高性能 Go 服务的内存优化(译)
作者:达菲格
来源:简书
原文地址: Allocation Efficiency in High-Performance Go Services, 没有原模原样的翻译, 但不影响理解。
关于工具
我们的第一个建议就是: 不要过早优化。Go 提供了很棒的性能调优工具可以直接指出代码上哪里消耗了大量内存。没必要重复造轮子,建议读者阅读下 Go 官方博客上的这篇很赞的文章;里面会一步步教你使用 pprof 对 CPU 和内存进行调优。在 Segment 我们也是用这些工具去找到项目的性能瓶颈的。
用数据来驱动优化。
逃逸分析
Go 可以自动的管理内存,这帮我们避免了大量潜在 bug,但它并没有将程序员彻底的从内存分配的事情上解脱出来。因为 Go 没有提供直接操作内存的方式,所以开发者必须要搞懂其内部机制,这样才能将收益最大化。
如果读了这篇文章后,你只能记住一点,那请记住这个:栈分配廉价,堆分配昂贵。现在让我们深入讲述下这是什么意思。
Go 有两个地方可以分配内存:一个全局堆空间用来动态分配内存,另一个是每个 goroutine 都有的自身栈空间。
Go 更倾向于在栈空间上分配内存 —— 一个 Go 程序大部分的内存分配都是在栈空间上的。它的代价很低,因为只需要两个 CPU 指令:一个是把数据 push 到栈空间上以完成分配,另一个是从栈空间上释放。
不幸的是, 不是所有的内存都可以在栈空间上分配的。栈空间分配要求一个变量的生命周期和内存足迹能在编译时确定。
否则就需要在运行时在堆空间上进行动态分配。
malloc 必须找到一块足够大的内存来存放新的变量数据。后续释放时,垃圾回收器扫描堆空间寻找不再被使用的对象。
不用多说,这明显要比只需两个指令的栈分配更加昂贵。
译者注: 内存足迹, 代表和一个变量相关的所有内存块。
比如一个 struct 中含有成员 *int, 那么这个 *int 所指向的内存块属于该 struct 的足迹。
编译器使用逃逸分析的技术来在这两者间做选择。基本的思路就是在编译时做垃圾回收的工作。
编译器会追踪变量在代码块上的作用域。变量会携带有一组校验数据,用来证明它的整个生命周期是否在运行时完全可知。如果变量通过了这些校验,它就可以在栈上分配。否则就说它 逃逸 了,必须在堆上分配。
逃逸分析的机制,并没有在 Go 语言官方说明上阐述。对 Go 程序员来说,学习这些规则最有效的方式就是凭经验。编译命令 go build -gcflags '-m' 会让编译器在编译时输出逃逸分析的结果。
让我们来看一个例子:
1package main
2
3import "fmt"
4
5func main() {
6 x := 42
7 fmt.Println(x)
8}
1$ go build -gcflags '-m' ./main.go
2# command-line-arguments
3./main.go:7: x escapes to heap
4./main.go:7: main ... argument does not escape
我们看到 x escapes to heap , 表示它会在运行时在堆空间上动态分配。
这个例子让人有些费解,直觉上,很明显变量 x 并没有逃出 main() 函数之外。
编译器没有说明它为什么认为这个变量逃逸了。为得到更详细的内容,多传几个 -m 参数给编译器,会打印出更详细的内容。
1$ go build -gcflags '-m -m' ./main.go
2# command-line-arguments
3./main.go:5: cannot inline main: non-leaf function
4./main.go:7: x escapes to heap
5./main.go:7: from ... argument (arg to ...) at ./main.go:7
6./main.go:7: from *(... argument) (indirection) at ./main.go:7
7./main.go:7: from ... argument (passed to call[argument content escapes]) at ./main.go:7
8./main.go:7: main ... argument does not escape
是的,上面显示了,变量 x 之所以逃逸了,是因为它被传入了一个逃逸的函数内。
这个机制乍看上去有些难以捉摸,但多用几次这个工具后,就能搞明白这其中的规律了。长话短说,下面是一些我们找到的,能引起变量逃逸到堆上的典型情况:
1、发送指针或带有指针的值到 channel 中。在编译时,是没有办法知道哪个 goroutine 会在 channel 上接收数据。所以编译器没法知道变量什么时候才会被释放。
2、在一个切片上存储指针或带指针的值。一个典型的例子就是 []*string 。这会导致切片的内容逃逸。尽管其后面的数组可能是在栈上分配的,但其引用的值一定是在堆上。
3、slice 的背后数组被重新分配了,因为 append 时可能会超出其容量( cap )。slice 初始化的地方在编译时是可以知道的,它最开始会在栈上分配。如果切片背后的存储要基于运行时的数据进行扩充,就会在堆上分配。
4、在 interface 类型上调用方法。在 interface 类型上调用方法都是动态调度的 —— 方法的真正实现只能在运行时知道。想像一个 io.Reader 类型的变量 r , 调用 r.Read(b) 会使得 r 的值和切片 b 的背后存储都逃逸掉,所以会在堆上分配。
以我们的经验,这四点是 Go 程序中最常见的导致堆分配的原因。幸运的是,是有解决办法的!下面我们深入几个具体例子说明,如何定位线上系统的内存性能问题。
关于指针
一个经验是:指针指向的数据都是在堆上分配的。因此,在程序中减少指针的运用可以减少堆分配。这不是绝对的,但是我们发现这是在实际问题中最常见的问题。
一般情况下我们会这样认为:“值的拷贝是昂贵的,所以用一个指针来代替。”
但是,在很多情况下,直接的值拷贝要比使用指针廉价的多。你可能要问为什么。
1、编译器会在解除指针时做检查。目的是在指针是 nil 的情况下直接 panic() 以避免内存泄露。这就必须在运行时执行更多的代码。如果数据是按值传递的,那就不需要做这些了,它不可能是 nil
2、指针通常有糟糕的局部引用。一个函数内部的所有值都会在栈空间上分配。局部引用是编写高效代码的重要环节。它会使得变量数据在 CPU Cache(cpu 的一级二级缓存) 中的热度更高,进而减少指令预取时 Cache 不命中的的几率。
3、在 Cache 层拷贝一堆对象,可粗略地认为和拷贝一个指针效率是一样的。CPU 在各 Cache 层和主内存中以固定大小的 cache 进行内存移动。x86 机器上是 64 字节。而且,Go 使用了Duff’s device 技术来使得常规内存操作变得更高效。
指针应该主要被用来做映射数据的所有权和可变性的。实际项目中,用指针来避免拷贝的方式应该尽量少用。
不要掉进过早优化的陷阱。养成一个按值传递的习惯,只在需要的时候用指针传递。另一个好处就是可以较少 nil 带来的安全问题。
减少程序中指针的使用的另一个好处是,如果可以证明它里面没有指针,垃圾回收器会直接越过这块内存。例如,一块作为 []byte 背后存储的堆上内存,是不需要进行扫描的。对于那些不包含指针的数组和 struct 数据类型也是一样的。
译者注: 垃圾回收器回收一个变量时,要检查该类型里是否有指针。
如果有,要检查指针所指向的内存是否可被回收,进而才能决定这个变量能否被回收。如此递归下去。
如果被回收的变量里面没有指针, 就不需要进去递归扫描了,直接回收掉就行。
减少指针的使用不仅可以降低垃圾回收的工作量,它会产生对 cache 更加友好的代码。读内存是要把数据从主内存读到 CPU 的 cache 中。
Cache 的空间是有限的,所以其他的数据必须被抹掉,好腾出空间。
被抹掉的数据很可能程序的另外一部分相关。
由此产生的 cache 抖动会引起线上服务的一些意外的和突然的抖动。
还是关于指针
减少指针的使用就意味着要深入我们自定义的数据类型。我们的一个服务,用带有一组数据结构的循环 buffer 构建了一个失败操作的队列好做重试;它大致是这个样子:
1type retryQueue struct {
2 buckets [][]retryItem // each bucket represents a 1 second interval
3 currentTime time.Time
4 currentOffset int
5}
6
7type retryItem struct {
8 id ksuid.KSUID // ID of the item to retry
9 time time.Time // exact time at which the item has to be retried
10}
buckets 中外面的数组大小是固定的, 但是 []retryItem 中 item 的数量是在运行时变化的。重试次数越多, 切片增长的越大。
挖掘一下 retryItem 的具体实现,我们发现 KSUID 是 [20]byte 的别名, 里面没有指针,所以可以排除。 currentOffset 是一个 int 类型, 也是固定长度的,故也可排除。接下来,看一下 time.Time 的实现:
1type Time struct {
2 sec int64
3 nsec int32
4 loc *Location // pointer to the time zone structure
5}
time.Time 的结构体中包含了一个指针成员 loc 。在 retryItem 中使用它会导致 GC 每次经过堆上的这块区域时。
都要去追踪到结构体里面的指针。
我们发现,这个案例很典型。 在正常运行期间失败情况很少。 只有少量内存用于存储重试操作。 当失败突然飙升时,重试队列中的对象数量每秒增长好几千,从而对垃圾回收器增加很多压力。
在这种情况下, time.Time 中的时区信息不是必要的。这些保存在内存中的时间截从来不会被序列化。所以可以重写这个数据结构来避免这种情况:
1type retryItem struct {
2 id ksuid.KSUID
3 nsec uint32
4 sec int64
5}
6
7func (item *retryItem) time() time.Time {
8 return time.Unix(item.sec, int64(item.nsec))
9}
10
11func makeRetryItem(id ksuid.KSUID, time time.Time) retryItem {
12 return retryItem{
13 id: id,
14 nsec: uint32(time.Nanosecond()),
15 sec: time.Unix(),
16}
注意现在的 retryItem 不包含任何指针。这大大降低了 gc 压力,因为 retryItem 的整个足迹都可以在编译时知道。
传递 Slice
切片是造成低效内存分配行为的狂热区域。除非切片的大小在编译时就能知道,否则切片背后的数组(map也一样)会在堆上分配。让我们来讲几个方法,让切片在栈上分配而不是在堆上。
一个重度依赖于 MySQL 的项目。整个项目的性能严重依赖 MySQL 客户端驱动的性能。
使用 pprof 对内存分配进行分析后,我们发现 MySQL driver 中序列化 time.Time 的那段代码非常低效。
性能分析器显示了堆上分配的内存有很大比例都是用来序列化 time.Time 的,所以才导致了 MySQL driver 低效。
go tool pprof 结果
这段低效的代码就是调用了 time.Time 的 Format() 方法, 它返回一个 string 。等等,我们不是在讨论切片嘛?好吧,根据 Go 官方的博客,一个 string 实际就是一个只读的 []byte ,只是语言上在语法上多了点支持。在内存分配上规则都是一样的。
分析结果告诉我们 12.38% 的内存分
配都是 Format() 引起的, Format() 都做了什么?
它表示使用标准库还有更高效的方式来达到通样的效果。但是 Format() 用起来很方便,使用 AppendFormat() 在内存分配上更友好。剖析下 time 包的源码,我们发现里面都是使用 AppendFormat() 而不是 Format() 。这更说明了 AppendFormat() 可以带来更高的性能。
实际上, Format() 函数只是对 AppendFormat() 的一层封装。
1func (t Time) Format(layout string) string {
2 const bufSize = 64
3 var b []byte
4 max := len(layout) + 10
5 if max < bufSize {
6 var buf [bufSize]byte
7 b = buf[:0]
8 } else {
9 b = make([]byte, 0, max)
10 }
11 b = t.AppendFormat(b, layout)
12 return string(b)
13}
更重要的是, AppendFormat() 给程序员留了更多的优化空间。它需要传入一个切片进行存储,而不是直接返回一个 string 。使用 AppendFormat() 代替 Format() 可以用固定大小的内存空间来完成同样的事,而且这些操作是在栈空间完成的。
Interface 类型
众所周知的,在 Interface 类型上调用方法要比直接在 Struct 上调用方法效率低。在 interface 类型上调用方法是动态调度的。这就极大的限制了编译器确定运行时代码执行方式的能力。到目前为止我们已经大量的讨论了,调整代码好让编译器能在编译时更好的理解你的代码行为。但 interface 类型会让这一切都白做。
不幸的是,interface 类型还是一个非常有用的抽象方式 —— 它能让我们写出扩展性更高的代码。interface 的一个普遍应用场景是标准库里的 hash 包中的哈希函数。 hash 包定义了通用的接口,然后提供了几个具体的实现。让我们看几个例子:
1package main
2
3import (
4 "fmt"
5 "hash/fnv"
6)
7
8func hashIt(in string) uint64 {
9 h := fnv.New64a()
10 h.Write([]byte(in))
11 out := h.Sum64()
12 return out
13}
14
15func main() {
16 s := "hello"
17 fmt.Printf("The FNV64a hash of '%v' is '%v'\n", s, hashIt(s))
18}
编译上段代码,加上逃逸分析参数,会有以下输出:
1./foo1.go:9:17: inlining call to fnv.New64a
2./foo1.go:10:16: ([]byte)(in) escapes to heap
3./foo1.go:9:17: hash.Hash64(&fnv.s·2) escapes to heap
4./foo1.go:9:17: &fnv.s·2 escapes to heap
5./foo1.go:9:17: moved to heap: fnv.s·2
6./foo1.go:8:24: hashIt in does not escape
7./foo1.go:17:13: s escapes to heap
8./foo1.go:17:59: hashIt(s) escapes to heap
9./foo1.go:17:12: main ... argument does not escape
这说明了, hash 对象,输入字符串,和 []byte 都会逃逸到堆上。
人肉眼看上去很明显这些数据根本没有逃逸,但是 interface 类型限制了编译器的功能。
没有办法不进入 hash 的 interface 结构而安全的调用其具体实现。
所以碰到这种情况,除非自己手动实现一个不使用 interface 的库,没什么好办法。
一个小把戏
最后一点要比实际情况更搞笑。但是,它能让我们对编译器的逃逸分析机制有更深刻的理解。当通过阅读标准库源码来解决性能问题时,我们看到了下面这样的代码:
1// noescape hides a pointer from escape analysis. noescape is
2// the identity function but escape analysis doesn't think the
3// output depends on the input. noescape is inlined and currently
4// compiles down to zero instructions.
5// USE CAREFULLY!
6//go:nosplit
7func noescape(p unsafe.Pointer) unsafe.Pointer {
8 x := uintptr(p)
9 return unsafe.Pointer(x ^ 0)
10}
这个函数会把指针参数从编译器的逃逸分析中隐藏掉。这意味着什么呢?让我们来举个例子看下。
1package main
2
3import (
4 "unsafe"
5)
6
7type Foo struct {
8 S *string
9}
10
11func (f *Foo) String() string {
12 return *f.S
13}
14
15type FooTrick struct {
16 S unsafe.Pointer
17}
18
19func (f *FooTrick) String() string {
20 return *(*string)(f.S)
21}
22
23func NewFoo(s string) Foo {
24 return Foo{S: &s}
25}
26
27func NewFooTrick(s string) FooTrick {
28 return FooTrick{S: noescape(unsafe.Pointer(&s))}
29}
30
31func noescape(p unsafe.Pointer) unsafe.Pointer {
32 x := uintptr(p)
33 return unsafe.Pointer(x ^ 0)
34}
35
36func main() {
37 s := "hello"
38 f1 := NewFoo(s)
39 f2 := NewFooTrick(s)
40 s1 := f1.String()
41 s2 := f2.String()
42}
上段代码对同样的功能有两种实现:他们包含一个 string ,然后用 String() 函数返回这个字符串。
但是编译器的逃逸分析输出表名了 FooTrick 版本没有逃逸。
1./foo3.go:24:16: &s escapes to heap
2./foo3.go:23:23: moved to heap: s
3./foo3.go:27:28: NewFooTrick s does not escape
4./foo3.go:28:45: NewFooTrick &s does not escape
5./foo3.go:31:33: noescape p does not escape
6./foo3.go:38:14: main &s does not escape
7./foo3.go:39:19: main &s does not escape
8./foo3.go:40:17: main f1 does not escape
9./foo3.go:41:17: main f2 does not escape
关键在这两行
1./foo3.go:24:16: &s escapes to heap
2./foo3.go:23:23: moved to heap: s
编译器识别出了 NewFoo() 函数引用了字符串并将其存储在结构体中,导致了逃逸。但是, NewFooTrick() 却没有这样的输出。如果把调用 noescape() 的代码删掉,就会出现逃逸的情况。
到底发生了什么?
1func noescape(p unsafe.Pointer) unsafe.Pointer {
2 x := uintptr(p)
3 return unsafe.Pointer(x ^ 0)
4}
noescape() 函数遮蔽了输入和输出的依赖关系。编译器不认为 p 会通过 x 逃逸, 因为 uintptr() 产生的引用是编译器无法理解的。
内置的 uintptr 类型让人相信这是一个真正的指针类型,但是在编译器层面,它只是一个足够存储一个 point 的 int 类型。代码的最后一行返回 unsafe.Pointer 也是一个 int。
noescape() 在 runtime 包中使用 unsafe.Pointer 的地方被大量使用。如果作者清楚被 unsafe.Pointer 引用的数据肯定不会被逃逸,但编译器却不知道的情况下,这是很有用的。
但是请记住,我们强烈不建议使用这种技术。这就是为什么包的名字叫做 unsafe 而且源码中包含了 USE CAREFULLY! 注释的原因。
小贴士
1、不要过早优化,用数据来驱动我们的优化工作。
2、栈空间分配是廉价的,堆空间分配是昂贵的。
3、了解逃逸机制可以让我们写出更高效的代码。
4、指针的使用会导致栈分配更不可行。
5、找到在低效代码块中提供分配控制的 api。
6、在调用频繁的地方慎用 interface。
版权申明:内容来源网络,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。谢谢。
Golang语言社区
ID:Golangweb
www.GolangWeb.com
游戏服务器架构丨分布式技术丨大数据丨游戏算法学习
智能推荐

前端高性能网站-性能优化
首先我们要知道性能到底是什么意思,下面是百度百科的答案! so下面我们就按照性能影响力去介绍,也是我看《高性能网站建设指南》的一份笔记吧! 1、减少http请求【文件大小、文件数量、请求路程】 1、图片地图(图片导航、多个导航需要请求多次http,优化方式之一就是使用图片地图)【感觉有点确定、css3不会淘汰??】 图片地图要用到map和area标签 map标签用于客户端的图片映射;area标签指...
Vue——el-option下拉框绑定
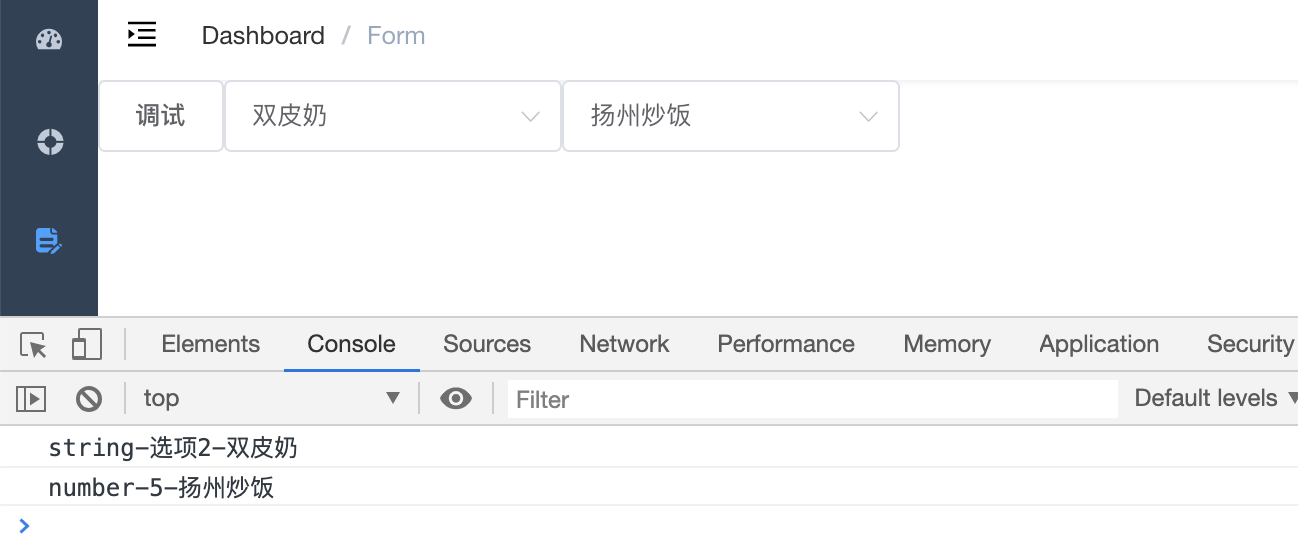
1、正常使用v-for 进行遍历 下拉框内容,如果需要增加一个自定义的值,则加一个el-option el-option用法: 参数 说明 类型 可选值 默认值 value 选项的值 string/number/object — — label 选项的标签,若不设置则默认与 value 相同 string/number — — disabled 是否...
关于git与gitee的使用
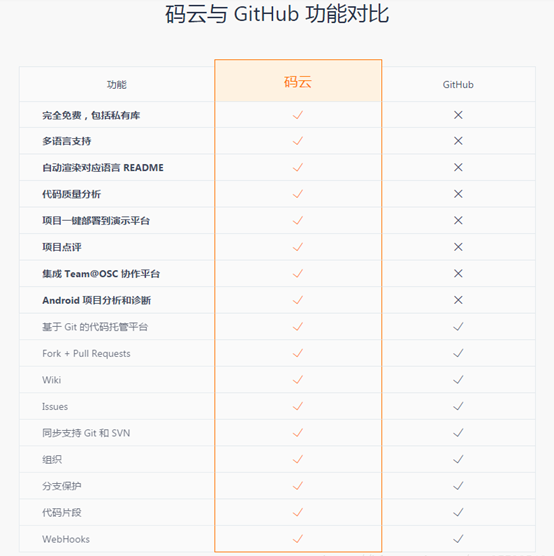
关于在自己git与gitee代码托管平台的使用记录 (关于安装git和gitee就不在此唠叨了,网上一堆讲解(感兴趣的请看码云gitee入门)这里主要记录自己在使用过程中的遇到并解决的问题) 1.创建本地代码仓库 1)、在本地一个盘下新建一个文件夹,当作本地代码仓库,也就是说希望之后这个文件夹里的文件的改动都能被git进行管理。 2)初始一个本地仓库,之后可以看到在该文件夹下多了一个.git文件夹...
数据结构(C/C++)课程阶段总结(七)
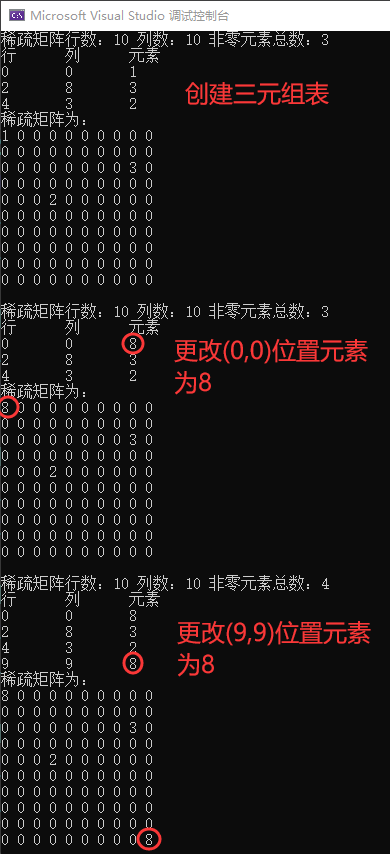
目录 写在前面 稀疏矩阵抽象数据类型定义 基本操作的实现方法 稀疏矩阵对应三元组表的创建 改变矩阵元素值 获取矩阵元素值 输出矩阵 具体实现 运行结果 总结 写在前面 课程采用教材《数据结构(C语言版)》严蔚敏,吴伟民,清华大学出版社。 本系列博文用于自我学习总结和期末复习使用,同时也希望能够帮助到有需要的同学。如果有知识性的错误,麻烦评论指出。 本次实验实现稀疏矩阵的三元组顺序存储表示。 稀疏矩...

Day 10 ajax介绍,初步了解
Day 10 ajax介绍,初步了解 一、ajax介绍 AJAX即“Asynchronous JavaScript and XML”(异步的JavaScript与XML技术) 传统的Web应用允许用户端填写表单(form),当提交表单时就向网页服务器发送一个请求。服务器接收并处理传来的表单,然后送回一个新的网页,但这个做法浪费了许多带宽,因为在前后两个页面中的大部分HTML...
猜你喜欢
Typora基础教程
目录 Typora基础教程 Markdown简介 Typora安装教程 mac安装教程 Windows安装教程 Markdown基本语法教程 Markdown的常用格式 Markdown的空格、换行与段落 Typora数学公式教程 Typora基础教程 Markdown简介 什么是Markdown: Markdown是一种轻量级的标记语言,用户通过一系列符号,如:#*[+$`,来表示粗体、斜体、超...

访问github无css样式的解决方案
1、浏览器右键查看加载失败的css文件来源 加载失败此处文件名会为红色 复制域名assets-cdn.github.com 2、查询css文件所在ip 打开https://www.ipaddress.com右上角输入框粘贴之前的css所在域名,点击搜索,记下搜索结果的ip 3、修改host文件 mac下: 打开finder(访达),点击右上角 前往-前往文件夹 输入/private,右键显示简介,...

Eclipse用maven构建SSM框架遇到的问题及解决方法
听说Maven很好用,刚刚好实验了Spring+Mvc企业应用实践的一个小项目,所以就拿它来练手了,用maven来重构它。 开发环境如下: Eclipse:Eclipse Project Release Notes 4.7 (Oxygen) JDK:JDK1.8.0_144 Maven:apache-maven-3.5.4 Tomcat:Tomcat 9 环境的配置就不多说了,其实只要有目录就行,...
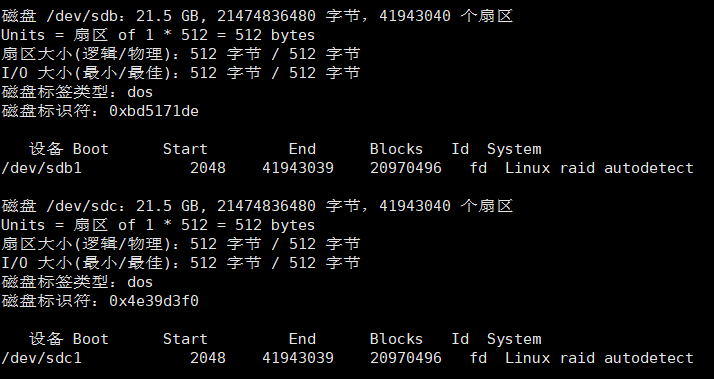
Raid磁盘管理
文章目录 前言 实验环境 实验操作步骤 RAID0 RAID1 RAID5 RAID6 RAID1+0 总结 前言 RAID称为独立冗余磁盘阵列,简单的说就是raid把多块独立的物理硬盘按不同的方式进行组合,形成硬盘组,从而提供比单个硬盘具有更高的存储性能和存储容量的数据备份技术。 RAID分不同的等级,不同的RAID在数据可靠性上做了不同的权衡。在实际应用中可以根据需求关系来确定使用哪个RAID...

常见排序算法总结——2、插入排序
常见排序方法 原创文章,转载请添加本网页链接 https://blog.csdn.net/qq_37334950/article/details/104378361 2、插入排序:将数组分为有序组(数组的第一个元素)和无序组(数组的第二个元素~最后一个元素),每次取出无序组的第一个元素,经过比较插入有序组的合适位置 举例: 初始数组:9 3 4 2 6 7 5 1 分组:(9)(3...