关于在windows上完成目标检测模型Centernet 以及自己数据的训练
关于在windows上完成目标检测模型Centernet 以及自己数据的训练
配置设置
最近在windows上复现了centernet模型,跑通了demo,并对自己的数据进行了训练,这里对过程进行记录。
配置:Windows 10,VS2015,Anaconda3.5.1,python3.6,torch1.1,Cuda10.0,Cudnn7.5。(VS2015和python3.6应该是对应torch1.1)可以直接下载whl文件进行本地安装。文中涉及到的所有额外文件,包括安装包,py文件,模型文件,需要替换的文件,我都将打包上传。
模型:https://github.com/xingyizhou/CenterNet
将源码下载之后保存到英文目录下,因为代码中的cv2包的cv2.imread()只能从英文路径中读取文件,类似于:
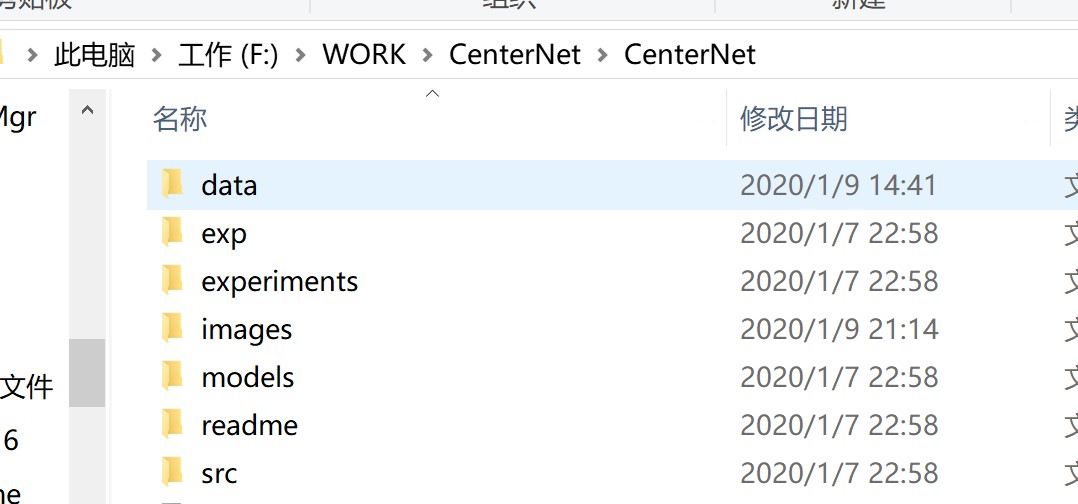
模型复现/demo.py的运行
1
在命令行窗口中进入对应的源码文件下,对requirements.txt内的包进行安装:
pip install -r requirements.txt
2 编译DCNv2文件
(1)下载 https://github.com/CharlesShang/DCNv2 内的源码,然后将DCNv2文件夹替换CenterNet\src\lib\models\networks\DCNv2文件夹
(2)修改 DCN文件2\src\cuda\dcn_v2_cuda.cu:
//extern THCState *state; // 注释该行
THCState *state = at::globalContext().lazyInitCUDA(); // 添加该行
(3)编译
进入 CenterNet\src\lib\models\networks\DCNv2文件夹下,
打开make.sh,在该路径下运行该文件内的指令:
python setup.py build develop
3 编译NMS
(1)在命令行窗口中:cd CenterNet\src\lib\external
然后注释setup.py文件中该行代码:
#extra_compile_args=["-Wno-cpp", “-Wno-unused-function”]
主要原因是因为源码是针对ubuntu系统的,在windows上不兼容
(2)运行
python setup.py build_ext –inplace
4 测试
测试上通常在cmd窗口上测试,如果想在编译器(Syder)上直接测试,需要把opt.py中的默认项更改为自己想要的,同时把task项改为—task:

在命令行中的输入则为:
python demo.py ctdet --demo …/images/ --load_model …/models/ctdet_coco_dla_2x.pth
其中载入的模型和参数需要提前下载
dla34-ba72cf86.pth 置于C:\Users\Liuzp.cache\torch\checkpoints内
ctdet_coco_dla_2x.pth 置于F:\WORK\CenterNet\CenterNet\models 内
训练自己的数据
1 准备数据集
如果数据集的文件为图片,建议先将图片制作为VOC格式的数据,然后再将其转换为COCO格式的数据。
(1)首先将所有的图片(不同类别、用于测试、训练的图片)都置于同一个文件夹下,在CenterNet\data\ 下新建一个文件夹,我这里命名为signal,然后包含两个文件夹:annotations 和images。其中images下放置图片,且图片尺寸保持一致。(不需要根据图片现有尺寸对代码中的resolution进行更改,否则报错)
(2)利用labelImg软件对图片进行标注,标注好类别,比如我这里有五个标签,对应五个类别,生成对应的xml文件,存到annotations文件夹下,方面调用
(3)将xml文件转化为json文件,只需将voc2coco2.py文件中的classes修改为自己的类别,并设置好训练文件与验证文件的比例train_ratio与val_ratio即可。运行voc2coco2.py,即可完成xml文件到coco格式数据的转换,并把生成的json文件放在annotations文件夹下,分别是
train_sig.json、test_sig.json、val_sig.json。
(4)运行calculatestd.py对images文件夹下的图片进行RGB通道上均值和方差的计算。
2 修改配置信息
(1)到src/lib/datasets/dataset目录下,复制coco.py文件,并重命名为signal.py
14行 numclasses=5
16 行 mean和std修改为1.4中的计算结果
22行 super(signal, self).init()
23行修改数据读取路径,读取CenterNet/data/signal文件下图片
self.data_dir = os.path.join(opt.data_dir, ‘signal’)
self.img_dir = os.path.join(self.data_dir, ‘images’)
25行起,修改读取的json文件名,并添加test情况下的读取:
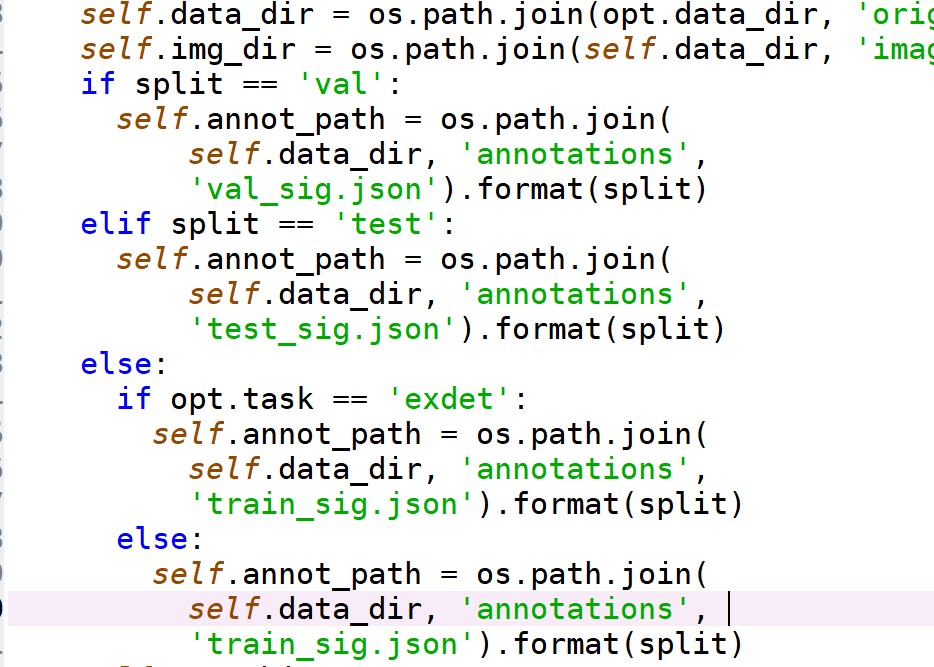
44行 修改class_name和valid_ids

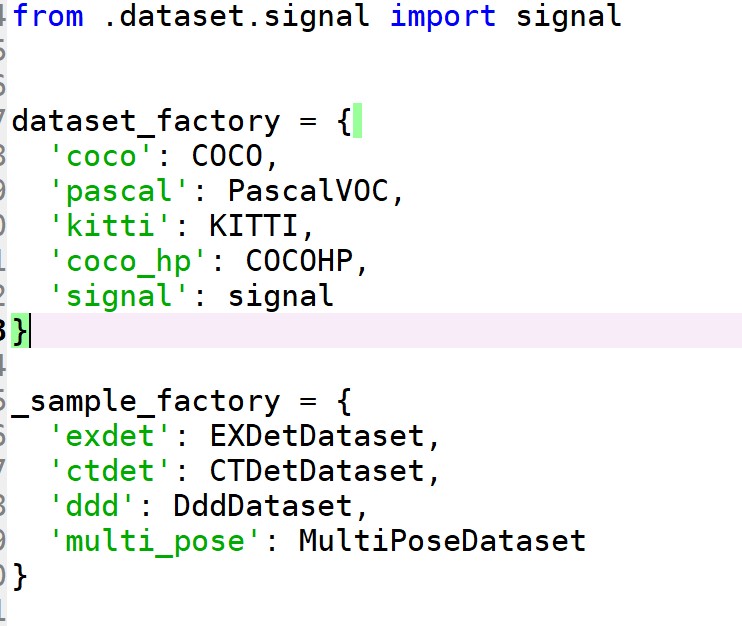
(2)修改将数据集加入src/lib/datasets/dataset_factory里面
(3)在/src/lib/opts.py文件中修改默认的dataset和exp_id(输出用)

第28行,修改load_model的默认路径:

这里可以直接载入model文件夹中下载好的ctdet_coco_dla_2x.pth
第39行,修改num_workers的default=0
修改ctdet任务使用的默认数据集为新添加的数据集,如下(修改分辨率,类别数,均值,标准差,数据集名字):
第336行,改下ctdet的init初始化信息。

(4)修改src/lib/utils/debugger.py文件(变成自己数据的类别和名字,前后数据集名字一定保持一致)
45行下方加入
elif num_classes == 5 or dataset == ‘signal’:
460行加入检测的类别数,我的为
signal_class_name =[‘LFM’,‘EQFM’,‘SFM’,‘FRANK’,‘BARKER’]
3 训练数据
在./src/目录下,运行main.py文件,
python main.py ctdet
如果出现out of memory, 可以调小opt.py中的batch_size
训练完成后会生成log和模型文件如下:
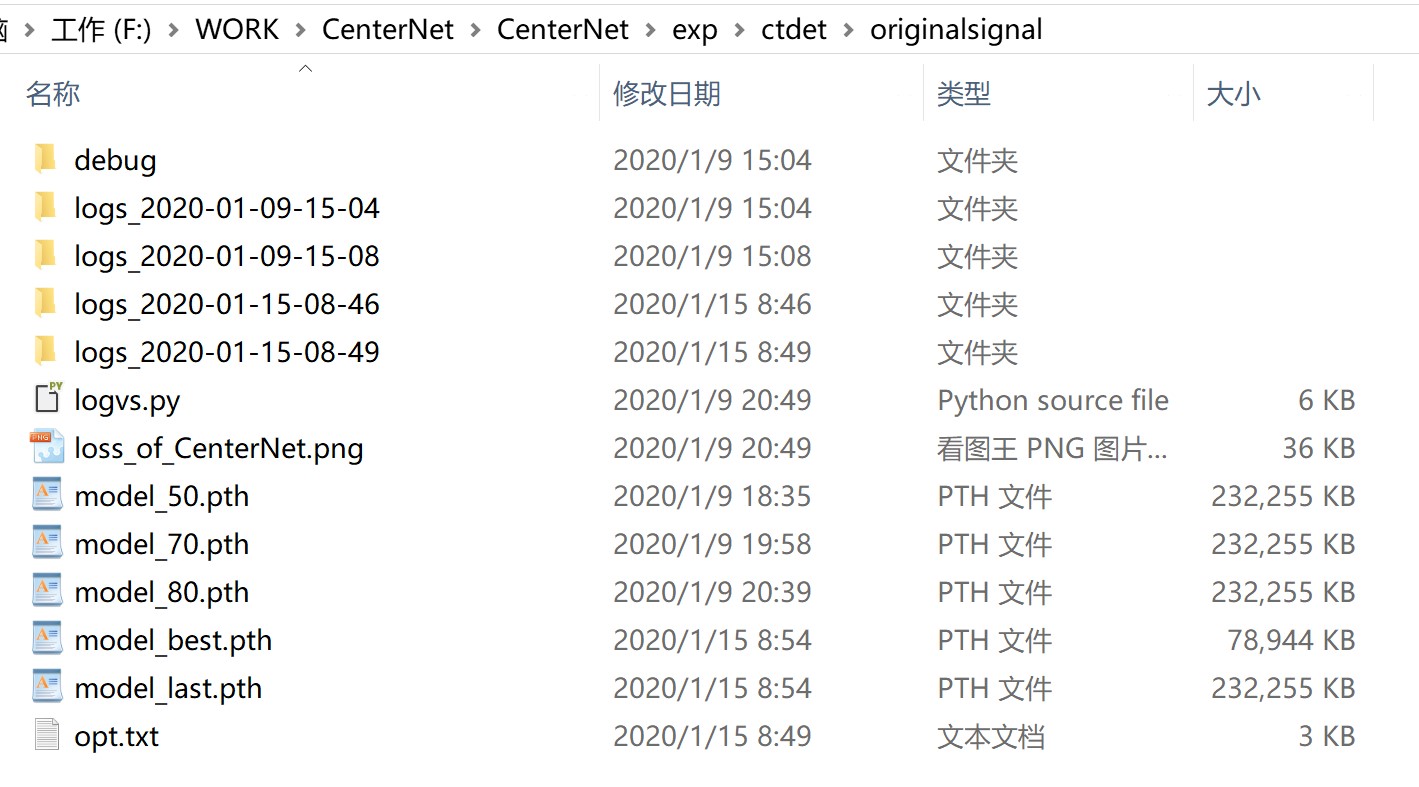
如果想继续训练,就更改opt.py中的load_model默认路径,载入想要继续训练的模型,然后执行
python main.py ctdet --resume
4 测试和验证模型
(1)测试模型
利用之前生成的test_sig.json文件与model_best进行测试,在\CenterNet\src\路径下运行test.py文件
python test.py --not_prefetch_test ctdet
--load_model ../CenterNet/exp/ctdet/originalsignal/model_best.pth
(2)验证模型
验证模型就是利用demo.py对images文件夹下的图片或视频进行测试
python demo.py ctdet --demo …/images/signal1.jpg
–load_model …/CenterNet/exp/ctdet/originalsignal/model_best.pth
带数据增强验证则加上
--flip_test (翻转测试)
--test_scales 0.5, 0.75, 1, 1.25, 1.5(可以在opt.py中对其默认设置进行更改)
如果需要保存你的预测结果,可以到/CenterNet/src/lib/detecors/ctdet.py下,在show_results函数中的末尾加入这句:
debugger.save_all_imgs(path='/CenterNet-master/outputs', genID=True)
有什么问题大家可以关注我并留言,我会给大家回复
上传的资源还在审核中,通过审核后我会在评论中给出下载链接
智能推荐

windows 训练、微调caffenet 训练测试自己的数据
下载caffeNet模型 下载的caffe-master文件中,/models/bvlc_reference_caffenet 文件夹不包含bvlc_reference_caffenet.caffemodel,下载地址:http://dl.caffe.berkeleyvision.org/bvlc_reference_caffenet.caffemodel 也可以用脚本方式下载。 &nb...

目标检测(Google object_detection) API 上训练自己的数据集
应公司要求,利用谷歌最近开源的Google object_detection API对公司收集的数据集进行训练,并检测训练效果。通过一两天的研究以及维持四天的训练(GTX 1060 6GB),终于成功的在自己数据集上训练的任务。测试效果感觉还行,虽没有达到谷歌官方公布的数据集上跑的识别效果,但是识别率也还过得去,这主要是因为数据集没有官方做的那么规范。下图为本人挑选的一张识别率较好的图...

(绝对详细)CenterNet训练自己的数据(pytorch0.4.1)
我的任务是在行人头肩数据上训练并测试centernet网络,先证明一下我是真的训练了哈,这是用centernet检测的一张结果(训练了10个epochs的结果,大家放心使用,网络功能还是很强大的): 我参考的这篇博客,对我自己的实验帮助很大:https://blog.csdn.net/weixin_42634342/article/details/97756458 论文作者代码:https://g...

CORDIC arithmetic
传统CORDIC算法code Verilog代码: 时钟为50Mhz; 输出设置均设置为有符号数,主要是因为计算CORDIC算法时,需要判断Z通道的符号,来得到迭代过程中旋转方向。 然后根据缩放因子和arctan 2^-n 的预定义并乘以2^16 来进行后续计算,根据迭代方程写出代码;最后将(0度到90度)中正弦值与余弦值来扩大至(0度至360度)的正弦值与余弦值。 编写的tb文件如下: 最终使用...
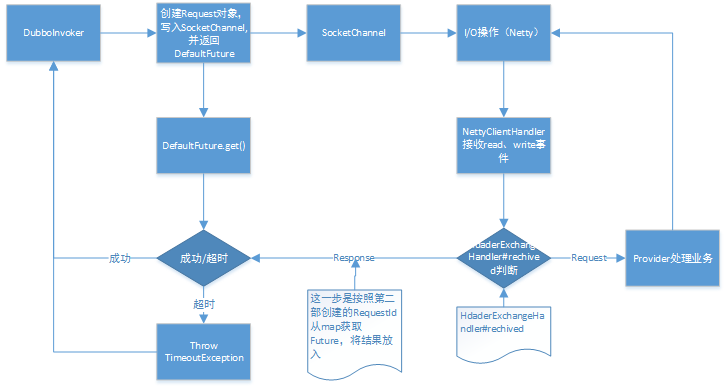
dubbo源码解析-线程通讯原理
本来想通过Debug从头屡,发现意义不大,还是写点主通讯流程吧 本文基于JDK1.8;dubbo2.7.5 线程通讯原理 解释总体流程: DubboInvoker#doInvoker(Invocation)发起request,进入HeaderExchangeChannel 初始化Request对象(Dubbo自己封装的),初始化DefaultFuture将Request、channel放入,并记录...
猜你喜欢

使用Intellij Idea+Gradle 搭建Java 本地开发环境
Java 本地开发环境搭建 项目搭建采用技术栈为:Spring+Spring MVC+Hibernate+Jsp+Gradle+tomcat+mysql5.6 搭建环境文档目录结构说明: 使用Intellj Idea 搭建项目过程详解 项目各配置文件讲解及部署 各层包功能讲解&项目搭建完毕最终效果演示图 项目中重要代码讲解 5.配置tomcat 运行环境 6.webapp文件夹下分层详解 ...
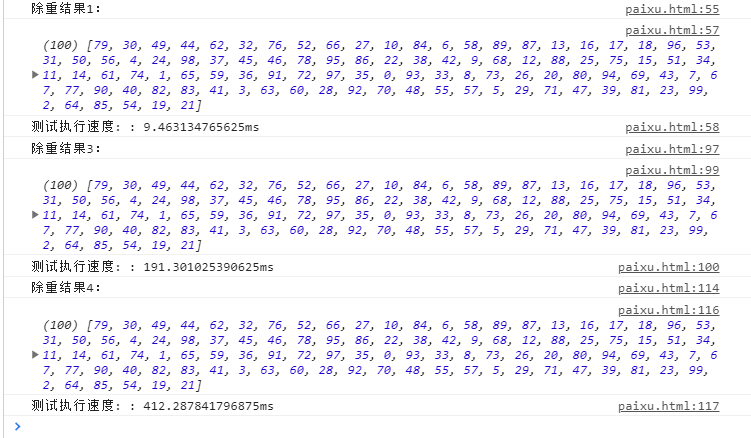
js中array数组除重最快的方式(100万数据量下测试)
模拟100万数据 测试1 for循环 + in 运算符 (不是 for…in 循环) 测试2 双层for循环 (太慢了) while …同理。 测试3 for循环 + arr.indexof()判断 测试4 for…in循环 + in 运算符 测试结果...
轻量级java服务器undertow
项目需求 服务器端项目是用mina写的传统socket,准备升级到支持websocket接入。 为什么采用undertow 1、Undertow 是基于 NIO 的高性能 Web 嵌入式服务器,并且支持websocket(这个很重要,只要把undertow集成到项目中,用undertow启用websokcet,然后把原来的socket切换到websocket。) 2、轻量级web服务器:多么轻量级...
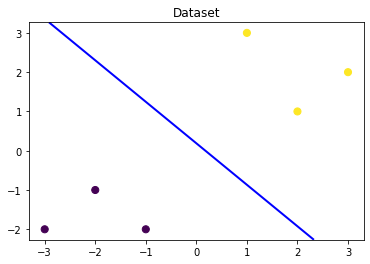
Task01:基于逻辑回归的分类预测
逻辑回归模型的优劣势: 优点:实现简单,易于理解和实现;计算代价不高,速度很快,存储资源低; 缺点:容易欠拟合,分类精度可能不高 https://zhuanlan.zhihu.com/p/74874291 与 SVM 相同点 都是分类算法,本质上都是在找最佳分类超平面; 都是监督学习算法; 都是判别式模型,判别模型不关心数据是怎么生成的,它只关心数据之间的差别,然后用差别来简单对给定的一个数据进行...
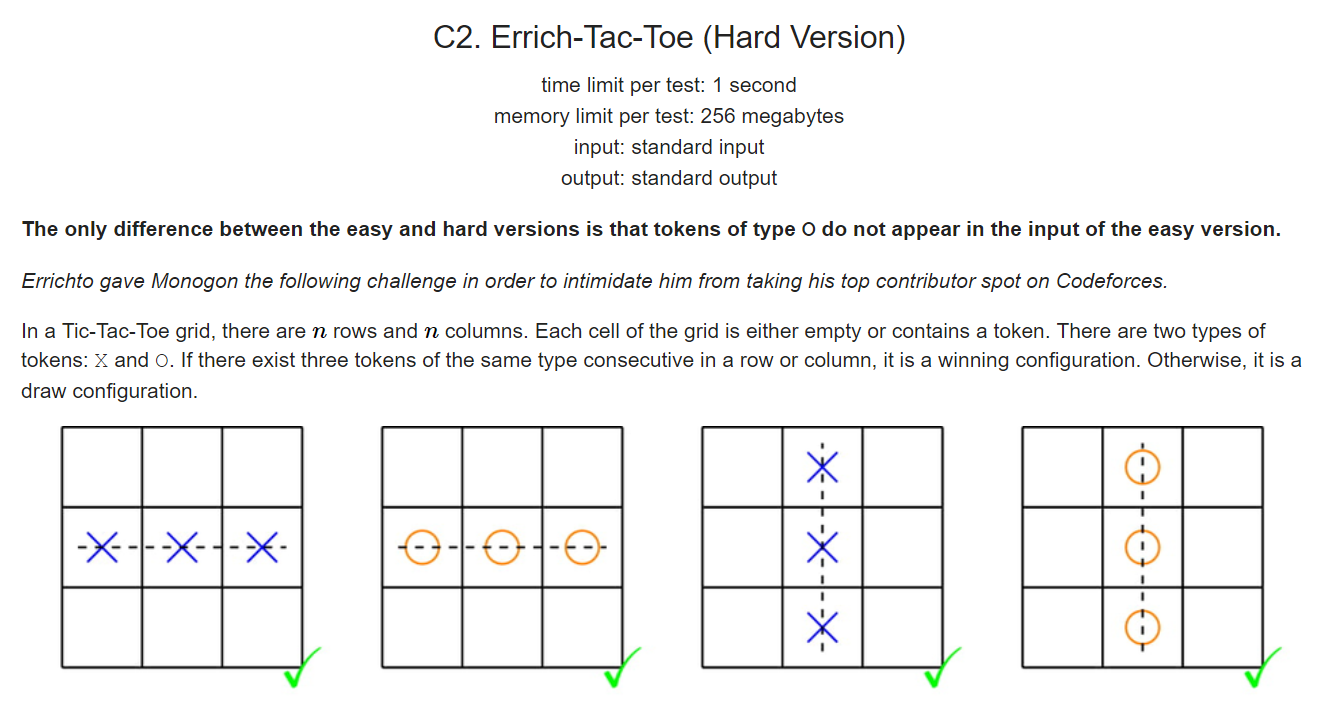
Codeforces Global Round 12 C2. Errich-Tac-Toe (Hard Version)(思维)
C2. Errich-Tac-Toe (Hard Version) 题意:给一个矩阵,里面有 k 个 'X' 或 'O' 标记,现在要修改不超过 k / 3 个标记('X'改成'O','O'改成'X'),使得矩阵中没有三个连续的相同的标记 思路:对两种不同的标记分别修改(i + j)% 3 == opx,(i + j) % 3 == opo 的位置,前提是修改的个数要少于总标记数的三分之一,所以枚...