mysql的常用语句操作
文章目录
数据库的简介:
数据库(Database,DB)是按照数据结构来组织,存储和管理数据的仓库。
典型特征:数据的结构化、数据间的共享、减少数据的冗余度,数据的独立性。
关系型数据库:使用关系模型把数据组织到数据表(table)中。现实世界可以用数据来描述。
主流的关系型数据库产品:Oracle(Oracle)、DB2(IBM)、SQL Server(MS)、MySQL(Oracle)。
数据表:数据表是关系数据库的基本存储结构,二维数据表有行(Row),和列(Column)组成,也叫作记录(行)和字段(列)。
SQL(Structured Query Language):结构化查询语言
SQL是在关系数据库上执行数据操作、检索及维护所使用的标准语言,可以用来查询数据,操纵数据,定义数据,控制数据。
数据类型:
整型:
| 类型 | 字节 | 最小值 | 最大值 |
|---|---|---|---|
| 有符号/无符号 | 有符号/无符号 | ||
| TINYINT | 1 | -128 | 127 |
| 0 | 255 | ||
| SMALLINT | 2 | -32768 | 32767 |
| 0 | 65535 | ||
| MEDIUMINT | 3 | -8388608 | 8388607 |
| 0 | 16777215 | ||
| INT | 4 | -2147483648 | 2147483647 |
| 0 | 4294967295 | ||
| BIGINT | 8 | -9223372036854775808 | 9223372036854775807 |
| 0 | 18446744073709551615 |
浮点数类型和定点数类型;
| 类型 | 字节 | 负数的取值范围 | 非负数的取值范围 |
|---|---|---|---|
| Fioat | 4 | -3.402 823 466E+38~-1.175 494 351E-38 | 0和1.175 494 351E-38~ 3.402 823 466E+38 |
| Double | 8 | -1.797 693 134 862 315 7E+308 -2.255 073 858 507 201 4E -308 | 0和2.255 073 858 507 201 4E-308 ~1.797 693 134 862 315 7E+308 |
| Decimal(M,D) | M+2 | -1.797 693 134 862 315 7E+308~ -2.225 073 858 507 201 4E-308 | 0和2.225 073 858 507 201 4E-308~ 1.797 693 134 862 315 7E+308 |
日期与时间类型;
%Y:代表4位的年份
%y:代表2为的年份
%m:代表月, 格式为(01……12)
%c:代表月, 格式为(1……12)
%d:代表月份中的天数,格式为(00……31)
%e:代表月份中的天数, 格式为(0……31)
%H:代表小时,格式为(00……23)
%k:代表 小时,格式为(0……23)
%h: 代表小时,格式为(01……12)
%I: 代表小时,格式为(01……12)
%l :代表小时,格式为(1……12)
%i: 代表分钟, 格式为(00……59)
%r:代表 时间,格式为12 小时(hh:mm:ss [AP]M)
%T:代表 时间,格式为24 小时(hh:mm:ss)
%S:代表 秒,格式为(00……59)
%s:代表 秒,格式为(00……59)
| 数据类型 | 字节数 | 取值范围 | 日期格式 |
|---|---|---|---|
| Year | 1 | 1901~2155 | YYYY |
| Date | 4 | 1000-01-01~9999-12-3 | YYYY-MM-DD |
| Time | 3 | -8383:59:59~838:59:59 | HH:MM:DD |
| Datetime | 8 | 1000-01-01 00:00::00~9999-12-31 23:59:59 | YYYY-MM-DDHH:MM:SS |
| TIMESTAMP | 4 | 1970-01-01 00:00:01~2038-01-19 03:14:07 | YYYYMMDD HHMMSS |
//启动MySQL服务
//通过windows服务管理器启动MySQL
//查看MySQL是否启动
//通过cmd窗口输入命令:services.msc来查看
//通过DOS命令启动MySQL,
//必须以管理员身份运行:
//命令:启动:net start mysql
//停止:net stop mysql
//登录mysql;使用相关命令登录:
//Mysql -h hostname -u root -p;
//Mysql -h localhost -u root -p;
//Mysql -u root -p;
//创建数据库和查看数据库
Create database 数据库名称;
比如:
Create database zsj(数据库名称);
//查看所有数据库;
Show databasese;
查看某个数据库;(查看数据库的创建语句)
Show create database zsj;
将数据库zsj的数据库编码修改为gbk;代码如下
Alter database zsj default character set gbk collate gbk_bin;
删除数据库;
Drop database 数据库名称;
SQL语法分类
SQL可以分为:
数据定义语言(DDL):Data Definition Language
数据操纵语言(DML):Data Manipulation Language
事务控制语言(TCL):Transaction Control Language
数据查询语言(DQL):Data Query Language
数据控制语言(DCL):Data Control Language
数据定义语言(DDL):
数据表的基本操作;
创建数据表
Create table zsj1(
Id int(11) ,
Name varchar(20),
Grade float
);
建表之后添加约束;
Alter table zsj1 add constraint primary key (id);
在创建表时添加约束
Create table zsj1(
Id int(11),
Name char(20),
Primary key(id)
);
查看数据表;
Show tables;
查看数据库下的指定的某张表;(查看建表语句;)
Show create table zsj;
使用describe语句查看数据表;(查看表的结构)
Desc zsj1;
修改数据表;
1,修改表名;
Alter table zsj1 rename to zsj2;
Alter table 旧表名 rename [to] 新表名;
2,修改字段名;
Alter table 表名 change 旧字段名 新字段名 新数据类型;
Alter table grade change name username varchar(20);
3,修改字段的数据类型;
Alter table 表名 modify 字段名 数据类型;
Alter table zsj1 modify id int(20);
4,添加字段
Alter table 表名 add 新字段名 数据类型
【约束条件】【first|after 已存在字段名】
Alter table zsj1 add age int(10);
5,删除字段;
Alter table 表名 drop 字段名;
Alter table zsj1 drop age;
6,修改字段的排列位置;
Alter table 表名 modify 字段名1 数据类型 first|after 字段名2;
删除数据表;
Drop table 表名;
Drop table zsj1;
| 表的约束; | 说明 |
|---|---|
| Primary key | 主键约束用于唯一标识 |
| Foreign key | 外键约束 |
| Not null | 非空约束 |
| Unique | 唯一性约束 |
| default | 默认值约束 |
主键约束Create table t88(
Id int primary key,
Name char(5),
Gender char(2),
Birthday date
);
添加约束:Create table t3 (
Id int ,
Name char(5),
Gender char(2),
Birthday date
);
非空约束:
Create table t4 (
Id int primary key,
Name char(5)not null,
Gender char(2) ,
Birthday date
);
唯一约束:
Create table t5 (
Id int primary key,
Name char(5)not null,
Gender char(2) unique,
Birthday date
);
默认约束:Create table t6 (
Id int primary key,
Name char(5)not null,
Gender char(2) unique,
Score double default 60,
Birthday date
数据操纵语言DML(update,insert,delete)
添加数据;
为表中所有字段添加数据
1. insert 语句指定所有字段名;
insert into 表名(字段名1,字段名2,…..)values (值1,值2,…);
insert into zsj2(id,name,grade)values(1,’zhangsan’,99.5);
查看表中的数据
Select * from zsj2;
2,Insert语句中不指定字段名
由于insert语句中没有指定字段名,所以添加的值必须与字段在表中定义的顺序相同。
Insert into 表名 values(值1,值2,……);
Inset into student values (3,’wangwu’,66.6);
3,为表的指定字段添加数据
就是在insert语句中只向部分字段中添加值,
Insert into 表名(字段1,字段2,。。。)values
(值1,值2,‘’‘’);
比如:
Insert into student(id,name,)values(35,’赵胜杰’);
同时添加多条记录;
语法格式:
Insert into 表名(字段名1,字段名2,…..)
Values(值1,值2,。。。),(值1,值2,。。。);
在上述语法格式中,“(字段1,字段2,。。。)”是可选的,用于指定插入的字段名,
“(值1,值2,。。。)”表示要插入的记录,可插入多条,并且每条记录用逗号隔开。
比如:
Insert into zsj values (1,’zss’),
(2,‘zss’),
(3,’zss’);
如果在某个字段中没有给它添加值,系统会为它自动添加默认值NULL。
3.2更新数据;
语法格式:
Update 表名
Set 字段1=值1,字段2=值2
Where条件表达式
Where条件表达式是可选的,用于指定更新数据需要满足的条件。
Update语句可以更新部分数据和全部数据。
Update更新部分数据;
更新表中一条或几条数据,需要使用where子句来指定更新记录的条件;
比如:
Update student set name=’caocao’,grade=50
Where id=1;
Update 更新全部数据;
Update student set grade=80;
这个
3.3删除数据
MySQL中长使用delete语句来删除表中的记录;
语法格式:
Delete from 表名 where[条件表达式];
Where条件表达式为可选参数;delete语句可以删除部分语句和全部语句;
Delete删除部分语句;
Select * from student
Whereid =11;
可以查看是否删除成功;
Select * from student
Where id=11;
Delete删除全部数据;
Delete from student;
使用truncate删除表中数据
Truncate table 表名;
比如:
Truncate table student;
Truncate语句和detele语句的区别;
(1),delete语句是DML语句,truncate语句是DLL语句;
(2),delete语句后面可以跟where子句,通过指定where子句中的条件只删除满足条件的部分记录;而truncate语句只能删除表中所以的记录;
(3),使用truncate语句删除表中的数据后,再次向表中添加记录时,自动增加字段的默认初始值重新由1开始,而使用delete语句删除表中所有记录后,再次向表中天记录时,自动增加的值为删除时该字段的最大值加1;
如图所示:
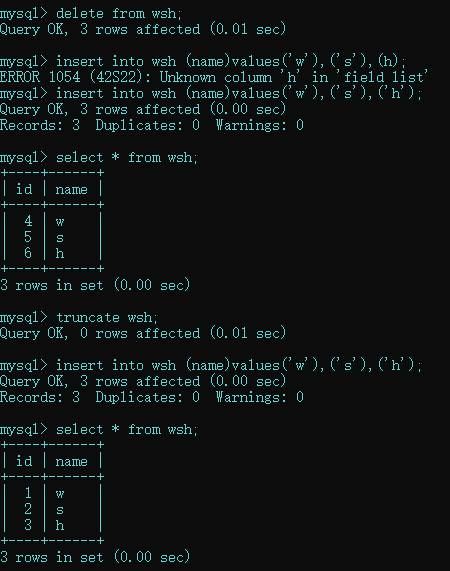
这里注意:使用delete语句时,每删除一条记录都会在日志中记录,而truncate语句不会记录,所以truncate语句的执行效率比delete语句高;
注意:使用delete语句删除后不用commit语句提交既可以进行回滚(rollback),而truncate语句默认不能回滚(roollback)
添加数据:
创建一张名为 score的表,表中各字段名及数据类型为:
sno (varchar(20)), cno (varchar(20)),degree (decimal),并且将sno设为主键,为cno添加非空约束,
向score表中插入以下数据:
sno cno degree
103 3-245 86
105 3-245 75
109 3-245 68
101 3-105 92
107 3-105 88
108 3-105 76
109 3-105 64
104 3-105 91
100 3-105 78
102 6-166 85
104 6-166 79
109 6-166 81
create table score(
sno varchar (20) primary key,
cno varchar(20) not null,
degree decimal
);
insert into score values
('103','3-245','86'),
('105','3-245','75'),
('108','3-245','68'),
('101','3-105','92'),
('107','3-105','88'),
('106','3-105','76'),
('109','3-105','64'),
('104','3-105','91'),
('100','3-105','78'),
('102','6-166','85'),
('120','6-166','79'),
('110','6-166','81');
数据查询语言DQL(select)
Select [distinct](注释)*|{字段名1,字段名2.。。。。}
From 表名
1.Select * from t1;(查询所有列)
2.Select id from t1;(查看id)
3.Select name from t1;
4.Select id,name from t1;(查看多列)
5.select name from t1 where id=2;(查询单个)
4.1简单查询;
Select语句;
Select 【distinct】* |字段1,字段2,字段3,。。。
from 表名 [where 条件表达式1]
[GROUP BY 字段名 [HAVING条件表达式2]]
[ORDER BY 字段名 [ASC|DESC]]
[LIMIT [OFFSET] 记录数]
(1),select [distinct]*|字段1,字段2,。。。“字段1,字段2,”表示表中查询的指定字段,(*)通配符表示所有字段,二者为互斥关系,任选其一,
“dsitinct”是可选参数,用于剔除查询结果的重复的数据;
FROM表名:表示从指定的表中查询数据;
(4),GROUP BY字段名[HAVING 条件表达式2]:“GROUP BY ”是可选参数,用于将查询结果按照指定的字段进行分组,“HAVING”也是可选参数,用于对分组后的结果进行过滤;
(5),ORDER BY 字段名[ASC|DESC]:“ORDER BY”是可选参数,用于将查询结果按照指定字段进行排序。排序方式由参数ASC或DESC控制,其中ASC是升序,DESC是降序,如果不指定参数,默认为升序。
(6),LIMIT[OFFSET]记录数:“LIMIT”是可选参数,用于限制查询结果的数量。LIMIT后面可以跟两个参数,“OFFSET”表示偏移量,如果偏移量为0则从查询结果的第一条记录开始,如果为1从第二条开始,以此类推。
OFFSET为可选参数,如果不指定其,默认值为,记录数表示返回查询的记录条数;
4.2.1查询所有字段
Select 字段1,字段2,。。。from 表名;
Create table wsh2(id int (3) primary key auto_increment,
Name varchar(20) not null,
Grade float,
Gender char(2)
);
Insert into wsh2(name,grade,gender)
Values(‘wsh’,80,’男’),
‘wsh’,80,’男’),
‘wsh’,80,’男’),
‘wsh’,80,’男’),
‘wsh’,80,’男’),
‘wsh’,80,’男’),
‘wsh’,80,’男’),
‘wsh’,80,’男’);
用select语句来查询wsh表中的记录;
Select id,grade,gender from wsh;
2. 在select语句中使用("*”)通配符代替所有字段;
3. Select * from 表名;
4.1.3查询指定字段;
Select name,gender from wsh;
4.2按条件查询;
语法格式:
Select 字段名1,字段2,。。。
from 表名
where条件表达式;
关系算符中<>和!=都表示不等于
Select id,name,from wsh where id>8;
4.2.2带IN关键字的查询;
IN关键字用于判断某个字段的值是否在指定的集合中,如果字段的值在集合中,则满足条件;
语法格式:
Select * |字段1,字段2,。。。
From 表名
Where 字段名[NOT] IN (元素1,元素2,。。。);
“元素1,元素2,。。。”表示集合中的元素,即指定的条件范围,NOT是可选参数
可查询不在IN关键字指定集合范围中的记录;
查询wsh表中id为1、2、3的记录;
Select id,grade,gender from wsh where id in(1,2,3);
使用NOT IN;
Select id,grade,gender from wsh where id not in(1,2,3);
4.2.3带between and 关键字的查询;
BETWEEN AND用于判断某个字段的值是否在指定的范围之内,如果在则满足条件,该字段所在的记录会被查询出来,反之则不会;
语法格式:
Select * |字段1,字段2,。。。
From 表名
Where 字段名 [NOT] BETWEEN 值1AND值2;
比如:
Select id,name from student where id between 1and3;
将会查询出所有1到3的记录;
BETWEEN AND之前也可以使用NOT,表示查询指定的范围之外的记录;
Select id,name from student where id not between 1and3;
4.2.4空值查询
在数据表中,某些列的值可能为空值(NULL),空值不同于0,也不同于空字符串。在NySQL中使用IS NULL关键字来判断字段的值是否为空值。
语法格式:
Select *|字段1,字段2,。。。
From 表名
Where 字段名 IS [NOT] NULL;
“NOT”是可选参数;
查询student表中gender为空值的记录;
Select gender from student where gender is null;
查询student表中gender不为空值的记录;
Select gender from student where gender is not null;
4.2.5带DISTINCT关键字的查询;
很多表中某些字段的数据存在重复的值,需要过滤掉查询记录中重复的值,可以使用DISTINCT关键字来实现这种功能;
语法格式:
Select distinct 字段名 from 表名;
Select distinct id from student;
DISTINCT关键字作用于多个字段
Select distinct 字段名1,字段2,。。。
From 表名;
Select distinct id,name,gender,grade from student;
只有两个字段的值否相同时才会被认为是重复;
4.2.6带LIKE关键字的查询;
有时候需要对字符串进行模糊查询,例如查询student表中name字段值以字符“b”开头的记录,为了完成这种功能,MySQL中提供了LIKE关键字可以判断两个字符串是否相匹配。使用LIKE关键字的select 语法格式;
Select *|字段1,字段2,。。。
From 表名
Where 字段名 [NOT] LIKE ’匹配字符串’;
Not表示不匹配的字符串记录;
“匹配字符串”指定用来匹配的字符串,其值可以是一个普通字符串,也可是包含(%)和(_)的通配符。
1, 百分号(%)通配符;
2, 匹配任意长度的字符串,包括空字符串。例如,查找student表中name字段值一字
“s”开头的学生id;
Select id,name from student where like name “s%”;
查询一字符”w”开始以字符”g”结尾的学生id;
Select id,name from student where name “w%g”;
在通配符字符串中可出现多个%;
查询包含”y”的学生id,
Select id,name from student where name like ‘%y%’;
无论y在什么位置都可以查询出来;
LIKE之前可使用NOT,查询与指定通配字符串不匹配的记录
Select id,name from student where name not like ‘%y%’;
下滑线(_)通配符;
下划线通配符只匹配单个字符,如果要匹配多个字符,需要使用多个_。
1查询stundent表中name字段值以字符串”wu”开始,以字符串”ong”结尾的
,并且两个字符串之间只有一个字符串的记录,
Select * from student where name like ‘wu_ong’;
查询student吧中name字段值包含7个字符,并且以字符串”ing”结束的记录;
2.select * from student where name like ‘____ing’;
使用百分号和下划线通配符进行查询操作
如果要匹配字符串中的百分号和下划线,就需要在通配字符串中使用右斜线(“\”)
对百分号和下划线进行转义,”\%”匹配百分号字面值,”\_”匹配下划线字面值。
4-21查询student表中name字段值包括”%”的记录。
添加
Insert into student (name,grade,gender)
Values(‘sun%er’,’95’,’男’);
查询
Select * from student where name like ‘%\%%’
4.2.7带AND关键字的多条件查询
使用AND关键字可以连接两个或多个查询条件,只有满足所有条件的记录才会被返回。
语法格式:
Select *|字段1,字段2,。。。
From 表名
Where 条件表达式1 AND 条件表达式2[…….AND条件表达式n];
查询student 表中id字段值小于5,并且gender字段值为”女”的学生姓名。
语法:
Select id,name,gender from student where id<5 AND gender=’女’;
查询student表中id字段值在1,2,3,4之中,name字段值以字符串”ng”结束。并且grade值小于80的记录。
Select id,name,grade,gender from student where id in(1,2,3,4) and name like ‘%ng’ and grade<80;
4.2.8带OR关键字的多条件查询
OR关键字可连接多个查询条件,在使用OR关键字时,只有记录满足任意一个条件就会被查询出来。
语法格式:
Select * |字段1,字段2,。。。。
From 表名
Where 条件表达式1 OR 条件表达式2[……OR 条件表达式n];
查询student表中id字段值小于3或者字段值为’女’的学生名.
Select id,name,gender from student where id<3 or gender=’女’;
多学一招;
OR和AND关键字一起使用的情况;
OR和AND关键字可以一起使用,需要注意的是,AND的优先级高于OR。
分组查询与分页查询(group by,limit)
4.3高级查询;
函数名 作用 函数名 作用
Count()
Sum()
Avg() 返回某列的行数
返回某列值得和
返回某列的平均值 MAX()
MIN() 返回某列的最大值
返回某列的最小值
上面的函数用于对一组值进行统计
1, COUNT()函数
2, COUNT()函数用于统计记录的条数,语法格式:
Select COUNT(*) from 表名;
比如:
Select count(*) from student;
2.SUM函数
SUM()是求和函数,用于求出表中某个字段所以值得总和。
Select SUM(字段名) from student;
比如:
Select SUM(id) from student;
4. AVG函数
AVG()用于球平均值
Select AVG(字段名) from student;
5. MAX函数
MAX函数用于球最大值
Select MAX(字段名) from student;
6. MIN函数
Select MAX(字段值) from student;
4.3.2对查询结果排序
使用ORDER BY对查询结果进行排序
语法格式:
Select 字段1.字段2,。。。。
From 表名
ORDER BY 字段1[ASC|DESC],字段2[ASC|DESC];
ASC=升序排序;
DESC=降序排序;
默认情况下用ASC;
4-32
查询student表中的所有记录,并按照grade字段进行排序
Select * from student;
ORDER BY grade;
对指定的字段grade进行排序,默认是按照ASC方式进行排序的;
4-33
查询student表中的所有记录,使用参数ASC按照grade字段进行排序
Select * from student ORDER BY grade ASC;
4-34
查询student表中的所有记录,使用参数DESC按照grade字段进行排序
Select * from student ORDER BY grade desc;
4-35
查询student表中的所有记录,按照grade的升序和按照grade得到降序排序;
Select * from student ORDER BY grade asc,grade desc;
注意:
在按照指定字段进行排序时,如果某条记录的字段值为NULL,则这条记录会显示在第一条,因为NULL值可以被认为是最小值。
4.3.3分组查询
在对表中数据进行统计时,也可能需要按照一定的类别进行统计,比如,分别统计student表中gender字段值为”男”、“女”和“NULL”的学生成绩之和,在MySQL中可以使用GROUP BY 按某个字段或者多个字段中的值进行分组,字段中值相同的为一组。
Select 字段1,字段2,。。。
From 表名
GROUP BY 字段1,字段2,。。。[HAVING 条件表达式];
HAVING关键字指定条件表达式对分组后的内容进行过滤。GROUP BY 一般聚合函数一起使用,如果查询的字段在GROUP BY 后,却没有包含在聚合函数中,该字段显示的是分组后的第一条记录的值,会导致查询结果不符合我们的预期。
1. 单独使用GROUP BY 分组
查询的是每个分组中的一条记录;
Select * from student group by gender;
2. GROUP BY 和聚合函数一起使用
可以统计出某个或者某个字段在一个分组中的最大、最小、平均值
4-37
将student表按照gender字段值进行分组查询,计算出每个分组中各有多少名学生;
Select count(*),gender from student group by gender;
GROUP BY 对student 表按照gender字段中的不同值进行了分组,并通过COUNT()函数统计出gender字段值为“NULL”的学生有一个,gender字段值为“男”的学生有5个,为“女”的有2个;
3. GROUP BY 和 HAVING 关键字一起使用;
HAVING关键字和WHERE关键字的作用相同,都用于设置条件表达式对查询结果进行过滤,但是HAVING关键字后可以跟聚合函数,而WHERE关键字不能。一般情况下HAVING关键字和GROUP BY一起使用,用于对分组的结果进行过滤。
4-38将student表按照gender字段进行分组查询,查询出grade字段值之和小于300的分组。
Select sum(grade),gender from student group by gender having (grade)<300;
Select gender,sum(grade) from student froup by gender having(grade)<300;
下面对gender值为“男”的所有学生其grade字段值之和进行查询,
Select gender,sum(grade) from student where gender=’男’;
4.3.4使用LIMT限制查询结果的数量;
查询数据时,可能会反回多条记录,而用户需要的记录可能只是其中的一条或几条,
实现分页功能,每页显示10条信息,每次查询就只需要查出10条记录。MySQL中提供了一个关键字LIMIT,可以指定查询结果从那一条记录开始以及一共查询多少条记录
语法格式:
Select 字段1,字段2,。。。
From 表名
LIMT [OFFSET,] 记录数
在上面的语法格式中,LIMIT后面可以跟两个参数,第一个参数“OFFSET”表示偏移量,如果偏移量为0则从查询结果的第一条记录开始,偏移量为1则从查询结果的中的第二条记录开始,以此类推。OFFSET为可选值,如果不指定其默认值为0.第二个参数“记录数”表示返回查询记录的条数。
4-39查询表中前4条记录;
Select * from student limit 4;
查询student表中grade字段值从第5位到第8位的学生(从高到低)
Select * from student order by grade desc limit 4,4;
使用order by。。。desc使学生按照grade字段值从高到低进行排序
智能推荐

layer弹出层的简单使用
一、layer的icon样式 以上样式测试代码: [javascript] view plain copy layer.confirm(‘icon测试’, {icon: 1, title:‘提示’}, function(index){ //do...
Nginx 解析漏洞复现
漏洞环境搭建 时间有限,漏洞环境搭建教程简单,在此不再赘述。 具体项目地址:https://github.com/vulhub/vulhub 搭建教程及说明可参考:https://vulhub.org/ -还是挺简单的- Nginx 解析漏洞复现步骤如下: 靶机环境 由此可知,该漏洞与Nginx、php版本无关,属于用户配置不当造成的解析漏洞。 启动环境 复现 1). 访问 http://IP/u...
ArrayList 源码解析(JDK1.7)
ArrayList 源码解析(JDK1.7) ps: 我思考了一下…想要不要发这篇博客… 感觉作为一个初学者…发这种源码解析… 尤其当做学习记录这样的东西来做…感觉没有任何的重点可言… 不过思考了一下…反正估计也没人看 (狗头) 就发了吧 纯属个人 … emmm 萌新的学习经历- - 大...

GDB随笔(一)
在编译的时候必须加上-g,生成的目标文件才能够进行调试。(我们调试的是目标文件) -g选项的作用是在目标文件中加入源代码的信息,保证gdb能找到源文件。 -o选项,相当于指定一个文件作为目标文件。 可以做一个实验:由main.c生成main(-g),然后将m**在目标文件中加入源代码的信息,保证gdb能找到源文件。ain.c改成其他名字,然后调用gdb main,就会发现对gdb使用命令(list...

tensorboard报No dashboards are active for the current data set
遇到这个错误,通过两步可以解决这个问题 一、检查所指定的目录下是否存在event文件 类似于上面箭头所指的文件,并不需要所指定的目录为event的上一级目录,比如像下面这种情况 在启动tensorboard的时候,指定到log目录就行了,命令如下 二、确定logdir的路径是否正确 我们在确定event文件确实存在之后,还需要确定logdir的路径是否正确,因为logdir的路径中不能包含中文、空...
猜你喜欢

struts2--动态方法调用的三种方式
一般情况下,我们是通过实现action中execute方法来实现请求处理,这样子一个action中就只能写一个方法,当我需要实现很多方法的时候写多个action显然是很不合理的,因此就需要使用动态调用来实现。 方式一:指定method属性 也就是说通过在struts.xml文件中通过配置action标签的method属性来设置即可。 但是这个方法有一个缺陷,当一个action中有很多方法的时候就需...

深度剖析HashMap(一)——基于JDK7
HashMap是每个Java/Android程序员必须掌握的一种容器。在这个专题下将分若干篇文章对其进行深度剖析。由于JDK版本的不同,HashMap的底层实现也有些许差别。本文先对基于JDK7的HashMap进行分析,之后会奉上JDK8中对HashMap实现改动的分析。 一、HashMap结构概览 在JDK7中,HashMap说白了就是用到两种数据结构——数组与链表。 数...
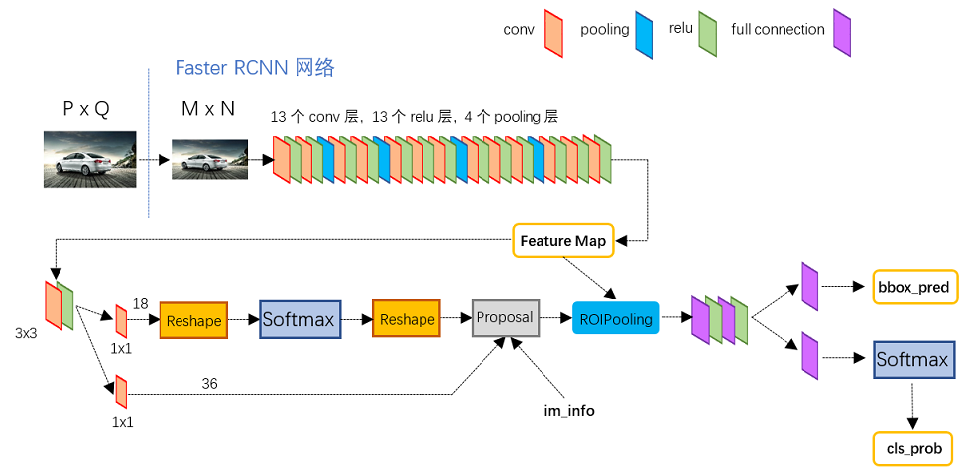
Faster R-CNN基于pytorch的原理
相关资料以及下载 代码地址:https://github.com/ruotianluo/pytorch-faster-rcnn.git 原理参考:https://blog.csdn.net/zm147451753/article/details/88218619 代码编译和运行 代码使用方法,暂时没找到win系统下的方法,为此,我安装了unbuntu,还是蛮好用的。 代码的编译运行准...

welpwn(RCTF-2015)--write up
文件下载地址: 链接:https://pan.baidu.com/s/1MG2z9r4wz_WTEz1vIikqJQ 提取码:3tbc 0x01.分析 checksec: 源码分析: 流程非常简单,首先输入一个1024大小字符串,然后进入函数echo,这个函数会将buf的数据一个字节一个字节的复制到s2中,当遇到x00时停止,退出,并打印s2。 寻找漏洞: 第一个read处没有漏洞,但...

mongodb+java实现日志的日活与月活查询
业务介绍 前段时间有个日志统计的需求,是规范的登陆日志,估计一个月有几十万,放入hadoop太麻烦了,放数据库又怕后续数据量增加较快,于是尝试用mongodb来存储,后续进行统计。 mongodb是采用3.4, 2017年12月最新的是3.6 中文官网的文档(英文官网的文档访问太坑爹了) http://www.mongoing.com/docs/crud.html 先查看下自己的系统,这里是选择用...