同义词(近义词)算法总结(附代码)
一、简介
同义词挖掘一般有三种思路,借助已有知识库,上下文相关性,文本相似度。
1.1 知识库
可以借助已有知识库得到需要同义词,比如说《哈工大信息检索研究室同义词词林扩展版》和 HowNet,其中《词林》文件数据如下。
Aa01A01= 人 士 人物 人士 人氏 人选
Aa01A02= 人类 生人 全人类
Aa01A03= 人手 人员 人口 人丁 口 食指
Aa01A04= 劳力 劳动力 工作者
Aa01A05= 匹夫 个人
Aa01A06= 家伙 东西 货色 厮 崽子 兔崽子 狗崽子 小子 杂种 畜生 混蛋 王八蛋 竖子 鼠辈 小崽子
Aa01A07= 者 手 匠 客 主 子 家 夫 翁 汉 员 分子 鬼 货 棍 徒
Aa01A08= 每人 各人 每位
Aa01A09= 该人 此人
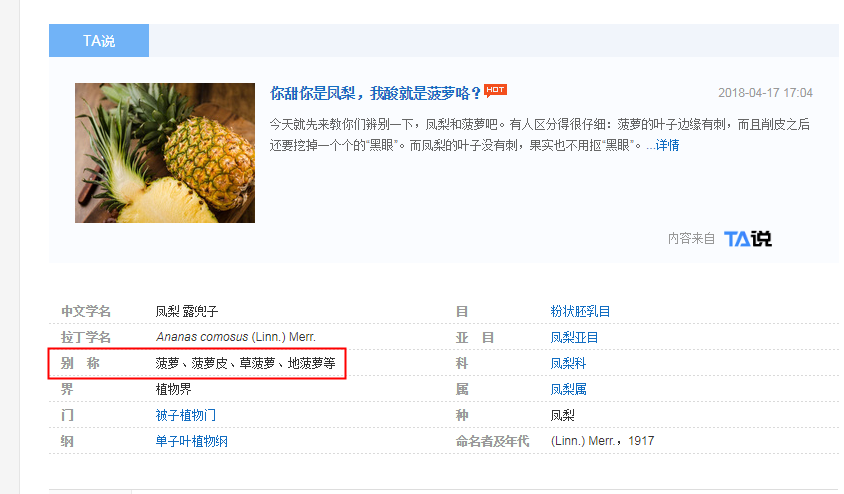
以上两个知识库是人工编辑的,毕竟数量有限,我们还可以借助众包知识库百科词条获取同义词,比如百度百科,如下图所示,在百度百科搜索“凤梨”,我们可以看到在返回页面结果中的 info box中有一个属性为“别称”,别称中就是凤梨的同义词。除此之外,在百科词条的开头描述中,有如下描述“又称”、“俗称”也是同义词,我们可以利用爬虫把这些词爬下来。
百度搜索和谷歌搜索等搜索工具一般都有重定向页,这也可以帮助我们去挖掘同义词。
使用知识库挖掘同义词的优点是简单易得,而且准确率也高,缺点就是知识库覆盖率有限,不是每个细分领域都有。对于金融、医疗、娱乐等领域都需要各自的知识库。
1.2 上下文相关性
利用上下文相关性挖掘同义词也比较好理解,如果两个词的上下文越相似的话,那么这两个词是同义词的概率就越大。使用词向量挖掘同义词是比较常见的做法,比如使用word2vector训练得到词向量,然后再计算余弦相似度,取最相似的top k个词,就得到了同义词。
word2vector是无监督学习,而且本质上来说它是一个语言模型,词向量只是它的副产品,并不是直接用来挖掘同义词。有篇paper发明了弱监督的同义词挖掘模型DPE,也取得了不错的效果。DPE模型流程如下图,一共分为两个阶段,第一阶段跟word2vector差不多,也是训练词向量,只不过DPE是一种graph embedding的思路,首先从语料中构建语义共现网络,然后通过对网络的边采样训练词向量。第二阶段通过弱监督训练一个打分函数,对输入的一对词判断属于同义词的概率。感兴趣的可以看看这篇paper 论文链接
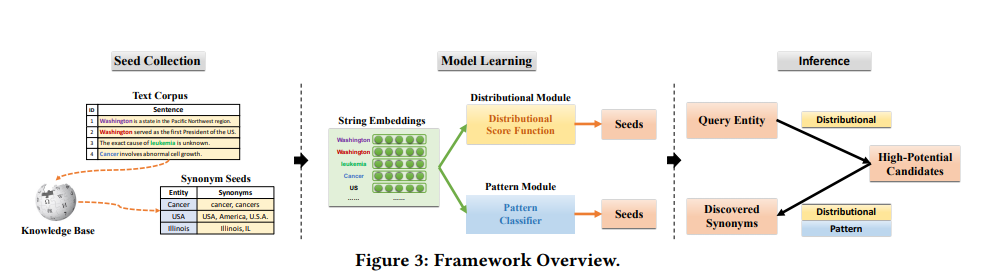
基于上下文相关性的同义词挖掘方法的优点是能够在语料中挖掘大量的同义词,缺点是训练时间长,而且挖掘的同义词很多都不是真正意义上的同义词需要人工筛选。这种方法对于词频较高的词效果较好。
1.3 文本相似度
对于这一对同义词“阿里巴巴网络技术有限公司”和“阿里巴巴网络公司”直接去计算上下文相似度可能不太有效,那一种直观的方法是直接计算这两个词的文本相似度,比如使用编辑距离(Levenshtein distance)或者 LCS(longest common subsequence),如果两个词的文本相似度大于阈值的话我们就认为他们是同义词的关系。在这里推荐一个计算文本相似度的Java开源项目,基本上文本相似度算法应有尽有。[ 文本相似度算法 ]
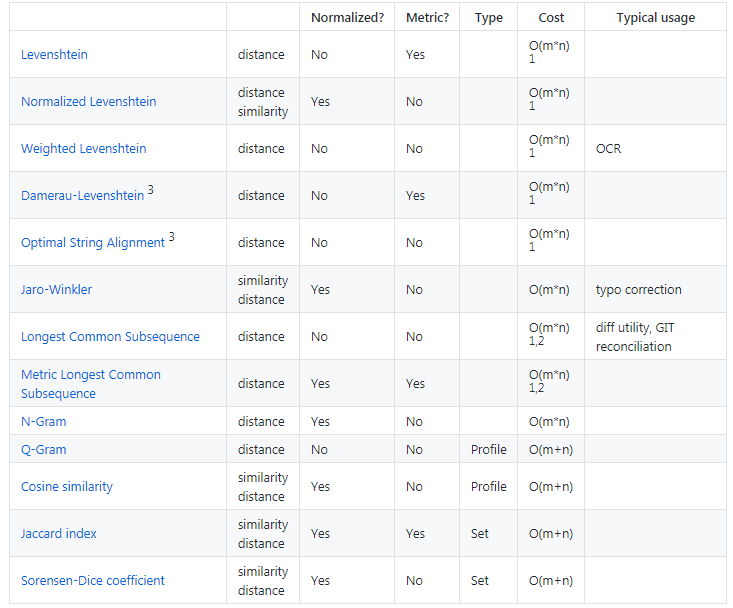
基于文本相似度同义词挖掘方法的优点是计算简单,不同于word2vector,这种方法不需要使用很大的语料,只要这个词出现过一次就可以发现同义词关系。这种方法的缺点是有时候不太靠谱,会挖掘出很多错误的同义词,尤其是当两个词比较短的情况下,比如“周杰伦”和“周杰”,就可能会被认为是同义词。所以这种方法适用于一些较长的文本,特别是专业词汇,术语。
二、同义词挖掘的算法实现
github地址:https://github.com/tigerchen52/synonym_detection
在这个github项目中实现了4种同义词挖掘的方法:
- 百度百科同义词
- word2vector
- 语义共现网络的节点相似度
- Levenshtein距离
觉的有用同学记得点star~~
2.1 百度百科同义词
代码示例(synonym_detection/source/main.py)
def baike_invoke():
import baike_crawler_model
print(baike_crawler_model.baike_search(('凤梨', '001')))
if __name__ == '__main__':
baike_invoke()输出
['菠萝皮', '地菠萝', '菠萝', '草菠萝']2.2 word2vector
在这里使用《三体》小说作为训练语料,使用以下10个词作为输入,从语料中挖掘这10个词的同义词。后面几个方法使用相同的输入。
1|海王星
2|女孩
3|椅子
4|海军
5|阵列
6|变化
7|程心
8|火焰
9|天空
10|建造代码示例
python synonym_detect -corpus_path ../input/三体.txt -input_word_path ../temp/input_word.txt -process_number 2 if_use_w2v_model True参数
- -corpus_path 为语料文件,使用三体小说作为训练语料
- -input_word_path 输入词表,对词表中的词进行同义词挖掘。文件中每行以“|”作为分隔符,第一列是id,第二列是输入词
- -process_number 2 进程数量
- -if_use_w2v_model True 使用word2vector模型
- 默认返回top 5个同义词
输出
1 海王星 海王星|土星|天王星|背面|金星
3 椅子 椅子|办公桌|地板|地毯|铁锹
2 女孩 女孩|中年人|女孩儿|女子|泪光
9 天空 天空|晨光|夜空|暮色|漆黑
4 海军 海军|军种|服役|事务性|政工
6 变化 变化|隐隐约约|异常|微妙|所致
5 阵列 阵列|矩形|一千公里|环|标示出
7 程心 程心|AA|艾|当程心|曹彬
8 火焰 火焰|暗红|山脉|灼热|变幻
10 建造 建造|天梯|最小|准|航空母舰2.2 语义共现网络的节点相似度
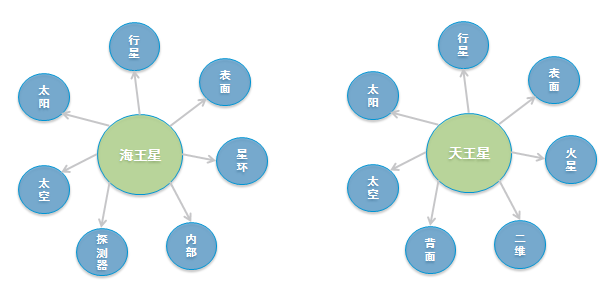
语义共现网络本质是根据上下文构建的图,图中的节点是词,边是这个词的上下文相关词。对于语义共现网络的两个节点,如果这两个节点的共同邻居节点越多,说明这两个词的上下文越相似,是同义词的概率越大。例如,对于《三体》小说中的两个词“海王星”和“天王星”,在《三体》语义共现网络中,“海王星”和“天王星”的邻居节点相似度很高,则说明两个词是同义词的可能性很高。如下图所示:
代码示例
python synonym_detect -corpus_path ../input/三体.txt -input_word_path ../temp/input_word.txt -process_number 2 -if_use_sn_model True
输出
5 阵列 阵列|矩形|队列|星体|量子
9 天空 天空|中|夜空|太阳|消失
4 海军 海军|航空兵|服役|空军|失败主义
10 建造 建造|制造|加速器|飞船|太阳系
3 椅子 椅子|桌子|坐下|沙发|台球桌
1 海王星 海王星|天王星|土星|卫星|群落
7 程心 程心|AA|中|罗辑|说
8 火焰 火焰|光芒|光点|推进器|雪峰
2 女孩 女孩|接待|冲何|请云|女士
6 变化 变化|发生|意味着|恢复|中可以看出基于语义共现网络得到的同义词与word2vector结果类似,甚至在某些词上效果更好。
2.4 Levenshtein距离
代码示例
python synonym_detect -corpus_path ../input/三体.txt -input_word_path ../temp/input_word.txt -process_number 2 -if_use_leven_model True
输出
1 海王星 海王星|冥王星|天王星|星|王
7 程心 程心|请程心|带程心|连程心|从程心
6 变化 变化|变化很大|动态变化|发生变化|化
3 椅子 椅子|子|筐子|村子|棒子
2 女孩 女孩|女孩儿|女孩子|小女孩|女
10 建造 建造|建造成|造|建|建到
5 阵列 阵列|列|阵|历列|列为
9 天空 天空|海阔天空|空|天|天马行空
8 火焰 火焰|火|焰|火星|野火
4 海军 海军|于海军|陆海空军|海|海军军官2.5 DPE模型
undo
智能推荐
数据结构(C/C++)课程阶段总结(七)
目录 写在前面 稀疏矩阵抽象数据类型定义 基本操作的实现方法 稀疏矩阵对应三元组表的创建 改变矩阵元素值 获取矩阵元素值 输出矩阵 具体实现 运行结果 总结 写在前面 课程采用教材《数据结构(C语言版)》严蔚敏,吴伟民,清华大学出版社。 本系列博文用于自我学习总结和期末复习使用,同时也希望能够帮助到有需要的同学。如果有知识性的错误,麻烦评论指出。 本次实验实现稀疏矩阵的三元组顺序存储表示。 稀疏矩...

Day 10 ajax介绍,初步了解
Day 10 ajax介绍,初步了解 一、ajax介绍 AJAX即“Asynchronous JavaScript and XML”(异步的JavaScript与XML技术) 传统的Web应用允许用户端填写表单(form),当提交表单时就向网页服务器发送一个请求。服务器接收并处理传来的表单,然后送回一个新的网页,但这个做法浪费了许多带宽,因为在前后两个页面中的大部分HTML...
Typora基础教程
目录 Typora基础教程 Markdown简介 Typora安装教程 mac安装教程 Windows安装教程 Markdown基本语法教程 Markdown的常用格式 Markdown的空格、换行与段落 Typora数学公式教程 Typora基础教程 Markdown简介 什么是Markdown: Markdown是一种轻量级的标记语言,用户通过一系列符号,如:#*[+$`,来表示粗体、斜体、超...

访问github无css样式的解决方案
1、浏览器右键查看加载失败的css文件来源 加载失败此处文件名会为红色 复制域名assets-cdn.github.com 2、查询css文件所在ip 打开https://www.ipaddress.com右上角输入框粘贴之前的css所在域名,点击搜索,记下搜索结果的ip 3、修改host文件 mac下: 打开finder(访达),点击右上角 前往-前往文件夹 输入/private,右键显示简介,...

Eclipse用maven构建SSM框架遇到的问题及解决方法
听说Maven很好用,刚刚好实验了Spring+Mvc企业应用实践的一个小项目,所以就拿它来练手了,用maven来重构它。 开发环境如下: Eclipse:Eclipse Project Release Notes 4.7 (Oxygen) JDK:JDK1.8.0_144 Maven:apache-maven-3.5.4 Tomcat:Tomcat 9 环境的配置就不多说了,其实只要有目录就行,...
猜你喜欢
Raid磁盘管理
文章目录 前言 实验环境 实验操作步骤 RAID0 RAID1 RAID5 RAID6 RAID1+0 总结 前言 RAID称为独立冗余磁盘阵列,简单的说就是raid把多块独立的物理硬盘按不同的方式进行组合,形成硬盘组,从而提供比单个硬盘具有更高的存储性能和存储容量的数据备份技术。 RAID分不同的等级,不同的RAID在数据可靠性上做了不同的权衡。在实际应用中可以根据需求关系来确定使用哪个RAID...

常见排序算法总结——2、插入排序
常见排序方法 原创文章,转载请添加本网页链接 https://blog.csdn.net/qq_37334950/article/details/104378361 2、插入排序:将数组分为有序组(数组的第一个元素)和无序组(数组的第二个元素~最后一个元素),每次取出无序组的第一个元素,经过比较插入有序组的合适位置 举例: 初始数组:9 3 4 2 6 7 5 1 分组:(9)(3...
深度学习涂鸦! 我们的草图识别之旅
Doodling with Deep Learning! Our Journey with Sketch recognition 在这篇博客文章中,我们描述了我们的流程理解,拟合模型,并找到了Google Quick,Draw的有趣应用程序!数据集。 与我们一起走过这段旅程,看看我们如何应对成功分类“可以说是世界上最可爱的研究数据集”的挑战! 该项目由Akhilesh Re...
数字图像处理学习笔记3:图像的频域处理和滤波
本次学习内容是记录图像除了空域处理的另一个处理方式:频域处理,以及从频域角度看待滤波 目录 什么是频谱 空域-频域的变换 频域的滤波 1.什么是频谱 频域是指对于不同频率分量排列在一起,而不是按照时间或者位置作为坐标去衡量一些信号的域。 频谱则是在频域作为域去衡量的信号在不同频率下振幅大小的排列。 频谱可以反映变化,变化的越剧烈则高频成分越强,在整个区间内变化如果很小则说明频率值较小的部分占主要。...
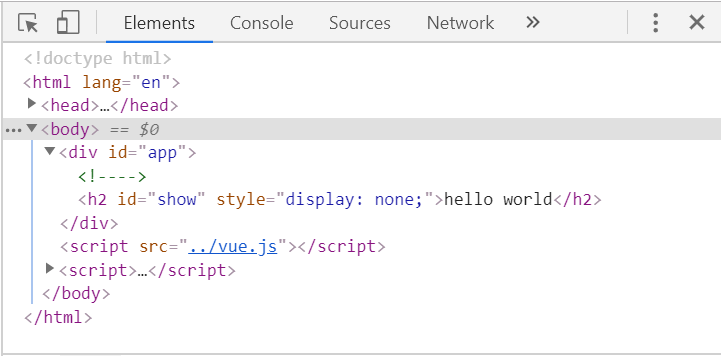
用案例说明v-if和v-show的区别
文章目录 v-if和v-show相同之处 v-if和v-show不同之处 总结 v-if和v-show相同之处 v-if 和 v-show 都具有条件判断的功能,如下面案例所示,“hello word” 都会在浏览器上消失 v-if和v-show不同之处 现在将上面两个h2标签里分别加上不同的id属性,和上面执行相同的步骤,“hello word” ...