通过python爬虫下载TXT文件,并整合到一个文件中
最近学习了下python爬虫,在简单看了一些文档之后就想着做点东西来完善下自己学习的内容。
因此就写了下面的代码,来实现把一个网站上面的小说内容下载下来。小说是一章一章的结构,因此在把每章的内容爬下来之后,还需要合并到一个TXT文件中。
python的版本是3.6,然后使用了beautifulsoup库。
网站的界面如下:

至于为什么我会把文件通过字符串的方式写到最终文件中,而不是通过字节码的方式,是因为考虑到为了能够把多个文件拼接到一起后,还考虑到文件的格式。比如每一章的名字,不同章之间能够有几个换行。方便我本地的一些靠小说的APP能够识别出小说的目录结构。
整体代码如下:
import urllib.request
import urllib.error
import re
from bs4 import BeautifulSoup
import time
import random
def download(url, user_agent='wswp', num_retries=2):
print('downloading: %', url)
# 防止对方禁用Python的代理,导致forbidden错误
headers = {'User-agent': user_agent}
request = urllib.request.Request(url, headers=headers)
try:
html = urllib.request.urlopen(request).read()
except urllib.error.URLError as e:
print('download error:', e.reason)
html = None
if num_retries > 0:
# URLError是一个上层的类,因此HttpERROR是可以被捕获到的。code是HttpError里面的一个字段
if hasattr(e, 'code') and 500 <= e.code < 600:
return download(url, num_retries - 1)
return html
def get_links(html):
"""
return a list of links from html
:param html:
:return:
"""
webpage_regex = re.compile('<a[^>]+href=["\'](.*?)["\']')
return webpage_regex.findall(html)
page_url = 'https://www.szyangxiao.com/txt197165.shtml'
html_result = download(page_url)
if html_result is None:
exit(1)
else:
# print(html_result)
pass
# 分析得到的结果,从中找到需要访问的内容
# download_links = filter_download_novel_links(get_links(str(html_result)))
#
# for link in download_links:
# print(link)
soup = BeautifulSoup(html_result, 'html.parser')
fixed_html = soup.prettify()
# print(fixed_html)
uls = soup.find_all('ul', attrs={'class': 'clearfix'})
lis = uls[1].find_all('li', attrs={'class': 'min-width'})
with open(r'F:\红楼之庶子风流.txt', 'w') as target_file_writer:
for li in lis[340:]:
a = li.find('a')
href = a.get('href').replace('//', 'https://')
text = a.text.replace('下载《红楼之庶子风流 ', '').replace('》txt', '')
# print(text)
# print(str(download(href), 'gbk'))
target_file_writer.write(text)
target_file_writer.write('\n')
target_file_writer.write(str(download(href), 'gbk'))
target_file_writer.write('\n')
time.sleep(random.randint(5, 10))
# print(text, href)
以上就是全部的需求和代码。当然不推荐看免费小说,以上代码只是只是为了一个实验。
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
本次对代码做了点改动。因为发现了不同系统下,比如英文系统环境下,通过字符串的方式写入文件会报错。因此我把代码改成了通过字节码的方式写到文件中。
# coding:utf-8
import urllib.request
import urllib.error
from bs4 import BeautifulSoup
import time
import random
# 使用LXML的方式来代替BeautifulSoup的方式
def download(url, user_agent='wswp', num_retries=2):
print('downloading: %', url)
# 防止对方禁用Python的代理,导致forbidden错误
headers = {'User-agent': user_agent}
request = urllib.request.Request(url, headers=headers)
try:
html = urllib.request.urlopen(request).read()
except urllib.error.URLError as e:
print('download error:', e.reason)
html = None
if num_retries > 0:
# URLError是一个上层的类,因此HttpERROR是可以被捕获到的。code是HttpError里面的一个字段
if hasattr(e, 'code') and 500 <= e.code < 600:
return download(url, num_retries - 1)
return html
page_url = 'https://www.szyangxiao.com/txt197165.shtml'
html_result = download(page_url)
if html_result is None:
exit(1)
else:
pass
# 分析得到的结果,从中找到需要访问的内容
soup = BeautifulSoup(html_result, 'html.parser')
fixed_html = soup.prettify()
uls = soup.find_all('ul', attrs={'class': 'clearfix'})
lis = uls[1].find_all('li', attrs={'class': 'min-width'})
# 修改文件写入方式为byte方式。
with open(r'C:\study\红楼之庶子风流.txt', 'wb') as target_file_writer:
default_encode = 'utf-8'
new_line = '\n'.encode(default_encode)
for li in lis[340:]:
a = li.find('a')
href = a.get('href').replace('//', 'https://')
# 把字符串转换成byte,然后写入到文件中
text = a.text.replace('下载《红楼之庶子风流 ', '').replace('》txt', '').encode(default_encode)
target_file_writer.write(text)
target_file_writer.write(new_line)
# 把字符串转换成byte,然后写入到文件中。因为源文件为gbk的编码方式,因此需要先decode,然后重新encode
target_file_writer.write(download(href).decode('gbk').encode(default_encode))
target_file_writer.write(new_line)
time.sleep(random.randint(5, 10))
这样代码就适合运行在各种环境上了。
智能推荐

多个TXT文件合并为一个文件
在爬取起点小说之后,同一个文件夹里有多条txt文件,如下图,笔者想到要将目录中的txt文件合并为一个目录的txt文件方便观看目录,于是开始动手做。 代码如下: 运行结果如下: txt文件展示,成功!...
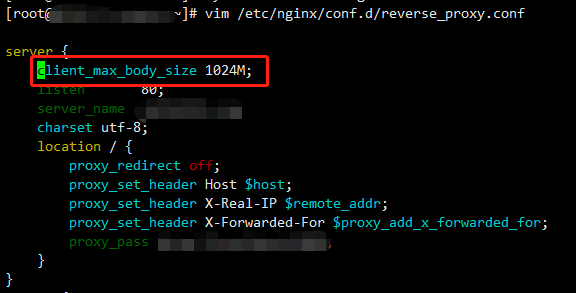
centos7部署配置迁移SVN
部署 安装 查看版本 创建版本库 配置svn信息 进入版本库中的配置目录conf,此目录有三个文件: svn服务综合配置文件(svnserve.conf)、 用户名口令文件(passwd)、权限配置文件(authz) svnserve.conf authz passwd 启用 连接路径 http配置 安装apache 修改apache默认端口 启动apache 测试,访问下面连接,出现apache...
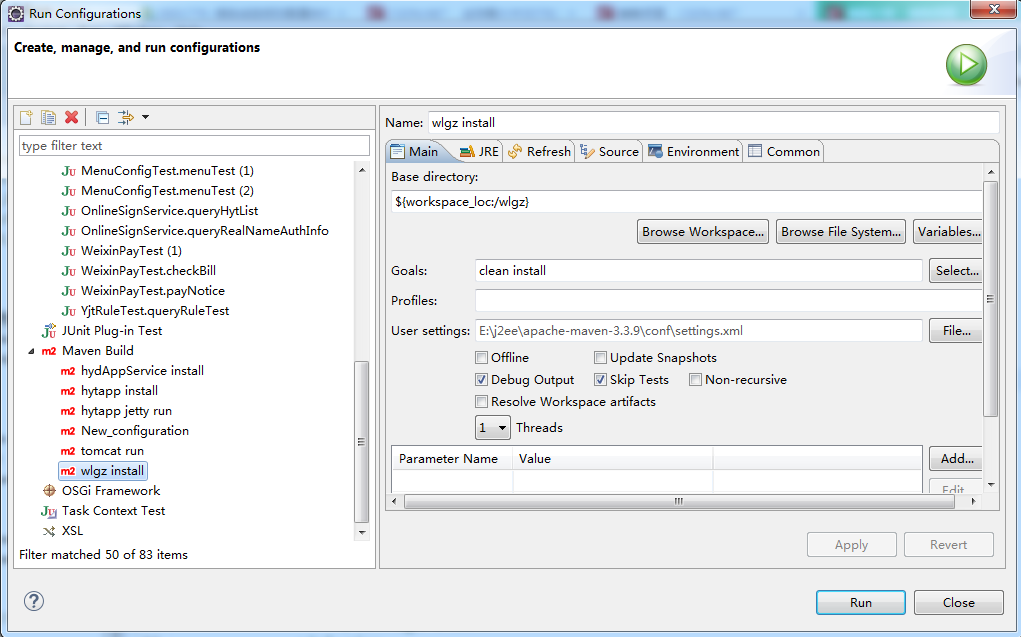
maven启动web工程
1.在pom.xml中新增了 打包install时会将xml相关文件打到war包中。 2.配置tomcat或者jetty容器 3.选择web项目右键,run as -->run configurations 双击maven build进入下面页面 4.一般先install在run,下面以tomcat启动为例。 5.如下图:...

Hadoop 之Mapreduce wordcount词频统计案例(详解)
阅读目录 一、创建项目 :example-hdfs 二、项目目录 三、WordCountMapper.class 四、WordCountReducer.class 五、WordCounfDriver.class 六、pom.xml 七、打包jar包 八、在SecureCRT软件上传刚刚生成的jar包 九、运行 十、错误及解决 MapReduce是什么? Map Reduce是Google公司开源的...
分享 webpack3.0 的安装与使用
准备开始 webpack3.0 的安装 之前在很多网站上寻找webpack3.0的知识,但是结果都不理想。经过很多努力,终于学到了一些知识,现在把这些知识分享出来吧。(希望能对小伙伴有所帮助) 全局安装 1.jpg 2.jpg 3.jpg 4.jpg 局部安装 5.jpg 更新webpack &nbs...
猜你喜欢

快速实现上滑加载更多
实现方式 在智能小程序的开发过程中,经常会遇到页面列表数量较多的情况,此时可以通过【分页】加载数据,并监听页面滑动到底部时触发【上滑加载更多】,从而增加页面首屏渲染速度。 想要实现这种分页展示数据,上滑加载更多的效果,主要有以下几种方式: 1. 使用 view自定义信息流组件 + onReachBottom 2. 使用 scroll-view + bindscrolltolower 3. 使用 s...

(五)Spring Security基于数据库的权限授权
目录 一:重写并实现了基于数据库的权限数据源 二:重写权限决策 三:实现AbstractSecurityInterceptor 四:项目地址 我们接着上一章(四)Spring Security基于数据库的用户认证,进行开发 一:重写并实现了基于数据库的权限数据源 二:重写权限决策 根据URL资源权限和用户角色,进行鉴权 三:实现AbstractSecurityInterceptor 默认实现是Fi...
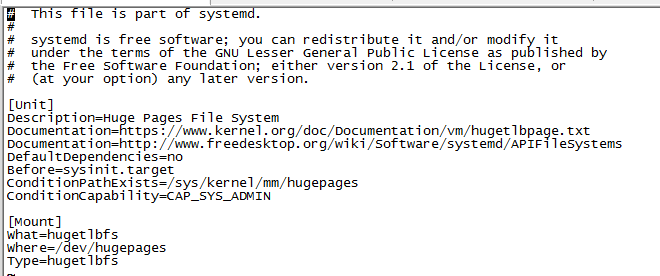
linux中systemctl详细理解及常用命令(转载)
一、systemctl理解 Linux 服务管理两种方式service和systemctl systemd是Linux系统最新的初始化系统(init),作用是提高系统的启动速度,尽可能启动较少的进程,尽可能更多进程并发启动。 systemd对应的进程管理命令是systemctl 1. systemctl命令兼容了service 即systemctl也会去/etc/init.d目录下,查看,执行相关...
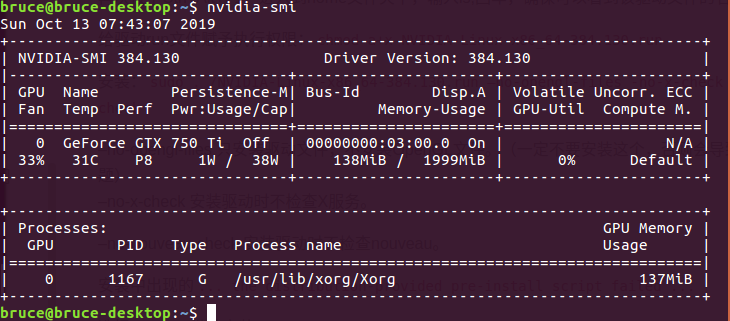
ubuntu系统下安装显卡驱动及cuda9.0
安装记录,试了很多个版本,最后重装系统,最后找到正确的解决方案。 1、下载并安装显卡驱动,由于需要安装cuda9.0考虑到兼容性,安装384.130版本的显卡驱动 下载链接:https://www.geforce.cn/drivers/results/133208 <1>卸载原有驱动 <2>设置禁止使用nouveau 输入命令:sudo vi /etc/modprobe.d...
驱动(操作)Nor Flash的原理简述
声明:下面我们均以16位宽的Nor Flash芯片MX29LV160DBTI为例讲解。涉及的程序见最后面附录。 本文章为个人学习心得记录,如有错误,还望多多指正! 其实驱动Nor Flash比较简单,方法就是在Nor Flash芯片手册里,厂家已经给我们定义了各种的命令,用以实现对Nor Flash芯片的复位reset操作、进入CFI模式、擦除指定扇区、写入数据操作等。 我们只需要查看表格,往指定...