K均值聚类算法(Kmeans)讲解及源码实现
K均值聚类算法(Kmeans)讲解及源码实现
算法核心
K均值聚类的核心目标是将给定的数据集划分成K个簇,并给出每个数据对应的簇中心点。算法的具体步骤描述如下。
- 数据预处理,如归一化、离群点处理等。
- 随机选取K个簇中心,记为。
- 定义代价函数:。
- 令为迭代步数,重复下面过程直到收敛
- 对于每一个样本,将其分配到距离最近的簇
- 对于每一个类簇,重新计算该类簇的中心
均值算法在迭代时,假设当前损失函数没有达到最小值,那么首先固定簇中心,调整每个样例所属的类别来让函数减少;
然后固定,调整簇中心使减少。
这两个过程交替循环,单调递减:当递减到最小值时,和也同时收敛。
源码实现(含可视化)
导入包
import numpy as np
import matplotlib.pyplot as plt
数据预处理
设置地图尺寸
# map 100*100
high = 100
width = 100
创建随机数据
每一条数据的格式为,列表初始化为0,类别序数间隔1递增
data = np.random.rand(100, 2)
data = data * [high, width]
data = np.hstack((data, np.zeros([100, 1])))
定义簇数目
# count of classes
classes = 5
定义距离函数,此处我们使用欧氏距离
def distance(point1, center):
return np.sqrt((point1[0] - center[0]) ** 2 + (point1[1] - center[1]) ** 2)
定义从类别到颜色的映射函数,即
def color(i):
global classes
return i * 255. / classes
定义主函数
先将plt设置为连续作图模式
然后随机挑选簇中心点,并加入到中心点数组中
if __name__ == '__main__':
plt.ion()
# select center randomly
centers = np.random.randint(0, 100, [classes])
centers_data = []
for i in range(classes):
data[i][2] = i
centers_data.append(data[i])
先画散点图,且暂停0.5秒以显示迭代中的聚类情况。
while True:
colors = [color(x) for x in data[:, 2]]
plt.scatter(data[:, 0], data[:, 1], c=colors)
plt.pause(0.5)
先后依次迭代更新每个点所对应的簇,和每个簇的中心点。
# caculate nearest center
for i in range(100):
distances = np.array([distance(data[i], center_data) for center_data in centers_data])
i_class = np.argmin(distances)
data[i][2] = i_class
# caculate new center
new_centers_data = np.zeros([classes, 2])
new_centers_count = np.zeros([classes])
for j in range(5):
for i in range(100):
if data[i][2] == j:
new_centers_count[j] += 1
new_centers_data[j] += data[i][0:2]
计算五个簇的中心点位置先后变化的最大值,其值小于1e-4(可自定义)时,跳出循环,停止迭代。
new_centers_data /= np.array([new_centers_count]).T
dist = np.max([distance(new_centers_data[i], centers_data[i]) for i in range(classes)])
print('max distance ', dist)
if dist < 1e-4:
break
在每次迭代的最后更新中心点数据
centers_data = new_centers_data
最后关闭连续作图模式,并展示最后的图画,打印结束。
plt.ioff()
plt.show()
print('kmeans completed.')
效果
命令行
max distance 28.36595846126929
max distance 7.136259328045152
max distance 3.533885366585787
max distance 2.153654229308223
max distance 0.0
kmeans completed.
可视化过程
第1次迭代
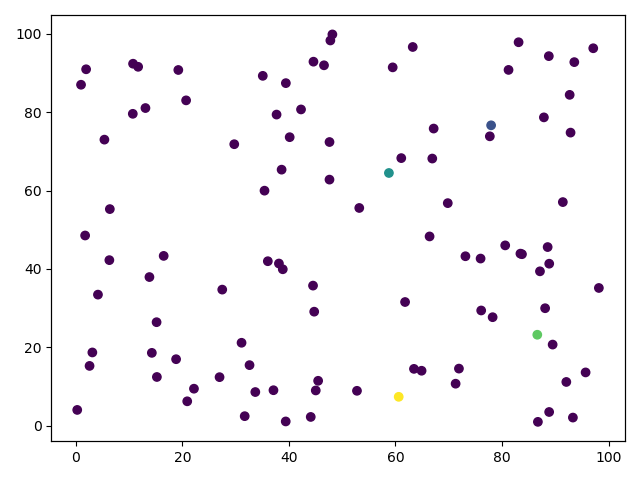
第2次迭代
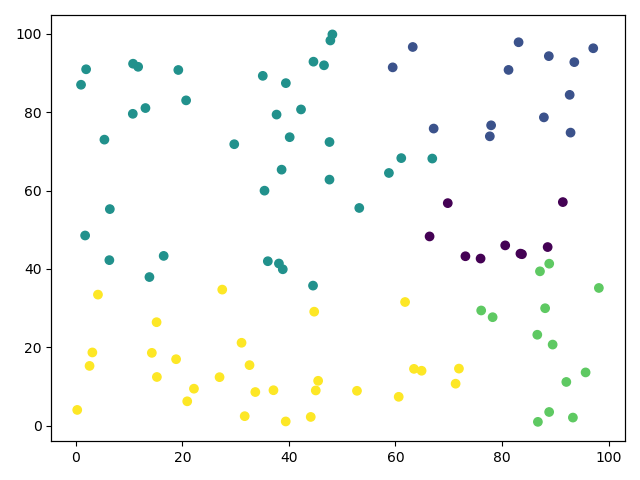
第3次迭代
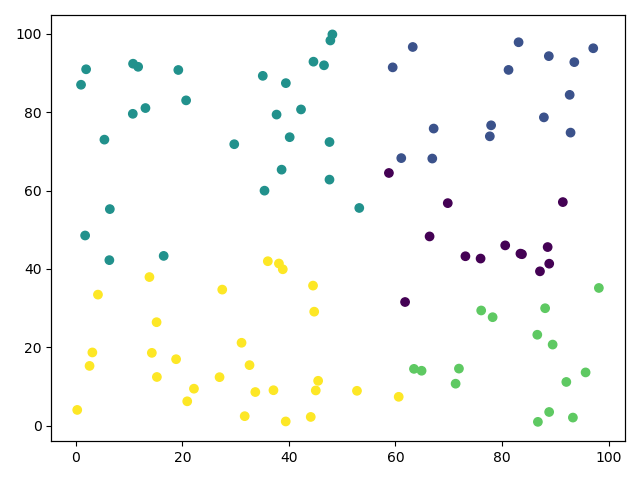
第4次迭代
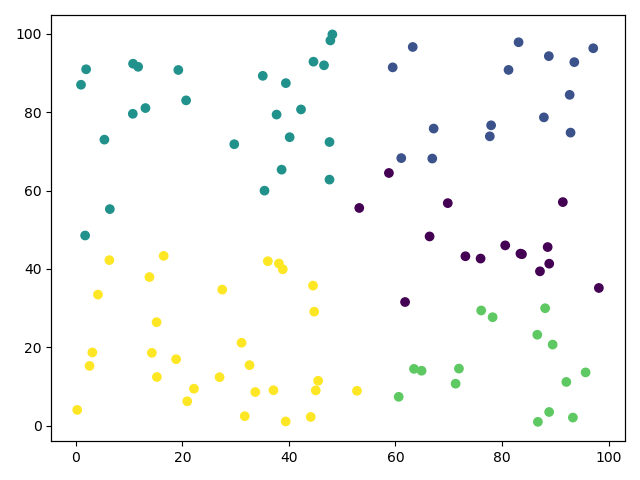
全部代码
import numpy as np
import matplotlib.pyplot as plt
# map 100*100
high = 100
width = 100
# create random data
data = np.random.rand(100, 2)
data = data * [high, width]
data = np.hstack((data, np.zeros([100, 1])))
# count of classes
classes = 5
def distance(point1, center):
return np.sqrt((point1[0] - center[0]) ** 2 + (point1[1] - center[1]) ** 2)
def color(i):
global classes
return i * 255. / classes
if __name__ == '__main__':
plt.ion()
# select center randomly
centers = np.random.randint(0, 100, [classes])
centers_data = []
for i in range(classes):
data[i][2] = i
centers_data.append(data[i])
while True:
colors = [color(x) for x in data[:, 2]]
plt.scatter(data[:, 0], data[:, 1], c=colors)
plt.pause(0.5)
# caculate nearest center
for i in range(100):
distances = np.array([distance(data[i], center_data) for center_data in centers_data])
i_class = np.argmin(distances)
data[i][2] = i_class
# caculate new center
new_centers_data = np.zeros([classes, 2])
new_centers_count = np.zeros([classes])
for j in range(5):
for i in range(100):
if data[i][2] == j:
new_centers_count[j] += 1
new_centers_data[j] += data[i][0:2]
new_centers_data /= np.array([new_centers_count]).T
dist = np.max([distance(new_centers_data[i], centers_data[i]) for i in range(classes)])
print('max distance ', dist)
if dist < 1e-4:
break
centers_data = new_centers_data
plt.ioff()
plt.show()
print('kmeans completed.')
智能推荐

机器学习之聚类算法(三)KMeans、KMeans++、KMeans||原理介绍及代码实现
K均值聚类(K-means)介绍 历史渊源 虽然其思想能够追溯到1957年的Hugo Steinhaus,术语“k-均值”于1967年才被James MacQueen首次使用。标准算法则是在1957年被Stuart Lloyd作为一种脉冲码调制的技术所提出,但直到1982年才被贝尔实验室公开出版。在1965年,E.W.Forgy发表了本质上相同的方法,所以这一算法有时被称为...

cv2机器学习-K均值聚类(KMeans)
本篇博客主要介绍cv2模块机器学习部分中的K均值聚类(KMeans)。 cv2.kmeans(data, K, bestLabels, criteria, attempts, flags, centers=None) 输入参数: data:np.float32类型的数据,每个特征应该放在一列。 K:聚类的最终数目。 bestLabels:预设的分类标签,没有的话就设置为None。 criteria...


CORDIC arithmetic
传统CORDIC算法code Verilog代码: 时钟为50Mhz; 输出设置均设置为有符号数,主要是因为计算CORDIC算法时,需要判断Z通道的符号,来得到迭代过程中旋转方向。 然后根据缩放因子和arctan 2^-n 的预定义并乘以2^16 来进行后续计算,根据迭代方程写出代码;最后将(0度到90度)中正弦值与余弦值来扩大至(0度至360度)的正弦值与余弦值。 编写的tb文件如下: 最终使用...
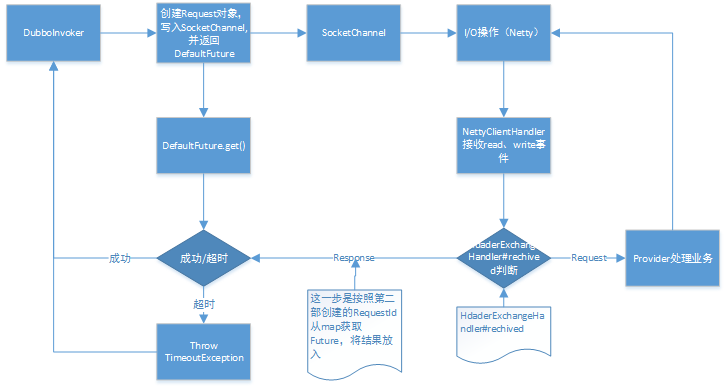
dubbo源码解析-线程通讯原理
本来想通过Debug从头屡,发现意义不大,还是写点主通讯流程吧 本文基于JDK1.8;dubbo2.7.5 线程通讯原理 解释总体流程: DubboInvoker#doInvoker(Invocation)发起request,进入HeaderExchangeChannel 初始化Request对象(Dubbo自己封装的),初始化DefaultFuture将Request、channel放入,并记录...
猜你喜欢

使用Intellij Idea+Gradle 搭建Java 本地开发环境
Java 本地开发环境搭建 项目搭建采用技术栈为:Spring+Spring MVC+Hibernate+Jsp+Gradle+tomcat+mysql5.6 搭建环境文档目录结构说明: 使用Intellj Idea 搭建项目过程详解 项目各配置文件讲解及部署 各层包功能讲解&项目搭建完毕最终效果演示图 项目中重要代码讲解 5.配置tomcat 运行环境 6.webapp文件夹下分层详解 ...
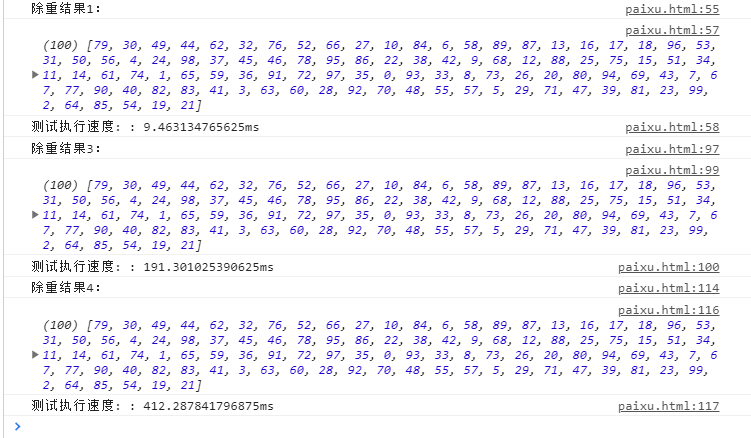
js中array数组除重最快的方式(100万数据量下测试)
模拟100万数据 测试1 for循环 + in 运算符 (不是 for…in 循环) 测试2 双层for循环 (太慢了) while …同理。 测试3 for循环 + arr.indexof()判断 测试4 for…in循环 + in 运算符 测试结果...
轻量级java服务器undertow
项目需求 服务器端项目是用mina写的传统socket,准备升级到支持websocket接入。 为什么采用undertow 1、Undertow 是基于 NIO 的高性能 Web 嵌入式服务器,并且支持websocket(这个很重要,只要把undertow集成到项目中,用undertow启用websokcet,然后把原来的socket切换到websocket。) 2、轻量级web服务器:多么轻量级...
Task01:基于逻辑回归的分类预测
逻辑回归模型的优劣势: 优点:实现简单,易于理解和实现;计算代价不高,速度很快,存储资源低; 缺点:容易欠拟合,分类精度可能不高 https://zhuanlan.zhihu.com/p/74874291 与 SVM 相同点 都是分类算法,本质上都是在找最佳分类超平面; 都是监督学习算法; 都是判别式模型,判别模型不关心数据是怎么生成的,它只关心数据之间的差别,然后用差别来简单对给定的一个数据进行...
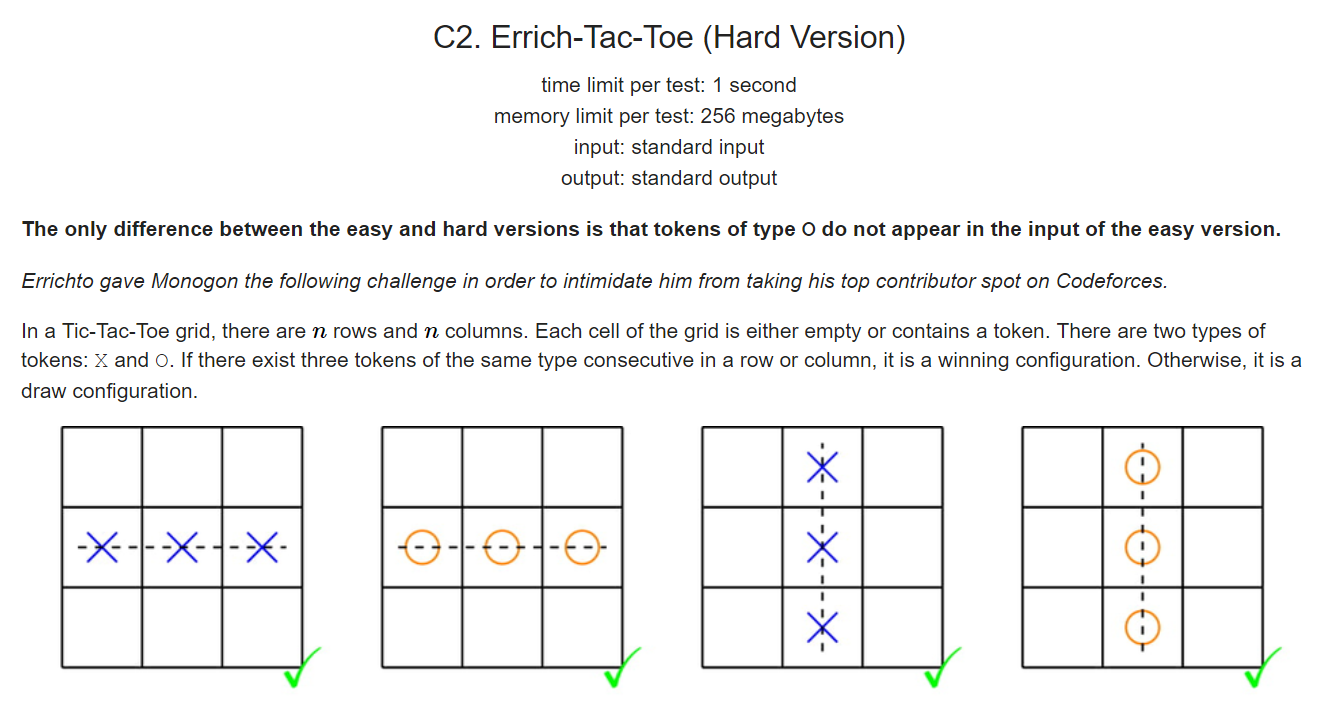
Codeforces Global Round 12 C2. Errich-Tac-Toe (Hard Version)(思维)
C2. Errich-Tac-Toe (Hard Version) 题意:给一个矩阵,里面有 k 个 'X' 或 'O' 标记,现在要修改不超过 k / 3 个标记('X'改成'O','O'改成'X'),使得矩阵中没有三个连续的相同的标记 思路:对两种不同的标记分别修改(i + j)% 3 == opx,(i + j) % 3 == opo 的位置,前提是修改的个数要少于总标记数的三分之一,所以枚...