxy-1.7.9.tar.gz;进入HA文件夹:cd haproxy/
3.安装:
make TARGET=linux26 ARCH=x86_64 PREFIX=/usr/local/haproxy
make install PREFIX=/usr/local/haproxy
参数说明
TARGET=linux26 #内核版本,使用uname -r查看内核,如:2.6.32-431.23.3.el6.x86_64,此时该参数就为linux26;kernel 大于2.6.28的用:TARGET=linux2628
ARCH=x86_64 #系统位数
PREFIX=/usr/local/haprpxy #/usr/local/haprpxy为haprpxy安装路径
最终安装完的目录结构为:
4.编写配置文件
在haproxy 中创建一个文件夹 conf 在conf中创建haproxy.cfg配置文件
haproxy.cfg文件内容为:
###########全局配置#########
global
log 127.0.0.1 local0 #[日志输出配置,所有日志都记录在本机,通过local0输出]
chroot /usr/local/haproxy # 改变当前工作目录
pidfile /var/run/haproxy.pid # haproxy的pid存放路径,启动进程的用户必须有权限访问此文件
maxconn 4000 # 最大连接数,默认4000
daemon # 创建1个进程进入deamon模式运行。此参数要求将运行模式设置为"daemon
###########默认配置#########
defaults
log 127.0.0.1 local3 #日志文件的输出定向
mode http # 默认的模式mode { tcp|http|health },tcp是4层,http是7层,health只会返回OK
option httplog # 采用http日志格式
option dontlognull # 启用该项,日志中将不会记录空连接。所谓空连接就是在上游的负载均衡器
# 或者监控系统为了探测该 服务是否存活可用时,需要定期的连接或者获取某
# 一固定的组件或页面,或者探测扫描端口是否在监听或开放等动作被称为空连接;
# 官方文档中标注,如果该服务上游没有其他的负载均衡器的话,建议不要使用
# 该参数,因为互联网上的恶意扫描或其他动作就不会被记录下来
option httpclose # 每次请求完毕后主动关闭http通道
#option forwardfor # 如果后端服务器需要获得客户端真实ip需要配置的参数,可以从Http Header中获得客户端ip
option redispatch # serverId对应的服务器挂掉后,强制定向到其他健康的服务器
timeout connect 5000 # 连接超时时间
timeout client 50000 # 客户端连接超时时间
timeout server 50000 # 服务器端连接超时时间
timeout connect 10000 # default 10 second timeout if a backend is not found
maxconn 60000 # 最大连接数
retries 3 # 3次连接失败就认为服务不可用,也可以通过后面设置
####################################################################
listen http_front
bind 0.0.0.0:1080 #监听端口
stats refresh 30s #统计页面自动刷新时间
stats uri /haproxy?stats #统计页面url
stats realm Haproxy Manager #统计页面密码框上提示文本
stats auth admin:admin #统计页面用户名和密码设置
#stats hide-version #隐藏统计页面上HAProxy的版本信息
######################RabbitMQ监控##############################################
listen rabbitmq_cluster
bind 0.0.0.0:8100
option tcplog
mode tcp
timeout client 3h
timeout server 3h
option clitcpka
balance roundrobin #负载均衡算法(#banlance roundrobin 轮询,balance source 保存session值,支持static-rr,leastconn,first,uri等参数)
#balance url_param userid
#balance url_param session_id check_post 64
#balance hdr(User-Agent)
#balance hdr(host)
#balance hdr(Host) use_domain_only
#balance rdp-cookie
#balance leastconn
#balance source //ip
server zqadmin 172.17.209.21:5672 check inter 5s rise 2 fall 3 #check inter 2000 是检测心跳频率,rise 2是2次正确认为服务器可用,fall 3是3次失败认为服务器不可用
server zqweb 172.17.209.22:5672 check inter 5s rise 2 fall 3
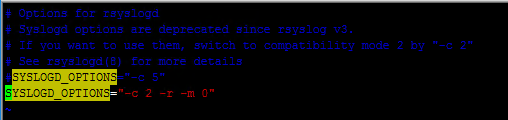
5-1、修改系统日志配置文件
vim /etc/sysconfig/rsyslog
修改为:将#SYSLOGD_OPTIONS="-c 5" 修改为:SYSLOGD_OPTIONS="-c 2 -r -m 0"
5-2、增加日志设备
vi /etc/rsyslog.conf
在最下面添加:

5-3、重启rsyslog
service rsyslog restart
6、开机启动
创建脚本:vim /etc/rc.d/init.d/haproxy,内容为:
#! /bin/sh
# chkconfig: 2345 10 90
# description: myservice ....
set -e
PATH=/sbin:/bin:/usr/sbin:/usr/bin:/usr/local/haproxy/sbin
PROGDIR=/usr/local/haproxy
PROGNAME=haproxy
DAEMON=$PROGDIR/sbin/$PROGNAME
CONFIG=$PROGDIR/conf/$PROGNAME.cfg
PIDFILE=/var/run/$PROGNAME.pid
DESC="HAProxy daemon"
SCRIPTNAME=/etc/init.d/$PROGNAME
# Gracefully exit if the package has been removed.
test -x $DAEMON || exit 0
start()
{
echo -n "Starting $DESC: $PROGNAME"
$DAEMON -f $CONFIG
echo "."
}
stop()
{
echo -n "Stopping $DESC: $PROGNAME"
haproxy_pid=cat $PIDFILE
kill $haproxy_pid
echo "."
}
restart()
{
echo -n "Restarting $DESC: $PROGNAME"
$DAEMON -f $CONFIG -p $PIDFILE -sf $(cat $PIDFILE)
echo "."
}
case "$1" in
start)
start
;;
stop)
stop
;;
restart)
restart
;;
*)
echo "Usage: $SCRIPTNAME {start|stop|restart}" >&2
exit 1
;;
esac
exit 0
赋予执行权限: chmod +x /etc/rc.d/init.d/haproxy
添加开机启动:chkconfig --add haproxy
注:脚本第2/3 行用于开机启动、否则回报错误,如下:

第二行告诉chkconfig缺省启动的运行级以及启动和停止的优先级。如果某服务缺省不在任何运行级启动,那么使用 - 代替运行级。
第二行对服务进行描述,可以用\ 跨行注释。
其中2345是默认启动级别,级别有0-6共7个级别。
等级0表示:表示关机
等级1表示:单用户模式
等级2表示:无网络连接的多用户命令行模式
等级3表示:有网络连接的多用户命令行模式
等级4表示:不可用
等级5表示:带图形界面的多用户模式
等级6表示:重新启动
10是启动优先级,90是停止优先级,优先级范围是0-100,数字越大,优先级越低。
特别注意的是:服务脚本必须存放在/etc/ini.d/目录下
参考文献:https://www.cnblogs.com/lion.net/p/5725474.html
http://www.linuxidc.com/Linux/2016-10/136492.htm
http://blog.51cto.com/johnsz/715922
http://www.mamicode.com/info-detail-1425092.html
到此HA+RMQ就基本完成了。稍后再做一下RMQ开机启动。
智能推荐
Linux下安装Spark集群
1.安装Scala 1.1 下载解压安装包 1.2 配置环境变量 2.下载解压Spark安装包 3.配置环境变量 4.配置Spark系统文件 5.启动集群 6.报错 如果是权限不足Permission denied 只是因为没有写入的权限,因此只需要修改目标文件夹的权限即可,使其拥有写入权限。 如果启动的时候报 chown: changing ownership of ‘/usr/lo...

Linux上安装hadoop集群
1.下载hadoop 本博文使用的hadoop是2.9.0 打开下载地址选择页面:http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.9.0/hadoop-2.9.0.tar.gz 2.修改hosts并实现ssh免密码 登录 我这里已经提前安装好了三台虚拟机,hostname分别为had01,ha...
Linux下 kafka集群安装
环境:CentOS 7虚拟机两台,分别为:192.168.31.224和192.168.31.225 1、安装之前先安装jdk和zookeeper 2、下载 kafka_2.12-1.1.0.tgz,下载地址为:https://mp.csdn.net/mdeditor 3、解压kafka_2.12-1.1.0.tgz,使用命令tar -zxvf kafka_2.12-1.1.0.tgz,解压之后会...
linux下nacos集群安装
1、下载nacos安装包 官网地址:https://github.com/alibaba/nacos/tags,我下载的是1.2.1版本的。 2、解压nacos-server-1.2.1.tar.gz 3、执行conf目录下的nacos-mysql.sql文件 4、拷贝一份application.properties文件 配置该文件中的数据库连接,如下图 5、再拷贝一份cluster.conf文件...
ElasticSerach Linux集群安装部署
版本:elasticsearch-6.2.4,环境:2台linux(192.168.13.111、12.168.13.222) jdk1.8(必须) 解压elasticsearch-6.2.4.tar.gz 解压后进入目录: config目录里面是配置文件 elasticsearch.yml # els的配置文件 jvm.options # JVM相关的配置,...
猜你喜欢
Linux上RabbitMQ集群安装
RabbitMQ集群安装 1.版本信息 Version: 3.6.15 Official Document URL: https://www.rabbitmq.com/download.html Local image path: /rabbitmq Denpendency: Erlang 2.安装步骤 下载rpm安装介质rabbitmq-server-3.6.15-1.el7.noarch.rp...
elasticsearch安装——linux集群方式
elasticsearch安装——linux集群方式 安装elasticsearch在Linux下的方法如下。如果想要在windows上运行的话,请参考文章: http://blog.csdn.net/wild46cat/article/details/62040347 好,下面上货。 1、下载elasticsearch https://www.elastic.co/dow...

Mybatis基础(part 1)
一.mybatis调用SQL语句 1.使用XML配置SQL语句 在SqlMapConfig.xml配置数据源并指定映射配置文件的位置(每个DAO对应的XML文件,该文件映射了DAO的全限定类名) 2.使用注解配置sql语句 在SqlMapConfig.xml配置数据源和class属性(指定被注解的dao全限定类名),在DAO上写注解。 用注解来配置,故此处使用class属性指定被注解...

Docker 容器内运行 Dubbo 服务
原文:http://www.aqcoder.com/post/content?id=41 在使用 Docker 容器内运行 Dubbo 服务的时候一个令人很头痛的问题就是服务地址注册。 Docker 容器内有自己的 IP 段,和宿主主机是隔离的,Dubbo 会使用容器内的 IP 注册到 zookeeper 注册中心上。这样其他的服务是无法访问的。 方式一:–host 一个很直接的方案就...