一个RandomizedSearchCV和GridSearchCV组合使用调参的例子------先随机大致搜索,再网格精细化搜索
温度预测示例&参数优化工具RandomizedSearchCV
taon关注
0.1292019.12.06 18:18:08字数 2,203阅读 523
一般情况下,我们做数据挖掘任务都是按照“数据预处理 - 特征工程 - 构建模型(使用默认参数或经验参数) - 模型评估 - 参数优化 - 模型固定”这样一个流程来处理问题。这一小节,我们要讨论的主题就是参数优化,前面我们讨论过GridSearchCV(网格搜索)这个工具,它是对我们的参数进行组合,选取效果最好的那组参数。
data mining.jpg
这一节,我们探索下参数优化当中的另一个工具RandomizedSearchCV(随机搜索),这名字咋一听感觉有点不太靠谱,对,它是有点不太靠谱,但为什么我们还要用它呢?因为它的效率高,它可以快速地帮助我们确定一个参数的大概范围,然后我们再使用网格搜索确定参数的精确值。就像警察抓犯人一样,先得快速地确认罪犯的活动区域,然后在该区域内展开地毯式搜索,这样效率更高。
这一小节,我们以随机森林模型作为例子,通过演示一个完整的建模过程,来说明RandomizedSearchCV的用法。当然这个工具不是随机森林特有的,它可以应用于任何模型的参数优化当中。
RandomForestRegressor.png
从上图可以看出随机森林模型有很多参数,如:n_estimators, max_depth, min_samples_split, min_samples_leaf,max_features,bootstrap等。每一个参数都会对最终结果产生影响,同时每一个参数又有着众多的取值,我们的目标是找到最优的参数组合,使得我们的模型效果最好。
RandomizedSearchCV工具:
官方文档:
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.RandomizedSearchCV.html?highlight=randomized#sklearn.model_selection.RandomizedSearchCV
RandomizedSearchCV.png
RandomizedSearchCV参数说明:
- estimator:我们要传入的模型,如KNN,LogisticRegression,RandomForestRegression等。
- params_distributions:参数分布,字典格式。将我们所传入模型当中的参数组合为一个字典。
- n_iter:随机寻找参数组合的数量,默认值为10。
- scoring:模型的评估方法。在分类模型中有accuracy,precision,recall_score,roc_auc_score等,在回归模型中有MSE,RMSE等。
- n_jobs:并行计算时使用的计算机核心数量,默认值为1。当n_jobs的值设为-1时,则使用所有的处理器。
- iid:bool变量,默认为deprecated,返回值为每折交叉验证的值。当iid = True时,返回的是交叉验证的均值。
- cv:交叉验证的折数,最新的sklearn库默认为5。
接下来,我们采用温度数据集作为例子,来演示RandomizedSearchCV的用法。我们将进行一个完整的数据建模过程:数据预处理 - 模型搭建 - RandomizedSearchCV参数优化 - GridSearchCV参数优化 - 确定最优参数,确定模型。
温度数据集:链接:https://pan.baidu.com/s/1q10_Vz7ujuu8oCOqysNU7A
提取码:bxcr
任务目标:基于昨天和前天的一些历史天气数据,建立模型,预测当天的最高的真实温度。
数据集中主要特征说明:
- ws_1:昨天的风速。
- prcp_1:昨天的降水量。
- snwd_1:昨天的降雪厚度。
- temp_1:昨天的最高温度。
- temp_2:前天的最高温度。
- average:历史中这一天的平均最高温度。
- actual:当天的真实最高温度。
建模完整过程演示:
#导入数据分析的两大工具包
import numpy as np
import pandas as pd
#读取数据
df = pd.read_csv('D:\\Py_dataset\\temps_extended.csv')
df.head()
#查看数据的规模
df.shape
(2191, 12)#该数据集有2191个样本,每个样本有12个特征。
1.数据预处理
该数据集整体上是比较干净的,没有缺失值和异常值。这一步我们熟悉下数据预处理的基本过程。
# 1.查看数据集的基本信息
df.info()
df info.png
从上述结果可以看出这份数据集的整体情况。一共2191个样本,索引从0开始,截止于2190。一共12个特征,每个特征的数量为2191,缺失值情况(non-null),类型(int64 or object or float64),内存使用205.5KB。
由于数据没有缺失值,所以我们不需要做缺失值处理。接下来我们看数据类型,由于计算机只能识别数值型数据,所以我们必须将数据集中的非数值型数据转化为数值型数据。该数据集中只有"weekday"是object类型,由于我们要预测的是今天的温度值,所以日期数据(如昨天是几号,星期几)对我们的结果没有什么影响,将这些日期数据删掉。数据集中有一个"friend"特征,该值的意思可能是朋友的猜测结果,在建模过程中,我们暂不关注这个特征,所以将"friend"特征也删掉。
df = df.drop(['year','month','day','weekday','friend'],axis = 1)
df.head()
clean-data.png
2.数据切分
当我们完成了数据集清洗之后,接下来就是将原始数据集切分为特征(features)和标签(labels)。接着将特征和标签再次切分为训练特征,测试特征,训练标签和测试标签。
#导入数据切分模块
from sklearn.model_selection import train_test_split
#提取数据标签
labels = df['actual']
#提取数据特征
features = df.drop('actual',axis = 1)
#将数据切分为训练集和测试集
train_features,test_features,train_labels,test_labels = train_test_split(features,labels,
test_size = 0.3,random_state = 0)
print('训练特征的规模:',train_features.shape)
print('训练标签的规模:',train_labels.shape)
print('测试特征的规模:',test_features.shape)
print('测试标签的规模:',test_labels.shape)
#切分之后的结果
训练特征的规模: (1533, 6)
训练标签的规模: (1533,)
测试特征的规模: (658, 6)
测试标签的规模: (658,)
3.建立初始随机森林模型
建立初始模型,基本上都使用模型的默认参数,建立RF(RandomForestRegressor)模型,我们唯一指定了一个n_estimators参数。
from sklearn.ensemble import RandomForestRegressor
#建立初始模型
RF = RandomForestRegressor(n_estimators = 100,random_state = 0)
#训练数据
RF.fit(train_features,train_labels)
#预测数据
predictions = RF.predict(test_features)
4.模型评估
该例子我们使用的是回归模型,预测结果是一个准确的数值。我们的目标是希望我们的预测结果与真实数据的误差越好。所以我们在此选用的模型评估方法为均方误差(mean_squared_error)和均方根误差(root_mean_squared_error)。下式分别是MSE和RMSE的计算公式,其中Yi为真实值,Yi^为预测值。
MSE.png
RMSE.png
from sklearn.metrics import mean_squared_error
#传入真实值,预测值
MSE = mean_squared_error(test_labels,predictions)
RMSE = np.sqrt(MSE)
print('模型预测误差:',RMSE)
模型预测误差: 5.068073484568353
5.RandomizdSearchCV参数优化
from sklearn.model_selection import RandomizedSearchCV
RF = RandomForestRegressor()
#设置初始的参数空间
n_estimators = [int(x) for x in np.linspace(start = 200,stop = 2000,num = 10)]
min_samples_split = [2,5,10]
min_samples_leaf = [1,2,4]
max_depth = [5,8,10]
max_features = ['auto','sqrt']
bootstrap = [True,False]
#将参数整理为字典格式
random_params_group = {'n_estimators':n_estimators,
'min_samples_split':min_samples_split,
'min_samples_leaf':min_samples_leaf,
'max_depth':max_depth,
'max_features':max_features,
'bootstrap':bootstrap}
#建立RandomizedSearchCV模型
random_model =RandomizedSearchCV(RF,param_distributions = random_params_group,n_iter = 100,
scoring = 'neg_mean_squared_error',verbose = 2,n_jobs = -1,cv = 3,random_state = 0)
#使用该模型训练数据
random_model.fit(train_features,train_labels)
Random_model fit process.png
我们观察下模型的训练过程,我们设置了n_iter=100,由于交叉验证的折数=3,所以该模型要迭代300次。第二层显示的是训练过程的用时,训练完成总共用了6.2min。第三层显示的是参与训练的参数。
使用集成算法的属性,获得Random_model最好的参数
random_model.best_params_
{'n_estimators': 1200,
'min_samples_split': 5,
'min_samples_leaf': 4,
'max_features': 'auto',
'max_depth': 5,
'bootstrap': True}
将得出的最优参数,传给RF模型,再次训练参数,并进行结果预测。可以看到经过参数优化后,模型的效果提升了2%。
RF = RandomForestRegressor(n_estimators = 1200,min_samples_split = 5,
min_samples_leaf = 4,max_features = 'auto',max_depth = 5,bootstrap = True)
RF.fit(train_features,train_labels)
predictions = RF.predict(test_features)
RMSE = np.sqrt(mean_squared_error(test_labels,predictions))
print('模型预测误差:',RMSE)
print('模型的提升效果:{}'.format(round(100*(5.06-4.96)/5.06),2),'%')
模型预测误差: 4.966401154246091
模型的提升效果:2 %
6.使用GridSearhCV对参数进行进一步优化
上一步基本上确定了参数的大概范围,这一步我们在该范围,进行更加细致的搜索。网格搜索的效率比较低,这里我只选择了少数的几个参数,但是用时也达到了9分钟。如果参数增加,模型训练的时间将会大幅增加。
from sklearn.model_selection import GridSearchCV
import time
param_grid = {'n_estimators':[1100,1200,1300],
'min_samples_split':[4,5,6,7],
'min_samples_leaf':[3,4,5],
'max_depth':[4,5,6,7]}
RF = RandomForestRegressor()
grid = GridSearchCV(RF,param_grid = param_grid,scoring = 'neg_mean_squared_error',cv = 3,n_jobs = -1)
start_time = time.time()
grid.fit(train_features,train_labels)
end_time = time.time()
print('模型训练用时:{}'.format(end_time - start_time))
模型训练用时:534.4072196483612
获得grid模型最好的参数
grid.best_params_
{'max_depth': 5,
'min_samples_leaf': 5,
'min_samples_split': 6,
'n_estimators': 1100}
将最好的模型参数传给RF模型,再次对数据进行训练并作出预测。
RF = RandomForestRegressor(n_estimators = 1100,min_samples_split = 6,
min_samples_leaf = 5,max_features = 'auto',max_depth = 5,bootstrap = True)
RF.fit(train_features,train_labels)
predictions = RF.predict(test_features)
RMSE = np.sqrt(mean_squared_error(test_labels,predictions))
print('模型预测误差:',RMSE)
模型预测误差: 4.969890784882202
从结果来看,模型效果并没有什么提升,说明在随机搜索的过程中,已经找到了最优参数。最终结果模型预测的温度与实际温度相差4.96华氏度(2.75℃)。我们以该数据集作为一个示例,总结数据挖掘的全过程以及RandomizedSearchCV工具,在具体的调参工作中也是通过一步一步去优化参数,不断缩小预测值与真实值之间的误差。
prediction result.png
7.总结
- 1.随机参数选择模型(RandomizedSearchCV)可以帮助我们快速的确定参数的范围。
- 2.对于随机参数选择模型而言,初始的特征空间选择特别重要。如果初始的特征空间选择不对,则后面的调参工作都可能是徒劳。我们可参考一些经验值或者做一些对比试验,来确定模型的参数空间。
- 3.RandomizedSearchCV和GridSearchCV搭配使用,先找大致范围,再精确搜索。
- 4.通过优化模型参数,虽然每次的提升幅度不是很大,但是通过多次的优化,这些小的提升累加在一起就是很大的提升。
- 5.遇到不懂的问题,多查看sklearn官方文档,这是一个逐渐积累和提升的过程。
智能推荐
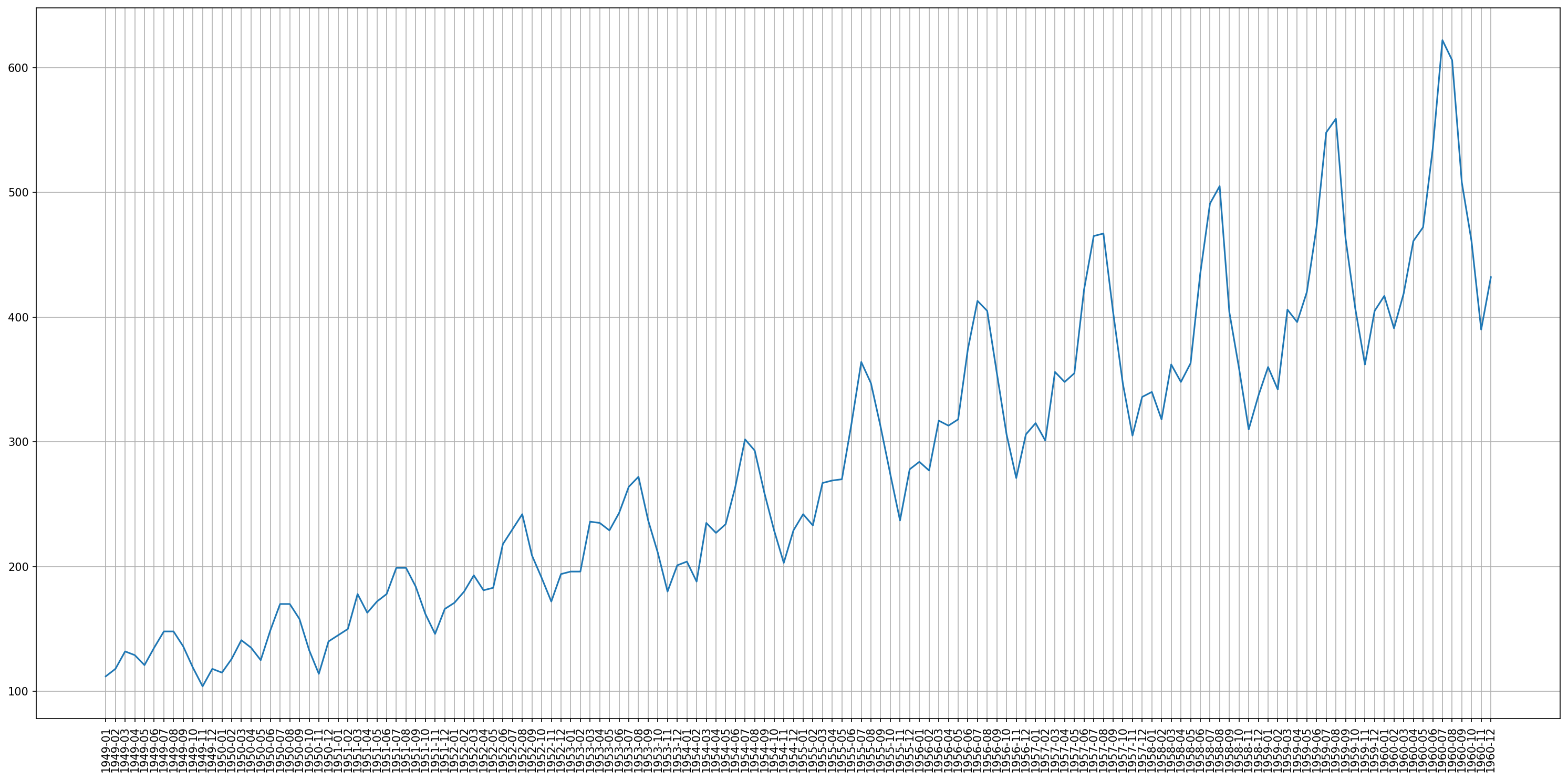
【调参01】如何使用网格搜索寻找最佳超参数配置
本文介绍了如何使用网格搜索寻找网络的最佳超参数配置。 文章目录 1. 准备数据集 2. 问题建模 2.1 训练集测试集拆分 2.2 转化为监督学习问题 2.3 前向验证 2.4 重复评估 2.5 网格搜索 2.6 实例化 3. 使用网格搜索寻找CNN最佳超参数 3.1 超参数配置 3.2 消除季节性影响 3.3 问题建模 3.4 完整代码 代码环境: 假设现在已经定义好了网络模型,但需要对模型中的...

2018andoid混淆打包遇到Execution failed for task ':app:transformClassesAndResourcesWithProguardForRelease'.
在正式打包中,加上了 然后打包过程中,build中就报出了 Execution failed for task ‘:app:transformClassesAndResourcesWithProguardForRelease’. 然后就goodle了一下,最简单有效的回复,就是在 proguard-rules.pro 文件中加入 -ignorewarnings 但是在我这可...
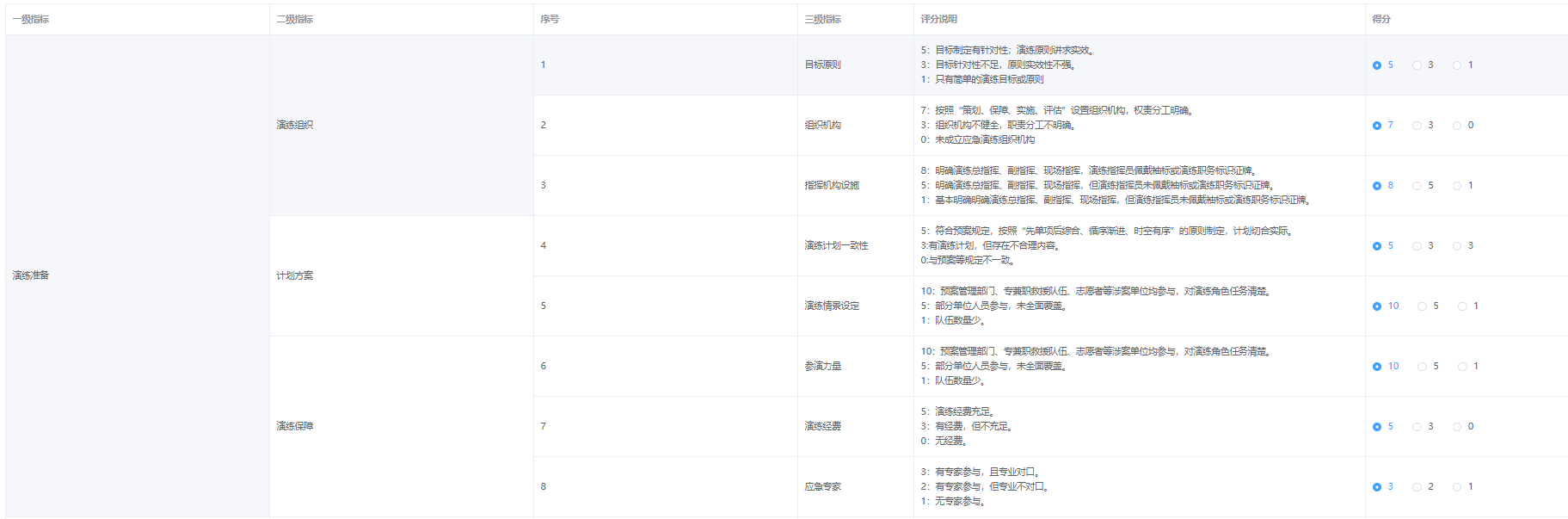
matlab与python的交互
一、从matlab调用python 1、先给出官方链接 进入链接后点示例,内容更丰富一些。《Python 库 — 示例》 2、简单说一下环境配置(下面的图片内容来自https://blog.csdn.net/jnulzl/article/details/51170859) 3、添加python环境变量以加载模块 如果是将当前文件夹加入到python搜索路径,modpath='';即可。...
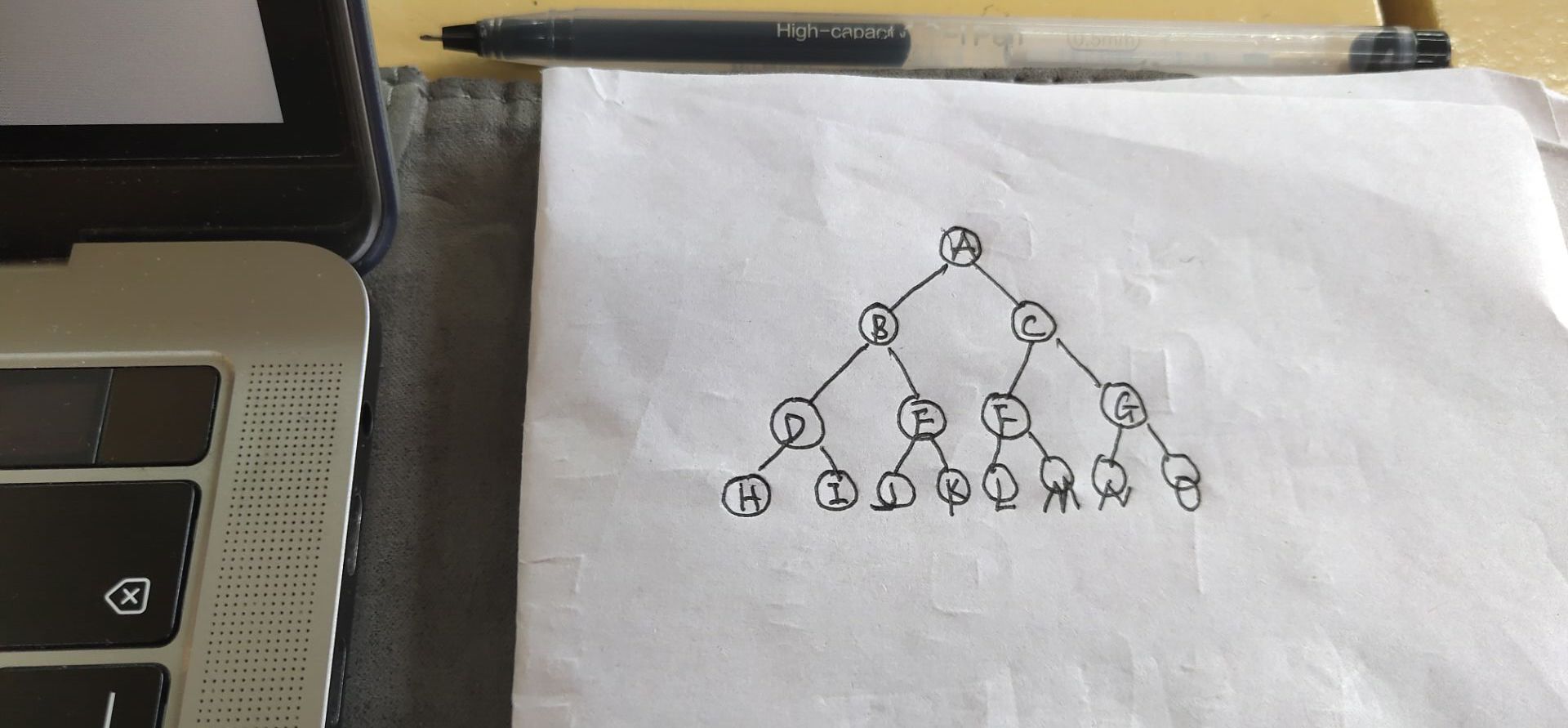
Java实现先序数组转换成后序数组
算法描述 满二叉树的先序序列存储在数组中,设计一个算法将其转换成后序遍历 满二叉树形状 先序和后序序列 先序序列:A B D H I E J K C F L M G N O 后序序列:H I D J K E B L M F N O G C A 算法思想 Transfer函数参数说明: pre就是先序序列数组,f1,l1分别是先序序列的第一个和最后一个元素; post就是后序序列数组,f2,l2分别...
猜你喜欢
markdown学习
欢迎随时骚扰:QQ为495470602 markdown学习 我们来学习一下markdown:什么是marjdown Markdown 是一种轻量级标记语言,创始人为约翰·格鲁伯。它允许人们“使用易读易写的纯文本格式编写文档,然后转换成有效的 XHTML 文档”。这种语言吸收了很多在电子邮件中已有的纯文本标记的特性。 优点:由于 Markdown 的轻量化、易...
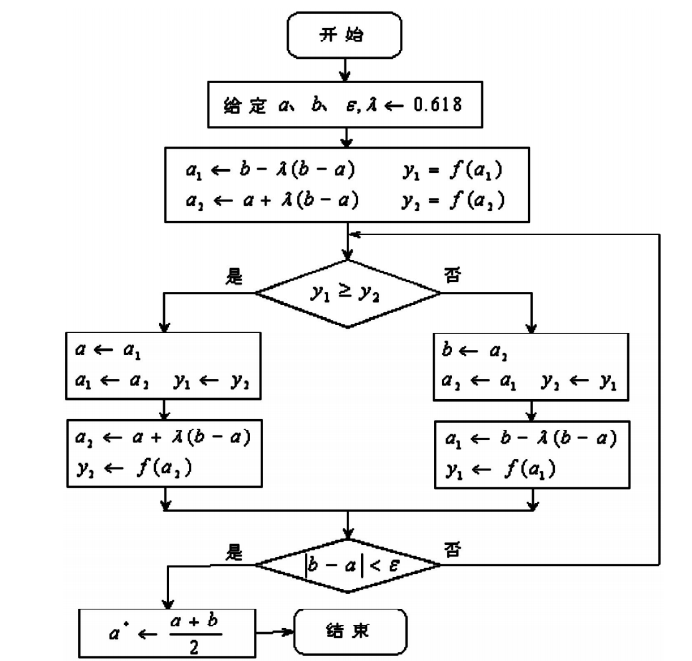
一维搜索-黄金分割法matlab实现
一维搜索-黄金分割法matlab实现 前言 1、黄金分割法 1.1 黄金分割法的定义 1.2 黄金分割法的搜索过程 2、黄金分割matlab实现 2.1 求f(x)=x^2-7*x+10的极值 2.2 解析法验算: 3.黄金分割脚本编码 4.附上powell法链接 前言 求解优化问题可以用解析解法和数值解法,在很多情况下,机械优化设计问题限制条件比较多,与之对应的数学描述也比较复杂,不便于甚至不可...
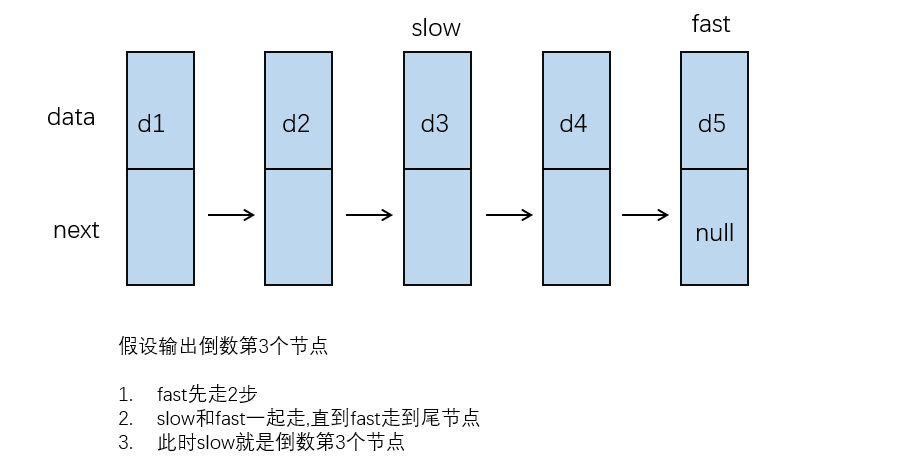
输入一个链表,输出该链表中倒数第k个结点
题目:输入一个链表,输出该链表中倒数第k个结点 关于这道题目,我首先想到的解决方法就是先求出链表的长度,然后返回第length-k个节点 但是,这么做会遍历两次链表,求链表的长度会遍历依次链表,返回第k个节点又会遍历一次链表 为了遍历一次链表,就返回倒数第k个节点,我们采用类似于 "尺子" 的方法 定义两个节点,让其中一个节点先走k-1步,然后两个节点一起走,直到第一个节点走到...

Python 利用百度文字识别 API 识别并提取图片中文字
Python 利用百度文字识别 API 识别并提取图片中文字 利用百度 AI 开发平台的 OCR 文字识别 API 识别并提取图片中的文字。首先需注册获取 API 调用的 ID 和 key,步骤如下: 打开百度AI开放平台,进入控制台中的文字识别应用(需要有百度账号)。 创建一个应用,并进入管理应用,记下 AppID, API Key, Secrect Key,调用 API需用到。 最后安装 py...