基于Xilinx FPGA的AXI Direct Memory Access (Scatter Gather Engine模式) 行为分析及软件操作流程
1、引言
我们在FPGA上进行数据处理或者信号处理时,通常会遇到从片上存储器RAM读取数据至片内,或者将片内的结果直接暂存至片外的RAM。其中以Xilinx家的DMA控制器(英文全称:AXI Direct Memory Access)的读取功能(Read Channel)为例,能够通过AXI总线读取某个地址区间的数据,同时再将这些数据转换以数据流的形式传输至处理单元。典型的AXI Direct Memory Access(IP核)配置界面如下图所示。
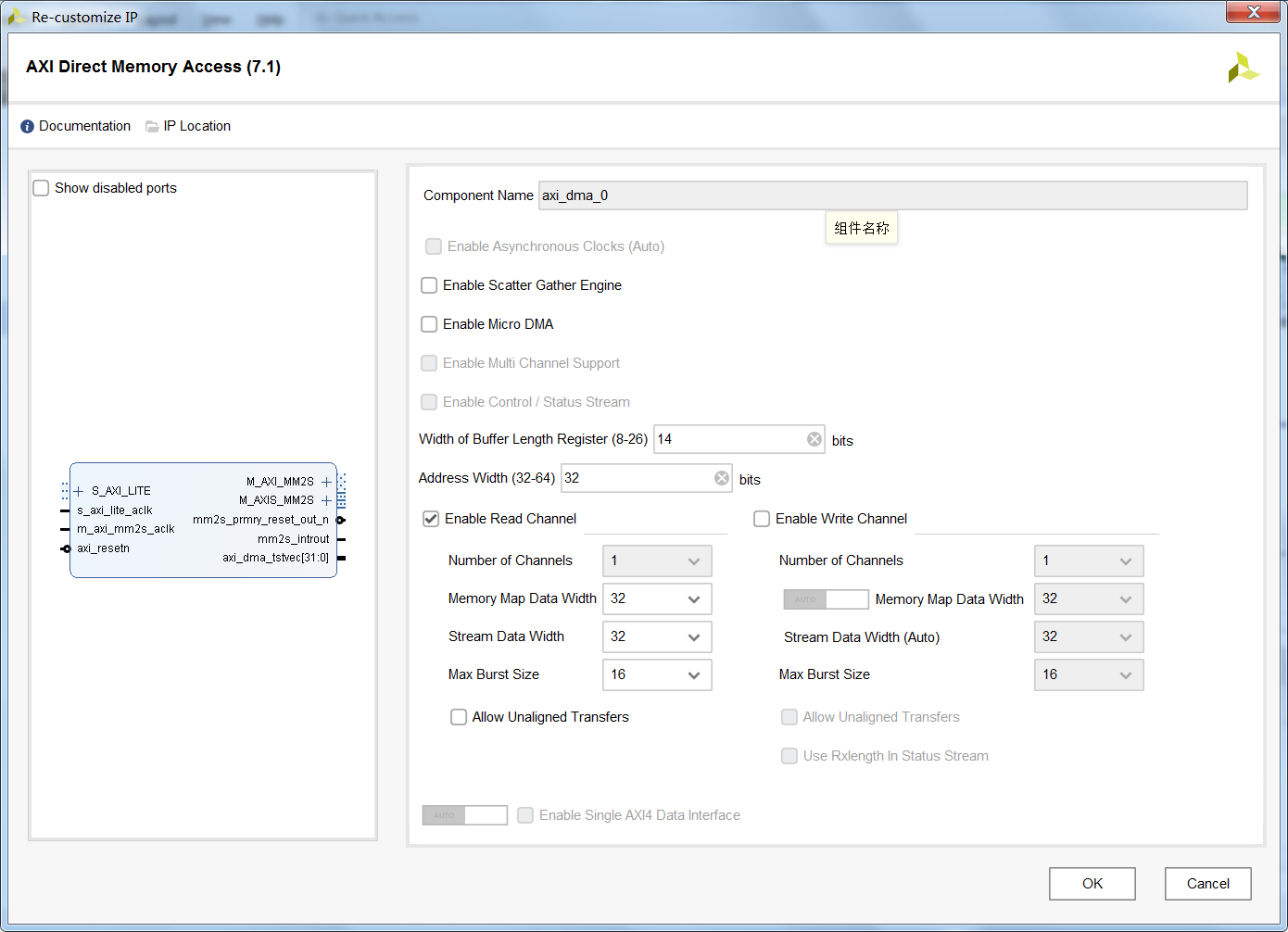
从图中可以看出,普通模式的DMA具备以下特性:
①AXI Memory Map总线地址位宽可选32bit或64bit;
②Buffer Length最大位宽为26,对应的单次传输大小最大为64MByte;
③同时支持读通道和写通道,并且每个通道的AXI Memory Map数据位宽可配置,Stream数据流接口的位宽可配置,用于AXIMemory Map的突出传输长度可配置,同样也允许未对齐数据的传输;
那么根据上述的总结可以看出,普通模式的DMA对于解决简单的数据传输,完全能够应付。但是当面向大规模数据(单次传输>64MByte),或需要操作的地址不连续时,普通模式的DMA不能够满足要求,即便能够将大规模数据分割为多个<64MByte的片段,但是这个过程需要额外的处理器(例如ARM/NIOS/MicroBlaze/RISC-V)进行查询监测,或者启用中断函数,这样额外的消耗了处理器性能(我们期望的是一次配置,永久使用)。对于这样的问题,通常启用该IP核的高级功能——Scatter Gather (SG) Engine模式,虽然单个传输片段依然有64MByte的限制(取决于Buffer Length Width),但是我们可以把一片>64MByte的数据划分为多个<64MByte的区域来解决。并且在此基础上,我们需要传输的数据有多个地址不连续的片段,同样也能够完美解决。其中开启Scatter Gather Engine后,IP核的接口如下图所示。与普通模式的DMA相比,多了一根M_AXI_SG总线(这个总线稍后我会单独介绍)。
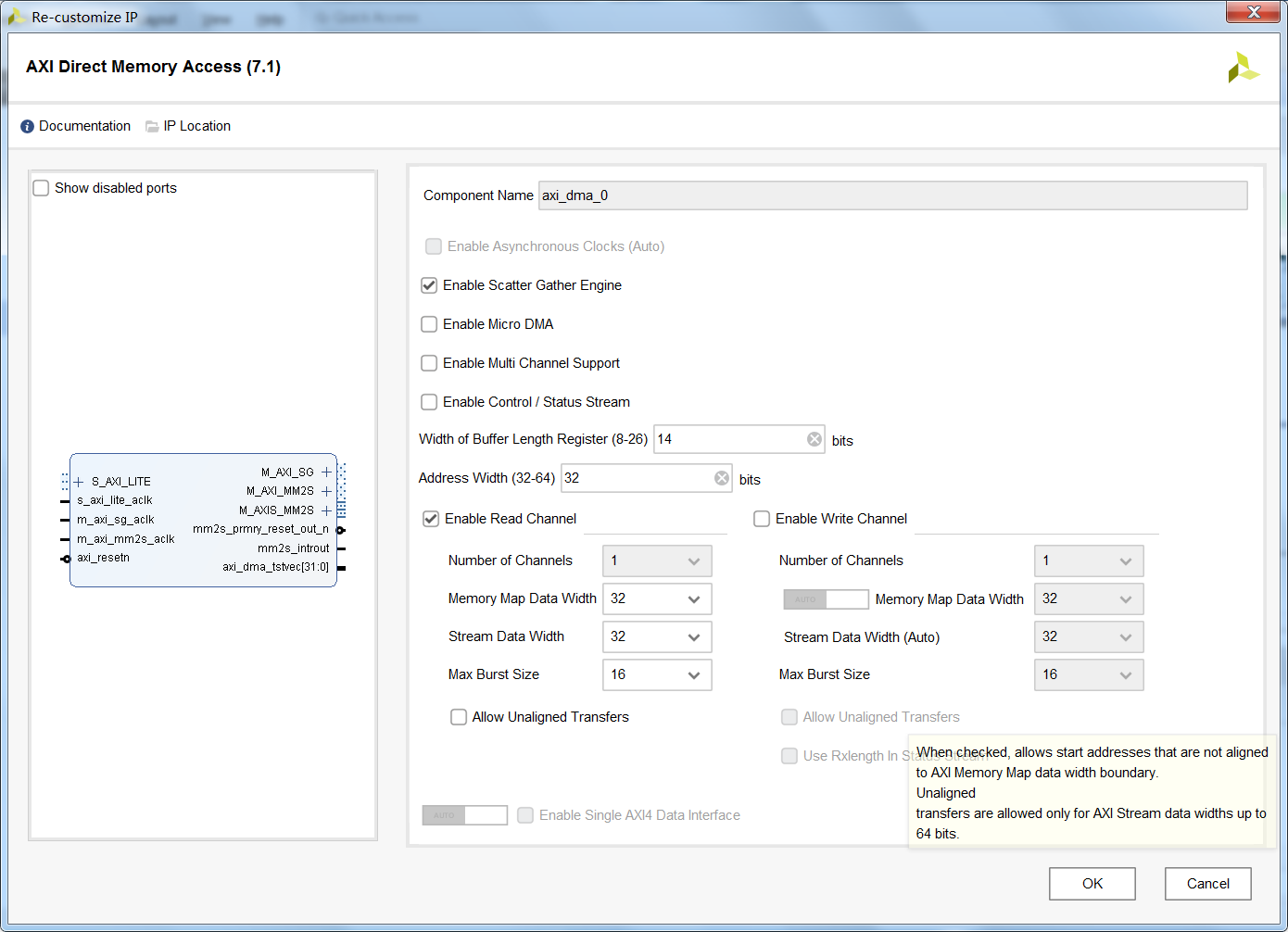
(那么可能有的读者开始杠了:对于这种特殊的DMA,我完全可以用Vivado HLS自己写一个特殊的数据传输过程,没必要用SG DMA。我一开始也是这么想的,功能上倒没什么问题,但是基于笔者菜鸡的VivadoHLS功底,发现传输效率实在是太差了,尤其是地址切换的时候,需要花费大量的时钟周期用于发起AXI传输请求,这样导致我后面的数据处理单元性能受限于数据传输的性能。再后来我发现官方对于这类需求已经在给定的DMA IP核中做好了,数据传输效率极高,尤其是单次传输多个数据,中间的那点延迟几乎可以忽略不计,真香~)
但是,官方的软件IP核功能是如此的牛逼,但是给定的软件代码配置过程却又像是一坨Shit一样,我看了下官方提供裸机(Baremetal)下的SG DMA驱动例程,洋洋洒洒好几千行代码,愣是把我给看懵了。没办法,为了带宽不拖数据处理单元的后腿,硬着头皮看一下官方给的Product Guide(就在IP核配置界面的左上角Documentation地方)。不得不说,官方给的数据手册还是挺详细的,对于IP核怎么使用,以及需要注意的事项,写的清清楚楚。虽然是英文的,但是鉴于笔者还是有过好几篇SCI论文写作的经历,对于看这类文档还是没有什么问题,基本上都能看得懂。
因此,为了能够方便的使用SG DMA,本文从SG DMA的运行行为分析入手,介绍SG DMA的驱动软件操作流程,并在此基础上对其性能进行优化。本文的主要内容如下:
①根据Product Guide介绍SG DMA的运行行为及其注意事项;
②根据运行行为编写裸机(Baremetal)环境下应用程序;
③根据初步实验结果分析多个DMA传输间隔周期较长的原因,提出改进策略并对比结果。
由于笔者能力有限,介绍过程中不可避免存在一部分设计不足的问题。本文主要是为SG DMA的使用方法提供一种设计思路,希望能够以本人的一得之见,起到抛砖引玉的作用。
2、SG DMA运行过程分析
在这里先介绍一下SG DMA的一个大概的工作过程。上一节的介绍中提到SG DMA与普通DMA相比多了一根M_AXI_SG总线,这根总线其实是SG DMA的关键点。运行过程如下:
①DMA控制器通过M_AXI_SG总线读取Scatter Gather Descriptor(以下简称为描述符),描述符没有集成在IP核中,需要在内存中进行定义;
②接着对该Descriptor(描述符)进行解析,根据解析到的内容开启单次传输;
③读取的描述符中包含了下一个描述符的地址,在当前传输完成后读取下一个描述符;
④往复循环上述过程,直到读取到最后一个描述符,停止数据传输。
其中描述符内容的定义如下(pg021_axi_dma v7.1, page38):
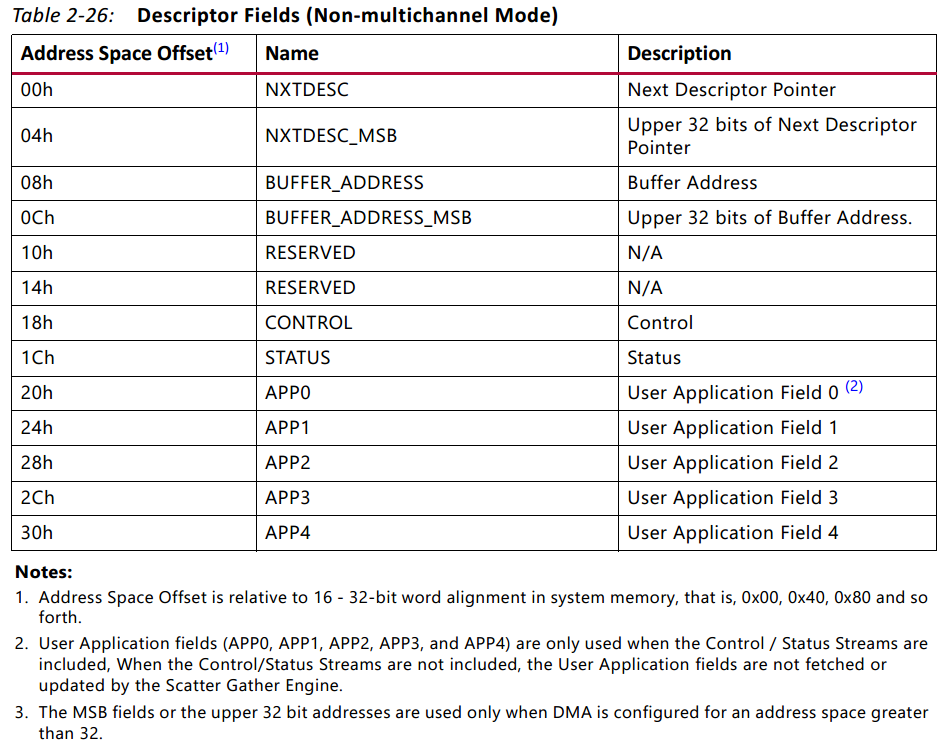
其中我们比较关心的地方有:00h和04h为下一个描述符在内存中的地址;08h和0Ch为待传输数据在内存中的地址;18h为控制寄存器,其中Bit0~Bit25为传输长度,Bit26表示当前描述符是否为最后一帧(高有效),Bit27表示当前描述福是否为第一帧(高有效)。需要特别注意的是第一条注意事项:描述符必须为16个字,即64字节对齐。
介绍完描述符以后,接下来介绍SG DMA内部自带的寄存器,其中SG DMA内部寄存器如下图所示(pg021_axi_dma v7.1, page12):
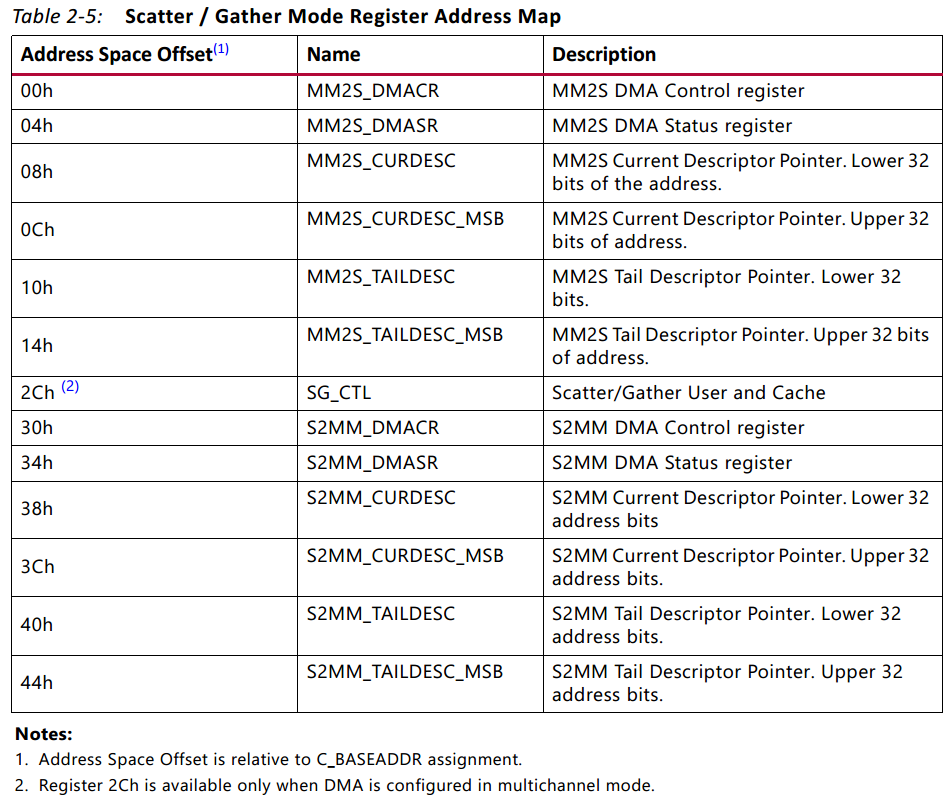
以Read Channel(即MM2S)为例,我们需要关注的寄存器包括:00h控制寄存器,用于控制SG DMA的启动、停止、复位、循环模式、中断开启等;04h状态寄存器,查询停止、空闲、中断错误类型等;08h和0Ch当前描述符的地址;10h和14h尾描述符的地址,也就是结束描述符的地址。同理,Write Channel(S2MM)寄存器与之相同,剩下的其他寄存器暂时用不到。
因此,根据上述寄存器的介绍,依据描述的定义在内存中完成描述符编写,然后再将描述符存储的地址写入至SG DMA(IP核)的寄存器中,最后开启数据传输即可。中间过程支持对SG DMA运行状态的查看。
3、SG DMA软件操作流程
依据Product Guide的描述,完成软件操作流程。该步骤可以直接使用官方给的驱动程序示例,但是笔者觉得太繁琐了,而且代码量实在是太大了,于是乎笔者决定自己写一个软件驱动。
在写软件驱动之前,强烈建议查阅下官方给出的操作流程,并严格按照流程的规范来,要不然程序运行步起来。(一开始笔者根据自己的经验写了一版驱动,但是发现完全运行不起来,后面发现手册给出了操作流程说明,更改后才能运行)其中操作流程如下所示(pg021_axi_dma v7.1, page73):

假如我们已经在内存中完成了描述符的定义,根据上述流程,翻译成中文就是下面的步骤:
①将起始描述符的地址写入当前描述符寄存器(08h和0Ch);
②通过控制寄存器(00h)启动DMA传输,必要的时候可以检查下状态寄存器(04h)的Halted标志位,用来查看DMA是否开始运行;(如果需要运行在Keyhole或Cyclic模式,需要在②之前进行设置)
③如果需要的话,通过控制寄存器(00h)对中断进行设置;
④写入一个有效的地址到尾描述符(10h和14h)寄存器,一般是将尾描述符的地址写到这个里面;
⑤写入尾描述寄存器将会触发DMA从内存中读取第一个描述;对于多通道模式下,多个描述符的读取将会在S2MM通道接收到数据包以后开始;
⑥读取到的描述符开始被解析,要传输的数据从内存中读取,然后输出到MM2S的数据流通道上。
看了上述过程,是不是觉得很奇葩,先写起始描述符寄存器,然后要先开启DMA传输,最后由写入尾描述符寄存器触发传输。这和我们传统的写完所有的描述符地址,然后通过控制寄存器触发DMA传输完全不一样,一开始笔者就是因为这种固定思维,导致迟迟无法启动DMA传输。对于官方给出的这种操作流程,真的是让笔者大开眼界。
那么基于上述操作,我们可以编写出如下的代码:
1 // @Time : 2021.07.22
2 // @Author : wuruidong
3 // @Email : [email protected]
4 // @FileName: sdk_main.c
5 // @Software: Xilinx SDK 2018.3
6 // @Cnblogs : https://www.cnblogs.com/ruidongwu
7 #include "xaxidma.h"
8 #include "xaxidma_hw.h"
9
10 #define AXI_DMA_ADDR XPAR_AXI_DMA_0_BASEADDR
11
12 typedef struct
13 {
14 u32 next_desc; //00h
15 u32 next_desc_msb; //04h
16 u32 buffer_addr; //08h
17 u32 buffer_addr_msb; //0ch
18 u32 reserved[2]; //10h & 14h
19 u32 ctrl; //18h
20 u32 status; //1ch
21 u32 app[5]; //20h 24h 28h 2ch 30h
22 u32 aligned[3];
23 }SG_Desc; //aligned to 64
24
25 SG_Desc DMA_Desc[3] __attribute__ ((aligned (64)));
26
27 void DMA_Desc_Init(void)
28 {
29 memset(DMA_Desc, 0, sizeof(DMA_Desc));
30
31 //start
32 DMA_Desc[0].next_desc = (INTPTR)(&(DMA_Desc[1]));
33 DMA_Desc[0].buffer_addr = (INTPTR)(data0);
34 DMA_Desc[0].ctrl = sizeof(data0)|XAXIDMA_BD_CTRL_TXSOF_MASK;
35
36 DMA_Desc[1].next_desc = (INTPTR)(&(DMA_Desc[2]));
37 DMA_Desc[1].buffer_addr = (INTPTR)(data1);
38 DMA_Desc[1].ctrl = sizeof(data1);
39
40 //end
41 DMA_Desc[2].next_desc = (INTPTR)(&(DMA_Desc[0]));//Any address
42 DMA_Desc[2].buffer_addr = (INTPTR)(data2);
43 DMA_Desc[2].ctrl = sizeof(data2)|XAXIDMA_BD_CTRL_TXEOF_MASK;
44
45 Xil_DCacheFlushRange((INTPTR)DMA_Desc, sizeof(DMA_Desc));
46 }
47
48 void DMA_Init(void)
49 {
50 // reset
51 Xil_Out32(AXI_DMA_ADDR+XAXIDMA_CR_OFFSET, XAXIDMA_CR_RESET_MASK);
52 usleep(1000);
53
54 //disable all interrupt
55 Xil_Out32(AXI_DMA_ADDR+XAXIDMA_CR_OFFSET, Xil_In32(AXI_DMA_ADDR+XAXIDMA_CR_OFFSET)&(~XAXIDMA_IRQ_ALL_MASK));
56 //It can be ignored due to system reset;
57
58 //set DMA_Desc address
59 Xil_Out32(AXI_DMA_ADDR+XAXIDMA_CDESC_OFFSET, (UINTPTR)(&(DMA_Desc[0])));
60
61 //start
62 Xil_Out32(AXI_DMA_ADDR+XAXIDMA_CR_OFFSET, Xil_In32(AXI_DMA_ADDR+XAXIDMA_CR_OFFSET)|XAXIDMA_CR_RUNSTOP_MASK|XAXIDMA_CR_CYCLIC_MASK);
63
64 //It can be ignore.
65 while(1)
66 {
67 if((Xil_In32(AXI_DMA_ADDR+XAXIDMA_SR_OFFSET)&XAXIDMA_HALTED_MASK)==0)
68 break;
69 }
70
71 //trigger
72 Xil_Out32(AXI_DMA_ADDR+XAXIDMA_TDESC_OFFSET, (UINTPTR)(&(DMA_Desc[2])));
73 }
74
75 u32 DMA_Status(void)
76 {
77 return Xil_In32(AXI_DMA_ADDR+XAXIDMA_SR_OFFSET)|XAXIDMA_HALTED_MASK;
78 }上述代码中包含了描述符的定义、描述符的初始化、DMA的启动过程以及查询DMA的运行状态,其中完整的代码下载链接在文章末尾。
4、工程搭建与初步测试结果
根据上述步骤我们在Vivado中构建Block Design,然后在Diagram中按照下图的方式进行连接,其中本文把SG DMA设置为读取通道(即MM2S)。DMA输出接口的M_AXIS_MM2S的m_axis_mm2s_tready强制设置为1(表明输出一直有效),然后再添加内嵌逻辑分析仪System ILA抓取输出信号,查看传输过程中的数据是否正确及传输状态变化。
-----------------------------------
基于Xilinx FPGA的AXI Direct Memory Access (Scatter Gather Engine模式) 行为分析及软件操作流程
https://blog.51cto.com/u_15127661/4147263
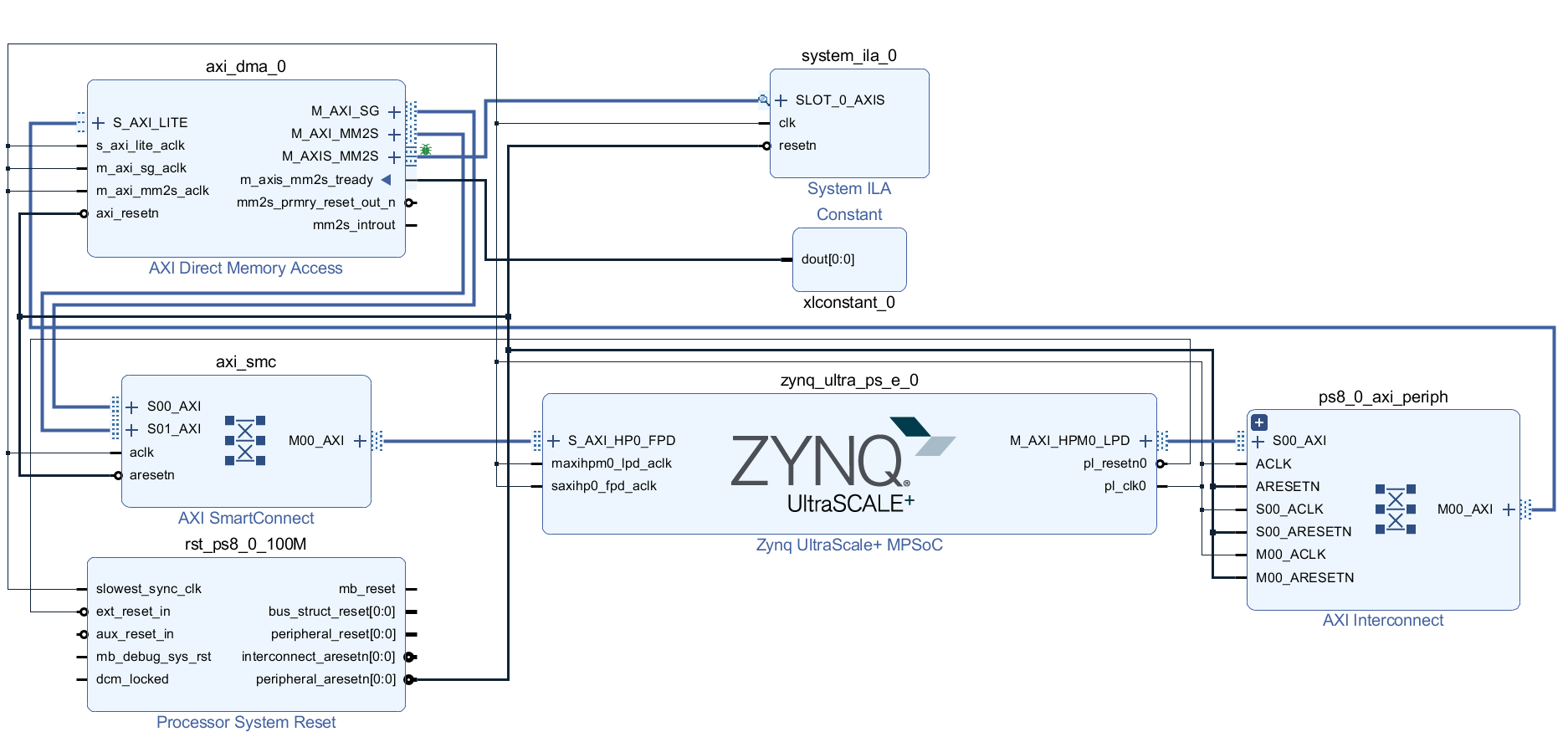
在这里声明笔者开发过程中遇到的一个坑,AXI Direct Memory Access在配置的过程中,千万不要勾选使用Micro DMA模式 ,除非你传输的数据量特别特别小,主要原因见下图(pg021_axi_dma v7.1, page41)。

虽然我们可以在配置界面上看到勾选了Micro DMA并不会对接口有任何的影响,但是能够支持的最大传输长度有了限制。笔者猜测Micro DMA模式的意义是:传输的长度刚好满足MM2S接口的单次突发传输。所以有了上述限制。
经过上述的一系列操作以后,我们其实可以生成比特流文件,然后导出硬件和比特流到SDK中,编写裸机下的驱动程序。实验测试过程,本文分别定义了Data0、Data1和Data2三组数据,数据类型为32位有符号整形,数据长度分别为16、32和64。另外为了方便测试,本文对SG DMA采用Cyclic循环模式(如何启用Cyclic模式将会在文末的附录中描述)。通过查看传输过程中单次传输是否存在不连续的情况,同时分别查看两组数据之间的空闲周期,即为切换传输所需要的周期。如果切换的周期越短,那么传输的效率越高效,反之效率越差。
逻辑分析仪抓取结果中,由于数据传输比较短,单组数据传输过程中没有发生不连续的情况,而多组数据间所消耗的额外时钟周期如下表所示:

通过对表格的结果可以看出,开始阶段中描述符所对应的数据段切换所消耗的周期比较多,随着数据段切换次数的增加,中间所消耗的周期降低并保持稳定。其中切换周期为0的原因可能是Data2与Data0在内存上地址处于连续状态,可以不用考虑。则数据段的切换所消耗的最小周期为20个时钟周期。
我们可以发现SD DMA的工作流程先通过M_AXI_SG总线从指定地址中读取描述符,读取后对描述符进行解析,然后再启动数据读取。那么在切换的周期中,所消耗的是否包括:M_AXI_SG读取时间、解析时间、M_AXI_MM2S读取时间。笔者分析后发现,M_AXI_SG是从片外的DDR中进行描述符的读取,那么该过程可能需要消耗大量的时钟周期,因此本文接下来针对M_AXI_SG做专门的优化设计。
5、M_AXI_SG优化与实验结果
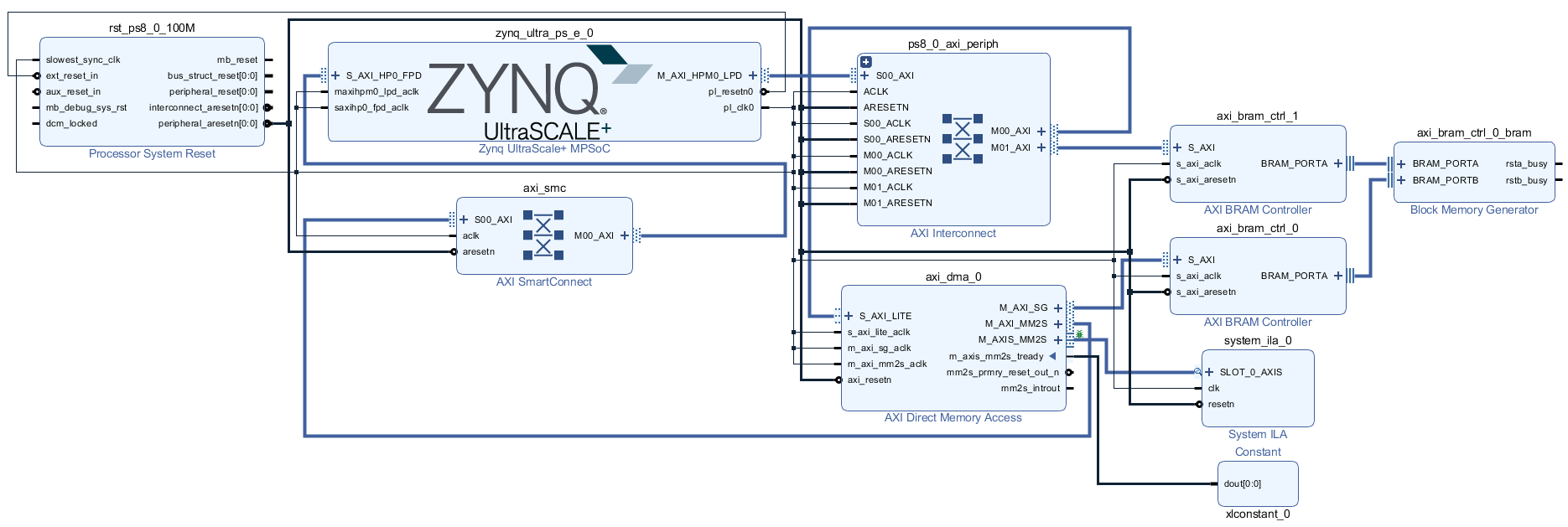
根据对AXI Memory Map总线协议的分析,发起单次数据传输需要先发送地址信息和突发传输长度,然后等待总线响应,握手成功后返回读取到的数据。正常运行环境下,存在有多个主设备请求访问DDR,通过总线仲裁后再进行数据传输,上述实验还是只有一个主机工作条件下的延迟,实际应用中如果存在有其他设备,数据段切换所引起的额外时钟周期消耗还会增加。因此,如果将M_AXI_SG独立分配总线,甚至可以将描述符直接存储在片上的BRAM中,那么将会极大的减少M_AXI_SG总线所引起的时钟周期延迟。因此本文针对上述系统进行优化,优化后的Diagram如下图所示。
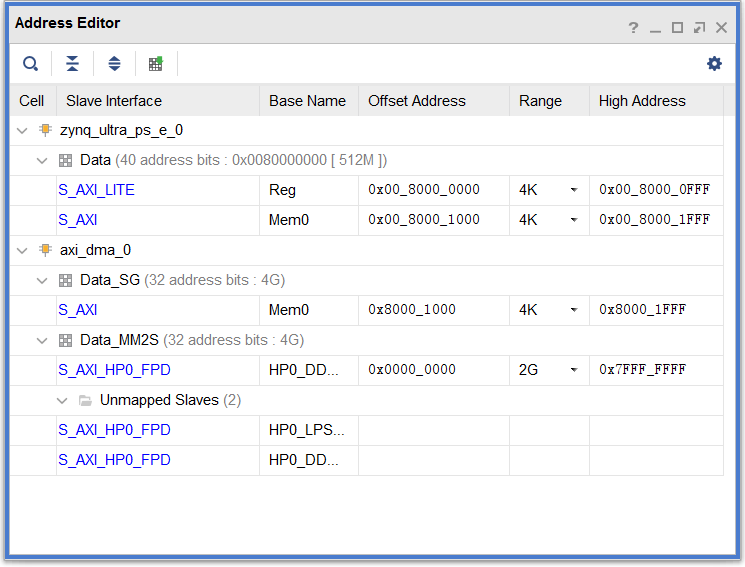
其中对应的地址分配如下图所示,我们给BRAM分配的地址空间大小为4K,起始地址为0x8000_0000,需要注意的是在Data_SG分配的地址区间内,只保留BRAM对应的S_AXI mem0一个地址区域,去除其他区域,否则在Validate Design中将会报错。
经过上述改进后,重新生成比特流,并通过逻辑分析仪抓取M_AXIS_MM2S总线数据(SDK程序源码在文末给出)。其中数据段切换之间的周期数如下表所示:
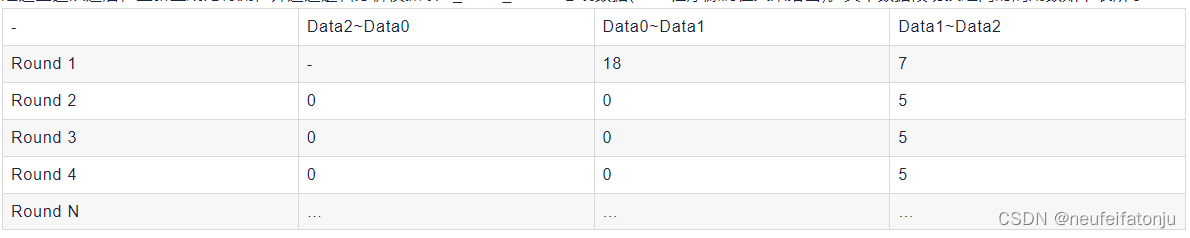
通过对比可以看出,在数据传输稳定后,数据段切换的时钟周期间隔稳定在5个时钟周期,与SG DMA默认的从片外DDR中读取描述符相比,周期间隔出现大大的减少,即传输的效率得到了提升,这也对后续的数据处理单元的高效性进行了保障,使得数据处理单元的性能不再受带宽传输效率的影响,尤其是在需要多个数据段之间多次切换的场景,保证了传输的高效性。
6、总结
本文针对于AXI Direct Memory Access的Scatter Gather模式中的读取通道进行了行为分析,并完成了逻辑状态下的操作流程的软件代码编写。同时本文采用了基于片内BRAM存储的独立M_AXI_SG传输总线方法,解决了多个数据段之间切换存在的时钟周期较长的问题,从而提升了数据传输效率。本文所采用的软件流程同样适用于其他具备Scatter Gather DMA传输需求的IP核软件编写,所提优化方法同样可适配至其他需要提升总线传输效率的场合。
附录(Scatter Gather DMA的Cyclic模式):
Cyclic模式主要是用在数据处理模块对数据有循环需求的场合。例如在卷积神经网络加速应用中,当网络对多张连续的输入图像进行卷积,需要循环从片外DDR中加载权重数据数据至片内,然后与输入图像或特征图进行卷积操作。根据Xilinx官方提供的手册可以看出Cyclic模式的介绍如下(pg021_axi_dma v7.1, page74):
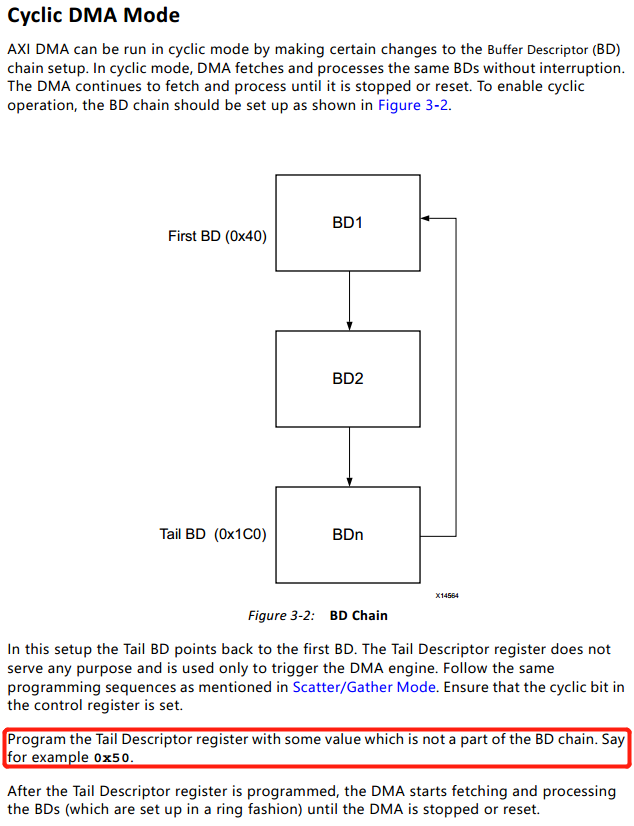
翻译成中文,进入Cyclic模式的操作步骤如下(假如已经在内存中完成对描述符的赋值操作):
①使能MM2S_DMACR控制寄存器的Bit4(Cyclic BD Enable);
②将起始描述符的地址写入当前描述符寄存器;(该步骤与①的顺序可以调换)
③通过控制寄存器(00h)启动DMA传输;
④随便写一个地址到尾描述符寄存器,只要不与上面的描述符地址重合就行;(对,你没看错,随便写啥都可以)
⑤DMA开始运行和传输数据,在这个过程除非主动通过控制寄存器停止DMA或者复位,其他条件都不会让DMA停下来。
-----------------------------------
基于Xilinx FPGA的AXI Direct Memory Access (Scatter Gather Engine模式) 行为分析及软件操作流程
https://blog.51cto.com/u_15127661/4147263
智能推荐


UnityShader 屏幕特效 模糊
上一篇文章写了屏幕特效必须的几个要素,这边通过一个 脚本继承与PostEffectsBase .以及通过shader 交互实现屏幕模糊特效。 下面通过添加在摄像机,引用3的shader。 3.下面Shader 4.简单介绍Category :就是同一个Shader,如果下面有多个Shader的话,都会套用下面这一套 5.简单讲一下这个算法,这个通过在片元着色器进行上下左右进行像素微偏移 原图 模糊...

seaborn调用load_dataset函数时出现URLError
seaborn调用load_dataset函数时出现URLError: <urlopen error [Errno 11004] getaddrinfo failed> 在使用seaborn调用load_detaset函数时一直出现错误 出现 URLError: <urlopen error [Errno 11004] getaddrinfo failed> 解决办法。 查...
Sa-Token 一个轻量级Java权限认证框架
文章目录 Sa-Token 简介 基础使用 框架集成 添加Sa-Token依赖 配置Sa-Token 配置项解读 sa-token cookie 单点登录 OAuth 2.0 登录认证 认证流程 登录与注销 其他操作语句 权限认证 获取当前账户的权限码集合 权限认证 角色认证 全局异常捕获 权限通配符 踢人下线 强制注销 踢人下线 账号封禁 注解鉴权 1.注册注解拦截器 2.使用注解鉴权 路由鉴权...
平时瞎折腾之Docker
平时瞎折腾之Docker 由于平时在学校学习和使用的数据库大多数都是使用的mysql,但是进入工作中时,由于不同的项目会使用到像Oracle,Sql Server这样的数据库操作。虽说sql的基础语法都差不多,但具体使用起来还是有很大的差异。于是就想着装个Oracle数据库学习一下,但是由于我之前把电脑换成了Mac,这就很让人头疼。之前的解决方法是使用parallels安装windows虚拟机,然...
猜你喜欢
构建虚拟Web主机(基于域名、端口和IP)
文章目录 虚拟主机简介 基于域名的虚拟主机 基于端口的虚拟主机 基于IP的虚拟主机 虚拟主机简介 ●虚拟Web主机 在同一台服务器中运行多个Web站点,其中每一个站点并不独立占用一台真正的计算机 ●httpd支持的虚拟主机类型 基于域名的虚拟主机 基于IP地址的虚拟主机 基于端口的虚拟主机 (基于域名和端口的生产环境用的多) 基于域名的虚拟主机 示例:构建2个虚拟Web站点 www.test.co...
使用C#操作EXCEL文件
文章目录 1.在项目中引用Microsoft Excel 12.0 Object Lib这个COM组件,如图所示。 2. 在命名空间中添加引用,完整的引用如图所示。 3.打开、关闭Excel文件 4. 获取工作表 5. 删除工作表 6. 对EXCEl工作表的行列进行操作 7. 对EXCEL文档中的单元格进行操作 完整代码 1.在项目中引用Microsoft Excel 12.0 Object Li...
Python学习-Python编程环境搭建
ps:以下内容纯属上课学习的笔记整理,不做商业用途,无侵犯版权的想法。 1 认识Python 1.1 Python的介绍 官方介绍:Python 是一款易于学习且功能强大的编程语言。 它具有高效率的数据结构,能够简单又有效地实现面向对象编程。Python 简洁的语法与动态输入之特性,加之其解释性语言的本质,使得它成为一种在多种领域与绝大多数平台都能进行脚本编写与应用快速开发工作的理想语言。 名称的...

VTK之类的实现
vtkObject类分析 vtkObjectBase主要实现引用计数,因此vtkObject及其子类也都继承了该特性。vtkObject中实现了在VTK中非常广泛使用的观察者/命令机制,能够方便地处理消息响应,例如处理鼠标消息、键盘消息、进度消息等,VTK中Widget中大量使用了该机制进行消息处理。vtkObject中定义了一个vtkSubjectHelper对象来管理观察者。vtkSubj...
Ubuntu19.10使用Qemu安装树莓派
文章目录 Ubuntu19.10使用Qemu安装树莓派 安装 安装qemu 安装树莓派 图形化界面 下载 参考文献 Ubuntu19.10使用Qemu安装树莓派 之前一直是在Windows下鼓捣虚拟机,这次试试qemu 安装 安装qemu 安装树莓派 在github上找到相应版本的内核和设备树文件。 先创建一个项目目录,把镜像文件、设备树文件,和内核文件都放进去 然后fdisk -l 2020-0...