[分布式监控CAT] Server端源码解析——消息消费\报表处理\展示
前言
Server端
(Cat-consumer 用于实时分析从客户端提供的数据\Cat-home 作为用户给用户提供展示的控制端
,并且Cat-home做展示时,通过对Cat-Consumer的调用获取其他节点的数据,将所有数据汇总展示)
consumer、home以及路由中心都是部署在一起的,每个服务端节点都可以充当任何一个角色
Client端
(Cat-client 提供给业务以及中间层埋点的底层SDK)
相关文章:
[分布式监控CAT] Server端源码解析——初始化
[分布式监控CAT] Client端源码解析
[分布式监控CAT] Server端源码解析——消息消费\报表处理
上文说到了CAT-Server的启动初始化。
接着我们要分析一下CAT-Server如何接受各个客户端上报(TCP长连接)的消息,以及如何消费、解析、存储等等
先来看一下CAT整体的架构图:

消费、解析
com.dianping.cat.analysis.TcpSocketReceiver
在上一篇文章中说过了服务端的启动,在CAT-Server启动时会启动Netty的Nio 多线程Reactor模块来接收客户端的请求:
一个Accept线程池(Main Reactor Thread Pool )用来处理连接操作(通常还可以在这各Accept中加入权限验证、名单过滤逻辑);
接着Accept连接成功的socket请求被转发到 专门处理IO操作的线程池(Sub Reactor Thread Pool ,实现异步);在这里做了消息的解码处理;
再接着,解码处理后,将消息发送到每个报表解析器内置的内存队列中。消息将被异步分发给各个解析器单独处理(不存在数据竞争)。
消息的接受是在这个类TcpSocketReceiver.java完成的:
// 在CatHomeModule启动时被调用
public void init() {
try {
startServer(m_port);
} catch (Throwable e) {
m_logger.error(e.getMessage(), e);
}
}
/**
* 启动一个netty服务端
* @param port
* @throws InterruptedException
*/
public synchronized void startServer(int port) throws InterruptedException {
boolean linux = getOSMatches("Linux") || getOSMatches("LINUX");
int threads = 24;
ServerBootstrap bootstrap = new ServerBootstrap();
//linux走epoll的事件驱动模型
m_bossGroup = linux ? new EpollEventLoopGroup(threads) : new NioEventLoopGroup(threads);//用来做为接受请求的线程池 master线程
m_workerGroup = linux ? new EpollEventLoopGroup(threads) : new NioEventLoopGroup(threads);//用来做为处理请求的线程池 slave线程
bootstrap.group(m_bossGroup, m_workerGroup);
bootstrap.channel(linux ? EpollServerSocketChannel.class : NioServerSocketChannel.class);
bootstrap.childHandler(new ChannelInitializer<SocketChannel>() {//channel初始化设置
@Override
protected void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast("decode", new MessageDecoder());//增加消息解码器
}
});
// 设置channel的参数
bootstrap.childOption(ChannelOption.SO_REUSEADDR, true);
bootstrap.childOption(ChannelOption.TCP_NODELAY, true);
bootstrap.childOption(ChannelOption.SO_KEEPALIVE, true);
bootstrap.childOption(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT);
try {
m_future = bootstrap.bind(port).sync();//绑定监听端口,并同步等待启动完成
m_logger.info("start netty server!");
} catch (Exception e) {
m_logger.error("Started Netty Server Failed:" + port, e);
}
}启动netty,对每个客户端上报的消息都会做解码处理,从字节流转换为消息树MessageTree tree,接着交给DefaultMessageHandler处理。
public class DefaultMessageHandler extends ContainerHolder implements MessageHandler, LogEnabled {
/*
* MessageConsumer按每个period(整小时一个period)组合了多个解析器,用来解析生产多个报表(如:Transaction、
* Event、Problem等等)。一个解析器对象-一个有界队列-一个整小时时间组合了一个PeriodTask,轮询的处理这个有界队列中的消息
*/
@Inject
private MessageConsumer m_consumer;
private Logger m_logger;
@Override
public void enableLogging(Logger logger) {
m_logger = logger;
}
@Override
public void handle(MessageTree tree) {
if (m_consumer == null) {
m_consumer = lookup(MessageConsumer.class);//从容器中加载MessageConsumer实例
}
try {
m_consumer.consume(tree);//消息消费
} catch (Throwable e) {
m_logger.error("Error when consuming message in " + m_consumer + "! tree: " + tree, e);
}
}
}
OMS设计是按照每小时去汇总数据,为什么要使用一个小时的粒度呢?
这个是一个trade-off,实时内存数据处理的复杂度与内存的开销方面的折中方案。
在这个小时结束后将生成的Transaction\Event\Problean报表存入Mysql、File(机器根目录侠)。然而为了实时性,当前小时的报表是保存在内存中的。
PeriodManager 用来管理 OMS单位小时内的各种类型的解析器,包括将上报的客户端数据派发给不同的解析器(这种派发可以理解为订阅\发布)。每个解析器,将收到的消息存入内置队列,并且用单独的线程去获取消息并处理。
接下来我们继续看代码:
com.dianping.cat.analysis.PeriodManager
public class PeriodManager implements Task {
public void init() {
long startTime = m_strategy.next(System.currentTimeMillis());//当前小时的起始时间
startPeriod(startTime);
}
@Override
public void run() {
// 1s检查一下当前小时的Period对象是否需要创建(一般都是新的小时需要创建一个Period代表当前小时)
while (m_active) {
try {
long now = System.currentTimeMillis();
//value>0表示当前小时的Period不存在,需要创建一个
//如果当前线小时的Period存在,那么Value==0
long value = m_strategy.next(now);
if (value > 0) {
startPeriod(value);
} else if (value < 0) {
// //当这个小时结束后,会异步的调用endPeriod(..),将过期的Period对象移除,help GC
Threads.forGroup("cat").start(new EndTaskThread(-value));
}
} catch (Throwable e) {
Cat.logError(e);
}
try {
Thread.sleep(1000L);
} catch (InterruptedException e) {
break;
}
}
}
//当这个小时结束后,会异步的调用这个方法,将过期的Period对象移除,help GC
private void endPeriod(long startTime) {
int len = m_periods.size();
for (int i = 0; i < len; i++) {
Period period = m_periods.get(i);
if (period.isIn(startTime)) {
period.finish();
m_periods.remove(i);
break;
}
}
}
......
}
消息消费是由MessageConsumer的实现类RealtimeConsumer处理:
com…RealtimeConsumer.consume(MessageTree tree)
@Override
public void consume(MessageTree tree) {
String domain = tree.getDomain();
String ip = tree.getIpAddress();
if (!m_blackListManager.isBlack(domain, ip)) {// 全局黑名单 按domain-ip
long timestamp = tree.getMessage().getTimestamp();
//PeriodManager用来管理、启动periodTask,可以理解为每小时的解析器。
Period period = m_periodManager.findPeriod(timestamp);//根据消息产生的时间,查找这个小时所属的对应Period
if (period != null) {
period.distribute(tree);//将解码后的tree消息依次分发给所有类型解析器
} else {
m_serverStateManager.addNetworkTimeError(1);
}
} else {
m_black++;
if (m_black % CatConstants.SUCCESS_COUNT == 0) {
Cat.logEvent("Discard", domain);
}
}
}分发消息给各个解析器(类似向订阅者发布消息)
void com.dianping.cat.analysis.Period.distribute(MessageTree tree)
/**
* 将解码后的tree消息依次分发给所有类型解析器
* @param tree
*/
public void distribute(MessageTree tree) {
m_serverStateManager.addMessageTotal(tree.getDomain(), 1);// 根据domain,统计消息量
boolean success = true;
String domain = tree.getDomain();
for (Entry<String, List<PeriodTask>> entry : m_tasks.entrySet()) {
List<PeriodTask> tasks = entry.getValue();//某种类型报表的解析器
int length = tasks.size();
int index = 0;
boolean manyTasks = length > 1;
if (manyTasks) {
index = Math.abs(domain.hashCode()) % length;//hashCode的绝对值 % 长度 =0~length-1之间的任一个数
}
PeriodTask task = tasks.get(index);
boolean enqueue = task.enqueue(tree);//注意:这里会把同一个消息依依放入各个报表解析中的队列中
if (enqueue == false) {
if (manyTasks) {
task = tasks.get((index + 1) % length);
enqueue = task.enqueue(tree);//放入队列,异步消费
if (enqueue == false) {
success = false;
}
} else {
success = false;
}
}
}
if (!success) {
m_serverStateManager.addMessageTotalLoss(tree.getDomain(), 1);
}
}PeriodTask
每个periodTask对应一个线程,m_analyzer对应解析器处理m_queue中的消息
public class PeriodTask implements Task, LogEnabled {
@Override
public void run() {//每个periodTask对应一个线程,m_analyzer对应解析器处理m_queue中的消息
try {
m_analyzer.analyze(m_queue);
} catch (Exception e) {
Cat.logError(e);
}
}AbstractMessageAnalyzer

@Override
public void analyze(MessageQueue queue) {// 解析器在当前小时内自旋,不停从队列中拿取消息,然后处理
while (!isTimeout() && isActive()) {// timeOut:当前时间>小时的开始时间+一小时+三分钟;
// isActive默认为true,调用shutdown后为false
MessageTree tree = queue.poll();// 非阻塞式获取消息
if (tree != null) {
try {
process(tree);// 解析器实现类 override
} catch (Throwable e) {
m_errors++;
if (m_errors == 1 || m_errors % 10000 == 0) {
Cat.logError(e);
}
}
}
}
// 如果当前解析器以及超时,那么处理完对应队列内的消息后返回。
while (true) {
MessageTree tree = queue.poll();
if (tree != null) {
try {
process(tree);
} catch (Throwable e) {
m_errors++;
if (m_errors == 1 || m_errors % 10000 == 0) {
Cat.logError(e);
}
}
} else {
break;
}
}
}
所以我们可以看到:
消息发送到服务端,服务端解码为 MessageTree准备消费。期间存在一个demon线程,1s检查一下当前小时的Period对象是否需要创建(一般都是新的小时需要创建一个Period代表当前小时)。
如果当前小时的Period存在,那么我们的MessageTree会被分发给各个PeriodTask,这里其实就是把消息发送到每个PeriodTask中的内存队列里,然后每个Task异步去消费。就是通过使用Queue实现了解耦与延迟异步消费。
每个PeriodTask持有MessageAnalyzer analyzer(Transaction\Event\Problean…每种报表都对应一个解析器的实现类)、MessageQueue queue对象,PeriodTask会不停地解析被分发进来的MessageTree,形成这个解析器所代表的报表。
当前时间进入下个小时,会创建一个新的当前小时的Period,并且异步的remove之前的Period。
注意,这里有个比较坑的地方是,作者没有使用线程池,每小时各个解析器的线程并没有池化,而是直接销毁后再次创建!
展示
对于实时报表,直接通过HTTP请求分发到相应消费机,待结果返回后聚合展示(对分区数据做聚合);历史报表则直接取数据库并展示。
存储
存储主要分成两类:一个是 报表(Transaction、Event、Problem….),一个是logview,也是就是原始的MessageTree。
所有原始消息会先存储在本地文件系统,然后上传到HDFS中保存;而对于报表,因其远比原始日志小,则以K/V的方式保存在MySQL中。
报表存储:在每个小时结束后,将内存中的各个XML报表 保存到Mysql、File(\data\appdatas\cat\bucket\report…)中。

logView的保存有后台线程(默认20个,Daemon Thread [cat-Message-Gzip-n])轮询处理:会间隔一段时间后从消息队列中拿取MessageTree,并进行编码压缩,保存到\data\appdatas\cat\bucket\dump\年月\日\domain-ip1-ip2-ipn目录下。
com.dianping.cat.consumer.dump.LocalMessageBucketManager.MessageGzip.run()
@Override
public void run() {
try {
while (true) {
MessageItem item = m_messageQueue.poll(5, TimeUnit.MILLISECONDS);
if (item != null) {
m_count++;
if (m_count % (10000) == 0) {
gzipMessageWithMonitor(item);//数量达到10000的整数倍,通过上报埋点记录监控一下
} else {
gzipMessage(item);
}
}
}
} catch (InterruptedException e) {
// ignore it
}
}
private void gzipMessage(MessageItem item) {
try {
MessageId id = item.getMessageId();
String name = id.getDomain() + '-' + id.getIpAddress() + '-' + m_localIp;
String path = m_pathBuilder.getLogviewPath(new Date(id.getTimestamp()), name);
LocalMessageBucket bucket = m_buckets.get(path);
if (bucket == null) {
synchronized (m_buckets) {
bucket = m_buckets.get(path);
if (bucket == null) {
bucket = (LocalMessageBucket) lookup(MessageBucket.class, LocalMessageBucket.ID);
bucket.setBaseDir(m_baseDir);
bucket.initialize(path);
m_buckets.put(path, bucket);
}
}
}
DefaultMessageTree tree = (DefaultMessageTree) item.getTree();
ByteBuf buf = tree.getBuffer();
MessageBlock block = bucket.storeMessage(buf, id);
if (block != null) {
if (!m_messageBlocks.offer(block)) {
m_serverStateManager.addBlockLoss(1);
Cat.logEvent("DumpError", tree.getDomain());
}
}
} catch (Throwable e) {
Cat.logError(e);
}
}
public MessageBlock storeMessage(final ByteBuf buf, final MessageId id) throws IOException {
synchronized (this) {
int size = buf.readableBytes();
m_dirty.set(true);
m_lastAccessTime = System.currentTimeMillis();
m_blockSize += size;
m_block.addIndex(id.getIndex(), size);
buf.getBytes(0, m_out, size); // write buffer and compress it
if (m_blockSize >= MAX_BLOCK_SIZE) {
return flushBlock();
} else {
return null;
}
}
}logView的文件存储设计

接下来,会介绍CAT中出现的一些经典的设计、算法。
智能推荐

Mapreduce分布式处理
mapreduce Mapreduce是Hadoop的核心框架之一 举一个例子: 在期末考试完 系主任要求要总分数最高的学生的名字 一个系的学生有很多 如果把这麽多数据交给主任 主任需要很长时间才能找出最高的学生信息 如果让每个批改试卷的老师 报告出他们批改试卷的最高成绩 然后主任把数据合并出来 很快就找出成绩最高的学生 这样效率就很高 利用mapreduce 做wordcount步骤 1.首先需...
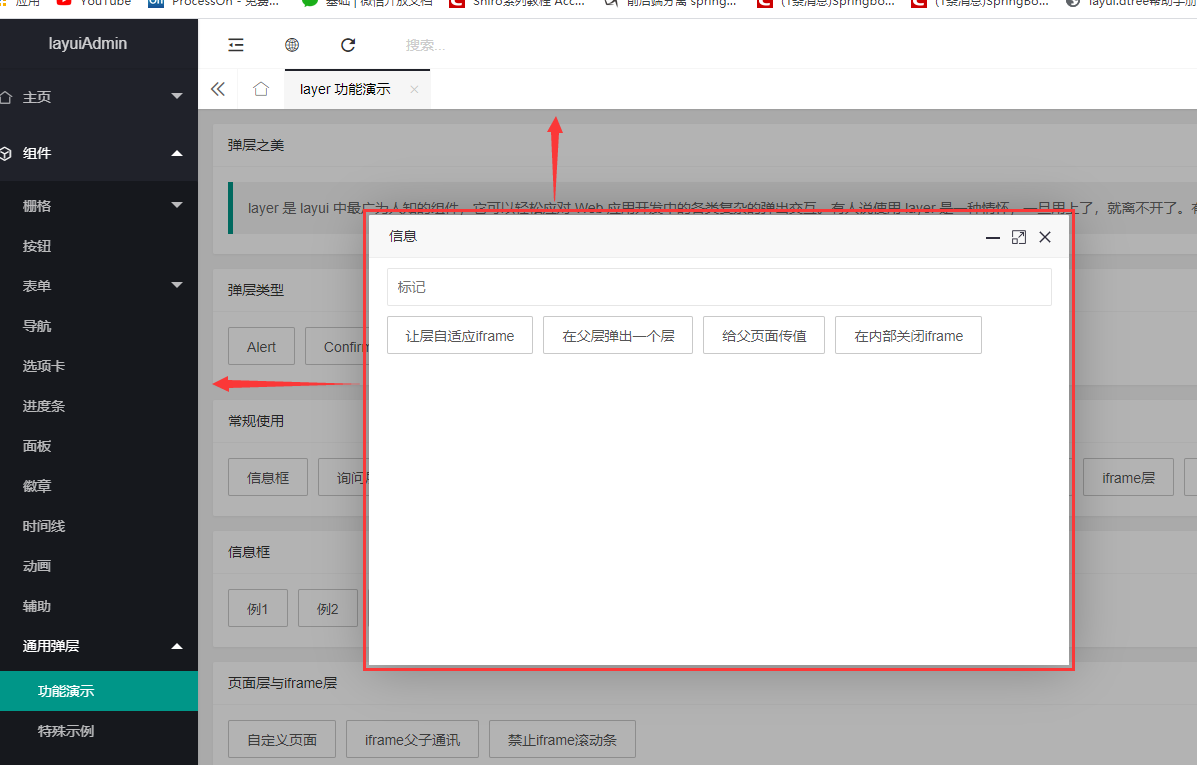
Layui parent.layui.open弹框之Iframe 传值处理
Layui open弹框获取值的方法 介绍:Layui 弹框之Iframe传值处理 我的想法 解决 子页面 获取 父页面方法以及元素。 上代码,看图片 原创作品,欢迎来讨论! 介绍:Layui 弹框之Iframe传值处理 本人在使用到layui的iframe版 ,里面使用到了弹框 。 普通弹框:layui.open(); 像这种传递值都没什么问题 , 子页面获取父页面值 或者父页面获取子页面值 全...
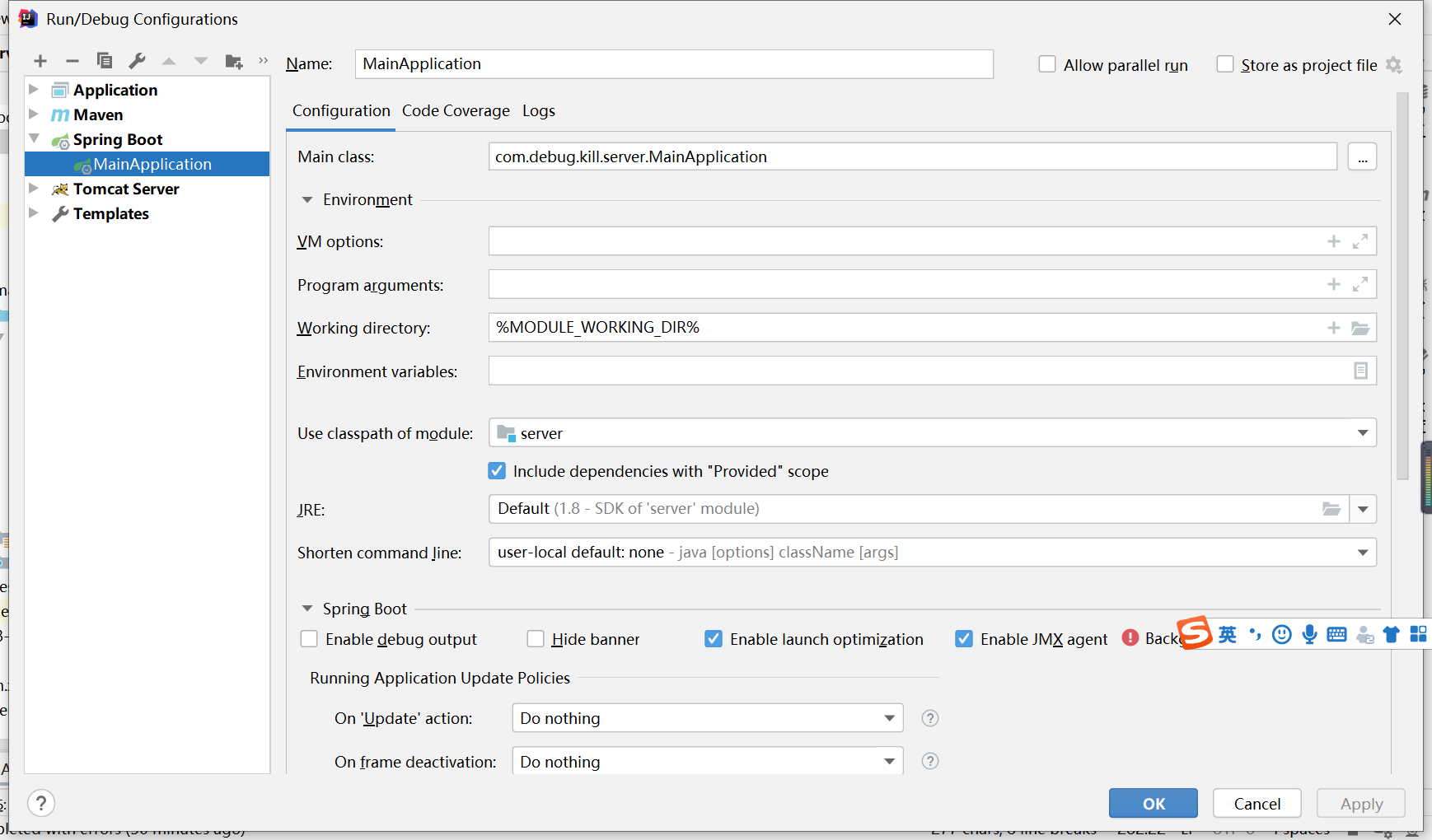
外置Tomcat无法使用devtools实现热部署
练手的项目每次有源码或者页面更新都需要重新启动,不能忍,热部署走一波 这个项目是用外置Tomcat启动的 项目层级目录 模块依赖关系:service 依赖于 model 依赖于 api (启动类在service模块中) 引入devTools依赖,确定相关idea配置无误后,发现热部署没有生效 得出结论: devTools无法对使用对外置的tomcat运行的项目生效 于是在网上搜索外置tomcat项...
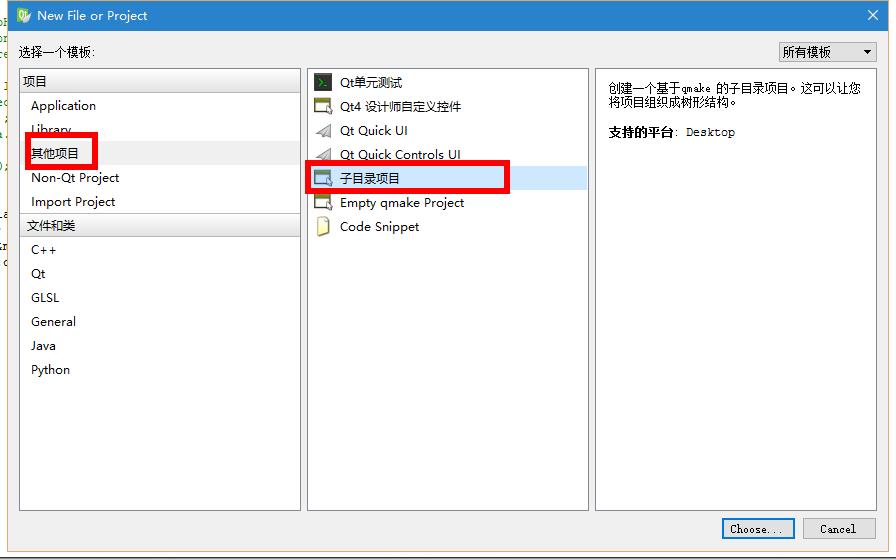
C++跨平台库QT学习7 使用UnitTest单元测试入门
C++跨平台库QT学习7 使用UnitTest单元测试入门 一、新建子目录项目 二、新建控制台项目 三、新建测试用例子目录项目 mycalctest.pro文件内容: 测试用例文件test_mycalctesttest.cpp 在子项目`mycalctest`点右键、运行 一、新建子目录项目 在QT点击菜单 文件-新建文件或项目-其他项目-子目录项目: 二、新建控制台项目 然后继续建一个子项目: ...
Python实用模块(二十五)loguru
软硬件环境 windows 10 64bits anaconda with python 3.7 loguru 0.5.3 前言 Python实用模块(十四)logging https://xugaoxiang.com/2019/12/04/python-module-logging 已 经介绍过了python内置日志模块logging。我们要使用logging,一般来讲,都是需要进行一...
猜你喜欢

Glide图片加载框架的使用简介与功能介绍
Glide图片加载框架的使用简介 . 1. 在app/build.gradle文件当中添加如下依赖: 2. 在AndroidManifest.xml中声明一下网络权限才行: 3. 开始使用Glide加载图片 with()方法的介绍 作用: 用于创建一个加载图片的实例;with()方法可以接收Context、Activity或者Fragment类型的参数 注意: with()方法中传入的实例会决定G...
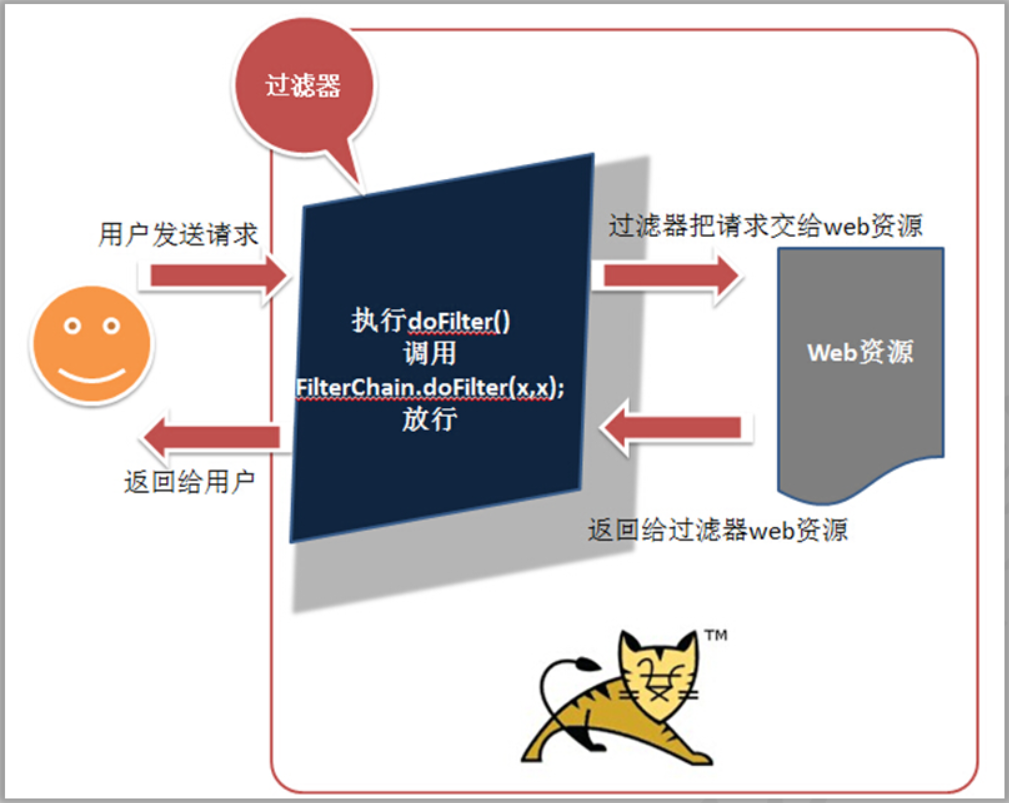
编写过滤器解决全局乱码问题
过滤器编写步骤 编写一个类实现javax.servlet.Filter接口 重写接口中所有的方法,其中doFilter方法执行过滤的功能 配置过滤器 在web.xml中配置 使用注解@WebFilter 解决乱码需要添加这句代码:req.setCharacterEncoding(“utf-8”); 字符集与网页的编码要一致 EncodingFilter.java: 过滤器的...
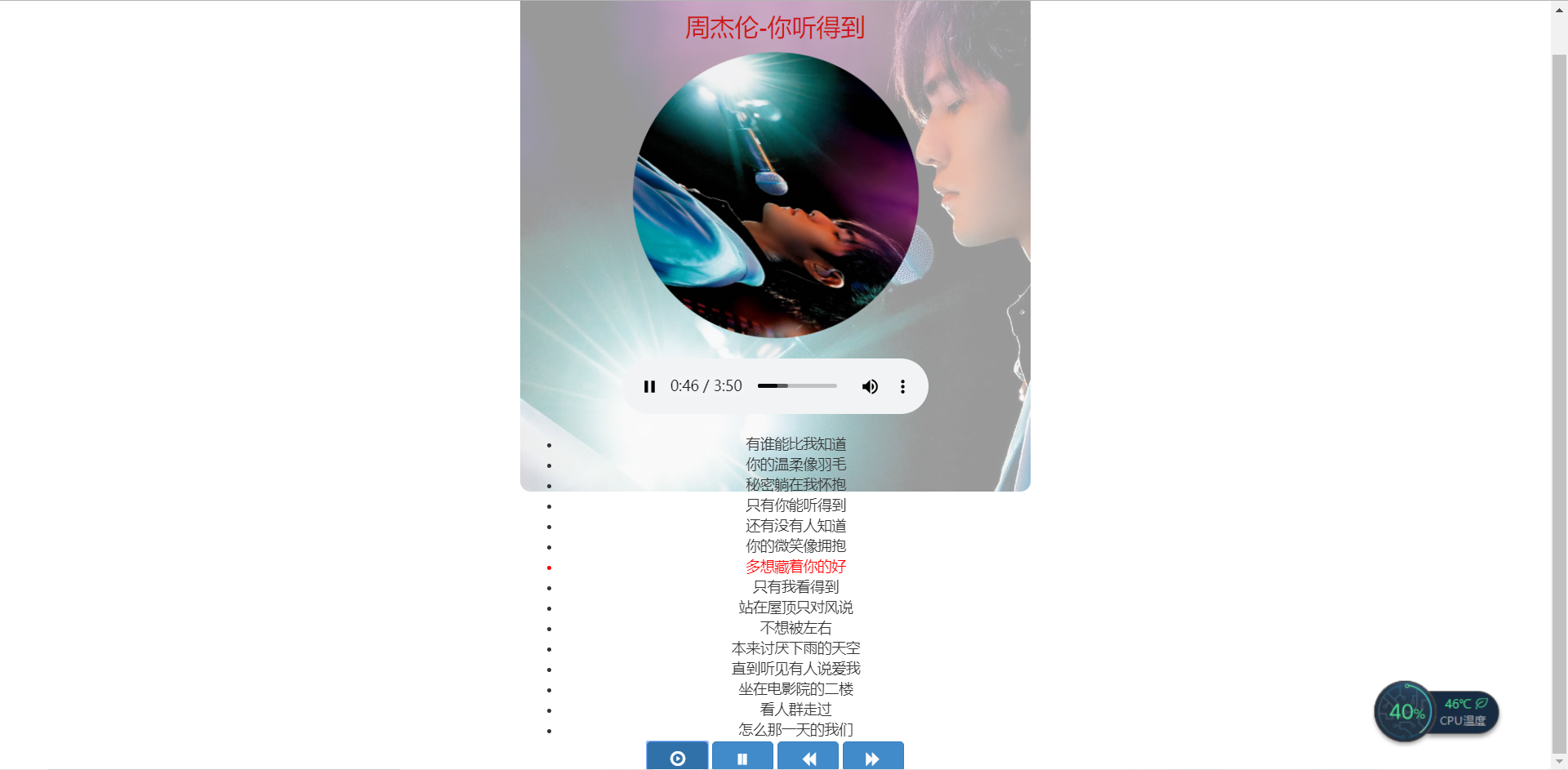
HTML+CSS+JS做一个简易音乐播放器
先给大家看下效果: 实现功能:音乐播放,歌词跟随进度滚动,中间随着音乐播放图片360度旋转 文件目录: 做一个播放器,音乐和歌词事先要下载好,搜一些自己喜欢的封面,让图片360度旋转的样式,通过按钮增删样式达到跟音乐同步进行: 其中歌词匹配才是让我头疼的,所有JS代码部分: 需要所有源码,可以去github上自行下载: https://github.com/lzs1996/MusicPlayer....
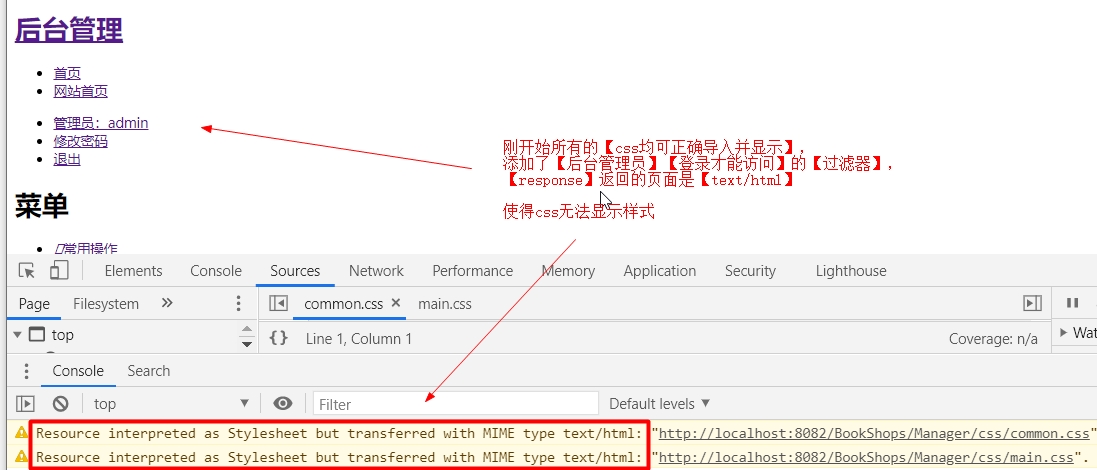
Ecplise(jsp文件)导入css文件路径没错,但是没有样式(不生效/无效)
一、检查css文件的【路径】是否正确 1、:将页面在【浏览器】打开,按【Ctrl+u】,查看【页面源代码】(也可右键点击) 若页面进行【跳转】------>说明css路径没错 二、若路径有问题 参考链接: 1、Jsp中引入css等外部文件路径问题 https://blog.csdn.net/prospective0821/article/details/79775626?utm_medium...

自定义View——仿支付宝支付弹窗界面
上面这个是采用自定view方式实现的一个仿支付宝支付弹窗的效果; 1、自定义view并初始化自定义属性 继承自EditText的话可以用使用EditText中的一些属性和方法,在初始化完自定义属性后要记得调用recycle()方法进行回收; 2、初始化画笔 在第三个构造函数中调用就可以了, 3、在onDraw()方法中进行绘制 在绘制的时候先要计算出一个密码所占的宽度 获取到一个密码的宽度后就可以...